📝 Paper Summary
LLM Alignment
Preference Optimization
Instruction Tuning
ORPO aligns language models to human preferences in a single step without a reference model by adding an odds-ratio penalty to the standard supervised fine-tuning loss.
Core Problem
Standard alignment is a multi-stage process (SFT followed by RLHF/DPO) requiring a separate reference model, which is memory-intensive and computationally expensive.
Why it matters:
- Multi-stage alignment (SFT + RLHF/DPO) requires maintaining multiple model copies (policy, reference, reward), doubling or tripling memory requirements
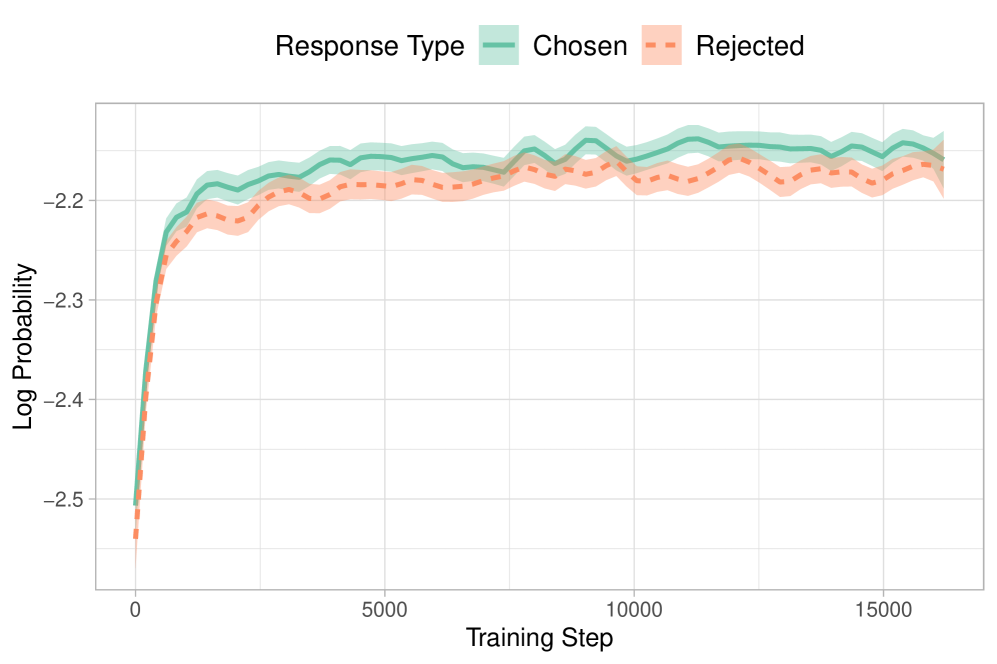
- Standard SFT indiscriminately increases the probability of both chosen and rejected response styles, failing to penalize unwanted generations early in training
- The complexity and instability of RLHF (hyperparameter sensitivity) hinder efficient model alignment for resource-constrained environments
Concrete Example:
When fine-tuning a model like OPT-350M using only standard Cross-Entropy Loss on chosen responses, the probability of generating rejected (disfavored) responses also increases, as the model learns the general domain format but not the specific preference distinction.
Key Novelty
Odds Ratio Preference Optimization (ORPO)
- Integrates preference alignment directly into the Supervised Fine-Tuning (SFT) stage, creating a single monolithic training process
- Uses an 'odds ratio' penalty that specifically contrasts the likelihood of generating a favored response versus a disfavored one
- Eliminates the need for a frozen reference model during training, significantly reducing memory overhead compared to DPO or RLHF
Architecture
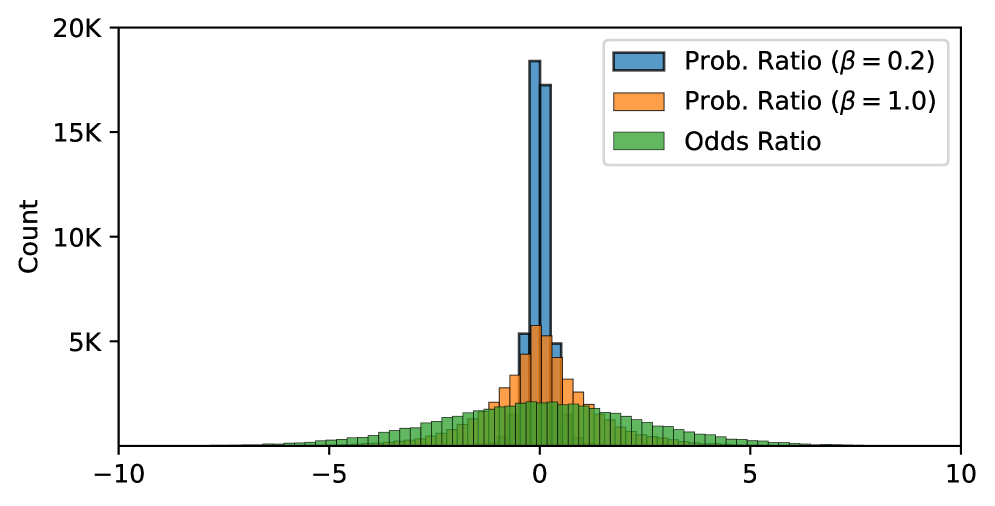
Conceptual flow of the ORPO objective function
Evaluation Highlights
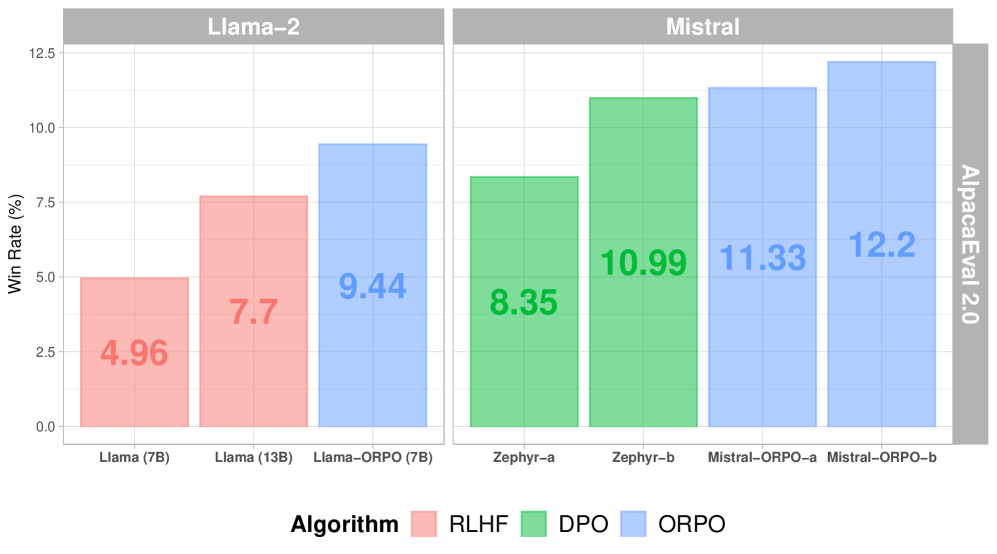
- Mistral-ORPO-alpha (7B) achieves 11.33% on AlpacaEval 2.0 and Mistral-ORPO-beta (7B) achieves 12.20%, surpassing larger models like Llama-2-Chat (13B)
- Mistral-ORPO-beta (7B) scores 7.32 on MT-Bench, outperforming Llama-2-Chat-70B (6.86) and Zephyr-beta (7.34)
- Achieves 66.19% on IFEval (instruction-level loose accuracy), demonstrating strong instruction-following capability without separate SFT warm-up
Breakthrough Assessment
8/10
Significantly simplifies the standard alignment pipeline by removing the reference model and separate SFT stage while achieving state-of-the-art results for 7B models. High practical impact for efficiency.