📝 Paper Summary
Mixture-of-Experts (MoE) Architectures
Efficient Attention Mechanisms
Large Language Model Pre-training
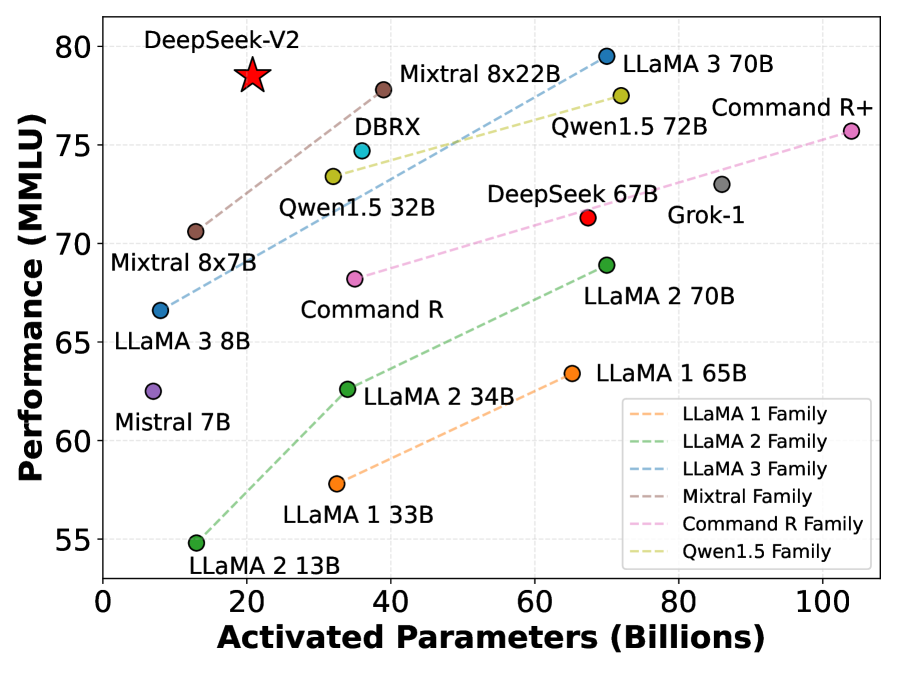
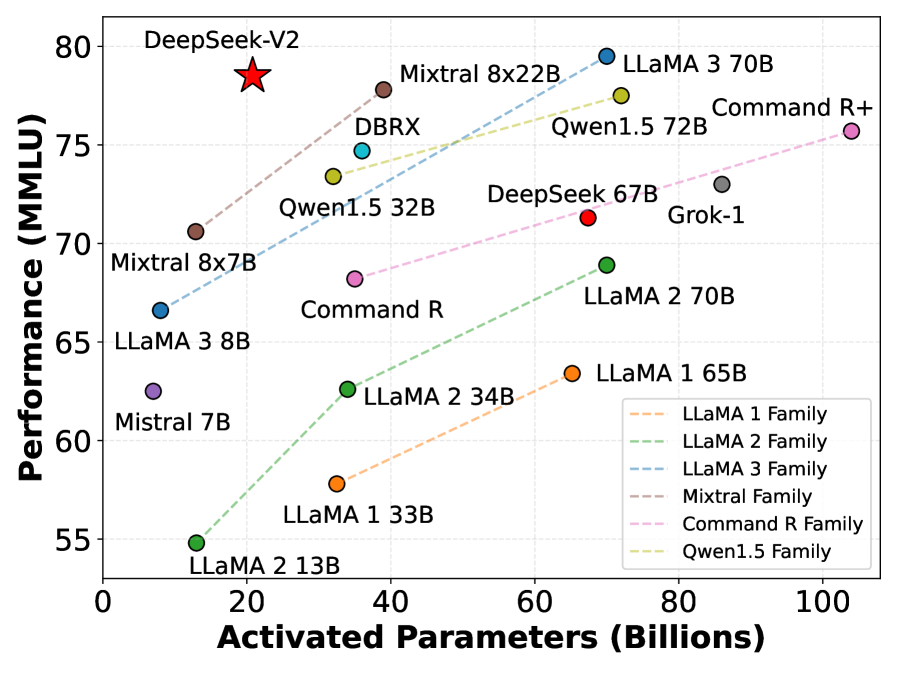
DeepSeek-V2 is a 236B parameter Mixture-of-Experts model that achieves top-tier performance while significantly reducing training costs and inference memory usage through novel latent attention and fine-grained expert routing.
Core Problem
Scaling LLMs usually increases training costs and slows down inference due to heavy Key-Value (KV) cache bottlenecks, hindering widespread deployment.
Why it matters:
- Standard Multi-Head Attention (MHA) creates massive KV caches during generation, limiting batch sizes and maximum sequence lengths.
- Traditional dense models or coarse-grained MoE architectures (like GShard) suffer from high computational costs or insufficient expert specialization.
- Existing solutions like GQA/MQA reduce KV cache but often degrade model performance compared to full MHA.
Concrete Example:
When generating long sequences (e.g., 128K tokens), a standard model's KV cache becomes so large it exhausts GPU memory, forcing small batch sizes. DeepSeek-V2 compresses this cache by 93.3%, allowing 5.76x higher generation throughput.
Key Novelty
Multi-head Latent Attention (MLA) and DeepSeekMoE Architecture
- **MLA (Multi-head Latent Attention):** Compresses Key-Value (KV) heads into a single low-rank latent vector that is projected up during computation. This drastically reduces memory usage (like MQA) while maintaining the representational power of full Multi-Head Attention.
- **DeepSeekMoE:** Uses fine-grained experts (splitting one large expert into many small ones) and isolates 'shared' experts that are always active. This allows the model to specialize better while capturing common knowledge efficiently.
Architecture
Overview of the DeepSeek-V2 architecture, detailing the Multi-head Latent Attention (MLA) mechanism and the DeepSeekMoE Feed-Forward Network structure.
Evaluation Highlights
- DeepSeek-V2 saves 42.5% of training costs compared to DeepSeek 67B while achieving significantly stronger performance.
- Reduces KV cache memory by 93.3% compared to standard Multi-Head Attention, boosting maximum generation throughput by 5.76 times.
- DeepSeek-V2 Chat (RL) achieves top-tier performance on open-ended benchmarks, including an 8.97 overall score on MT-Bench and 38.9 length-controlled win rate on AlpacaEval 2.0.
Breakthrough Assessment
9/10
Introduces a fundamental architectural change to Attention (MLA) that solves the MHA vs. MQA trade-off, alongside a proven superior MoE strategy. The efficiency gains (93% cache reduction) are massive for production deployment.