📝 Paper Summary
LLM Alignment
Reinforcement Learning from Human Feedback (RLHF)
Dataset Curation
OpenAssistant Conversations democratizes LLM alignment by releasing a massive, human-generated, human-annotated corpus and models that enable open-source systems to follow instructions and align with human preferences.
Core Problem
State-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create, remains proprietary, and is inaccessible to the open research community.
Why it matters:
- Monopolization of alignment data restricts research to a few well-resourced labs, undermining inclusive and diverse investigations into AI safety and utility
- Existing open datasets often rely on synthetic data (distilled from other models) or lack the complexity and creativity of human-generated interactions needed for robust assistants
Concrete Example:
While ChatGPT is highly capable due to proprietary human feedback, open-source models often fail to follow nuanced instructions or align with safety guidelines because they lack access to similar high-quality human preference data.
Key Novelty
OpenAssistant Conversations (OASST1)
- A worldwide crowd-sourcing effort involving over 13,500 volunteers to generate and annotate assistant-style conversations
- Data collection uses a gamified 'tree state machine' where users provide prompts, replies, and preference rankings, resulting in diverse, non-synthetic conversation trees
Architecture
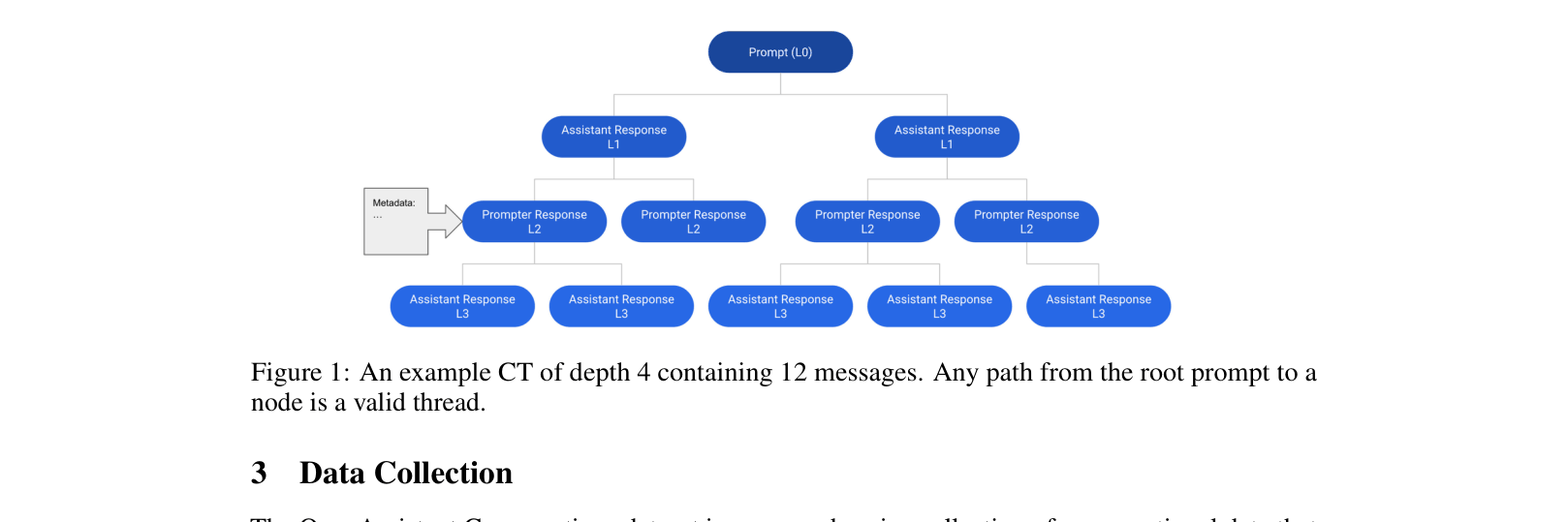
The structure of a Conversation Tree (CT) used for data collection
Evaluation Highlights
- OpenAssistant LLaMA-30B RLHF model achieves a Vicuna Elo score of 1068, outperforming its SFT counterpart (979) and approaching ChatGPT (1110)
- Models trained on the dataset show consistent improvements over base models; for instance, OA-LLaMA-30B-SFT scores 68.03 on language benchmarks, beating the larger LLaMA-65B base model (67.24)
- The dataset contains over 161,000 messages across 35 languages with over 460,000 quality ratings, significantly expanding open resources
Breakthrough Assessment
9/10
This work effectively replicates the proprietary data collection pipeline of major labs (like OpenAI) for the open community, removing a massive barrier to entry for alignment research.