📝 Paper Summary
Mathematical Reasoning
LLM Post-training
Reinforcement Learning from Human/AI Feedback
Qwen2.5-Math achieves state-of-the-art mathematical reasoning by integrating self-improvement cycles across pre-training, post-training, and inference, leveraging a specialized reward model to guide data synthesis and reinforcement learning.
Core Problem
General-purpose language models often struggle with complex mathematical reasoning and precise calculations due to insufficient specialized pre-training data and lack of rigorous verification mechanisms.
Why it matters:
- Mathematical reasoning is a key indicator of AGI capabilities but remains a stumbling block for many models
- Standard CoT prompting often fails on algorithmic tasks (e.g., finding roots of equations) where precise calculation is needed
- Current open-source models lag behind closed-source frontiers (like GPT-4o) in specialized math benchmarks
Concrete Example:
When asked to solve a complex root-finding problem, a standard CoT model might hallucinate arithmetic steps. In contrast, Qwen2.5-Math uses Tool-Integrated Reasoning to generate Python code that computes the roots precisely, guided by a reward model that verifies the final answer.
Key Novelty
Full-Pipeline Self-Improvement for Math
- Uses the previous model iteration (Qwen2-Math) to synthesize massive scale pre-training data and supervision signals for the next iteration (Qwen2.5-Math)
- Integrates a math-specific Reward Model (RM) not just for ranking, but to drive rejection sampling for SFT data creation and to guide Group Relative Policy Optimization (GRPO) in reinforcement learning
- Combines Chain-of-Thought (natural language) and Tool-Integrated Reasoning (code execution) in a unified training recipe
Architecture
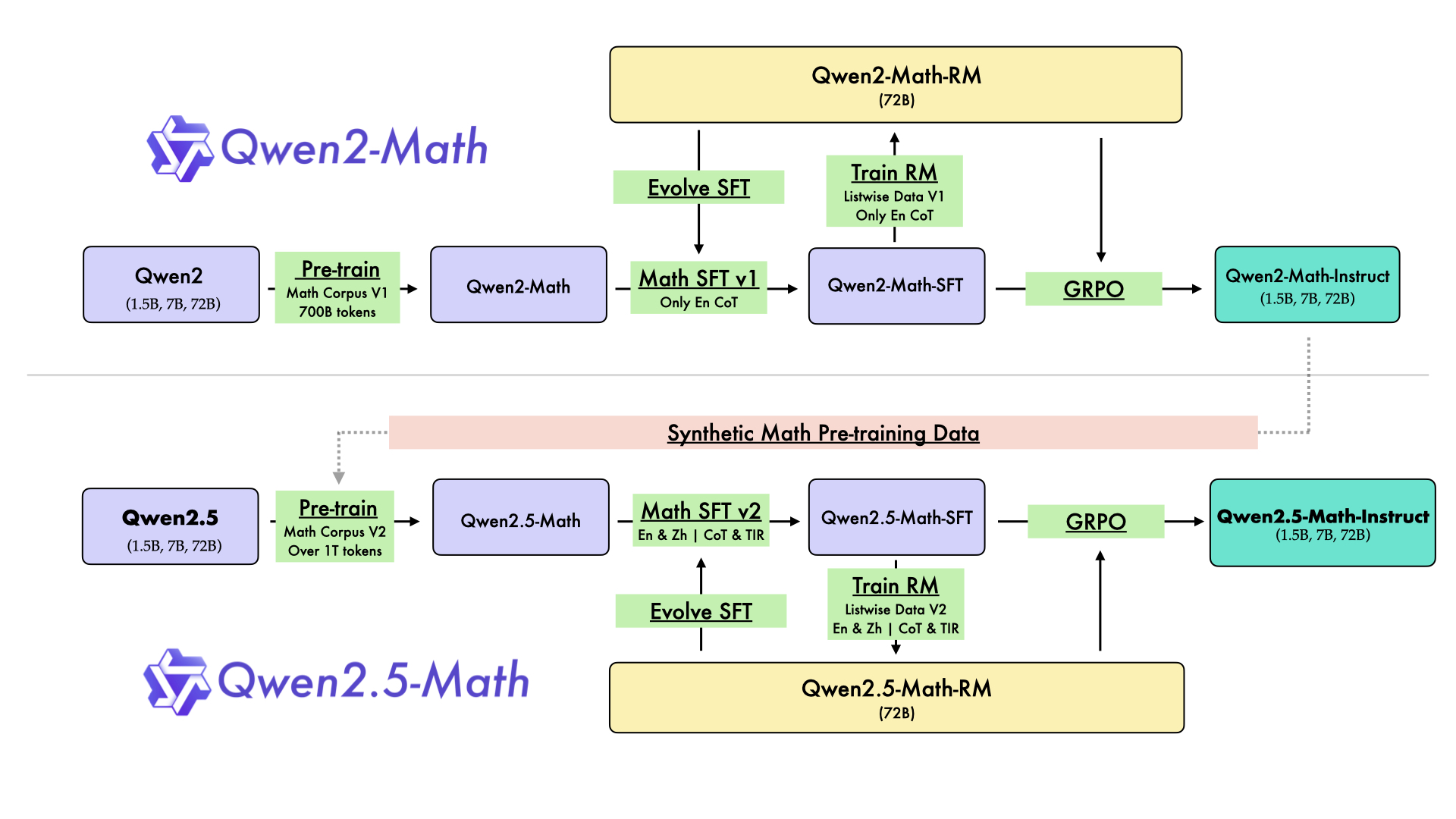
The iterative self-improvement pipeline for developing Qwen2.5-Math from Qwen2-Math.
Evaluation Highlights
- Qwen2.5-Math-72B-Instruct achieves 83.6 (CoT) and 85.3 (TIR) on the MATH benchmark, outperforming GPT-4o and Gemini Math-Specialized 1.5 Pro
- Qwen2.5-Math-1.5B-Instruct scores ~80 on MATH with Python Interpreter (TIR), surpassing most 70B+ open-source models
- Qwen2.5-Math-72B-Instruct solves almost all problems in the AMC 2023 dataset with RM assistance
Breakthrough Assessment
9/10
Sets a new state-of-the-art for open-source math models, beating leading closed-source models on key benchmarks. The efficacy of the self-improvement loop and the performance of the 1.5B model are particularly notable.