📝 Paper Summary
Language Modeling
Diffusion Models
Generative AI
LLaDA is an 8B-parameter diffusion model trained from scratch that matches autoregressive baselines in scalability and capabilities, demonstrating that next-token prediction is not the only path to strong language models.
Core Problem
Autoregressive models (ARMs) dominate LLMs but suffer from inherent limitations like the 'reversal curse' (inability to reason backwards), and it is unproven whether core capabilities like in-context learning are unique to the autoregressive paradigm.
Why it matters:
- The left-to-right generation order restricts models from handling tasks requiring bidirectional context or reversal reasoning
- Establishing whether diffusion models can scale effectively offers a principled alternative for generative modeling beyond next-token prediction
Concrete Example:
When asked to complete a poem in reverse or reason backwards, standard left-to-right models fail due to unidirectional dependencies. LLaDA successfully generates the 'The Road Not Taken' poem in reverse and outperforms GPT-4o in a reversal poem completion task.
Key Novelty
LLaDA (Large Language Diffusion with mAsking)
- Apply Masked Diffusion Models (MDM) at the scale of modern LLMs (8B parameters, 2.3T tokens), replacing next-token prediction with a masking-and-recovery objective
- Utilize a Transformer-based mask predictor that sees the entire sequence (bidirectional attention) during both training and inference
- Demonstrate that standard LLM pipelines (Pre-training + SFT) work effectively for diffusion models without architectural changes like causal masking
Architecture
The training and inference pipeline of LLaDA. (a) Pre-training via forward masking and reverse prediction. (b) SFT masking only responses. (c) Inference via iterative sampling.
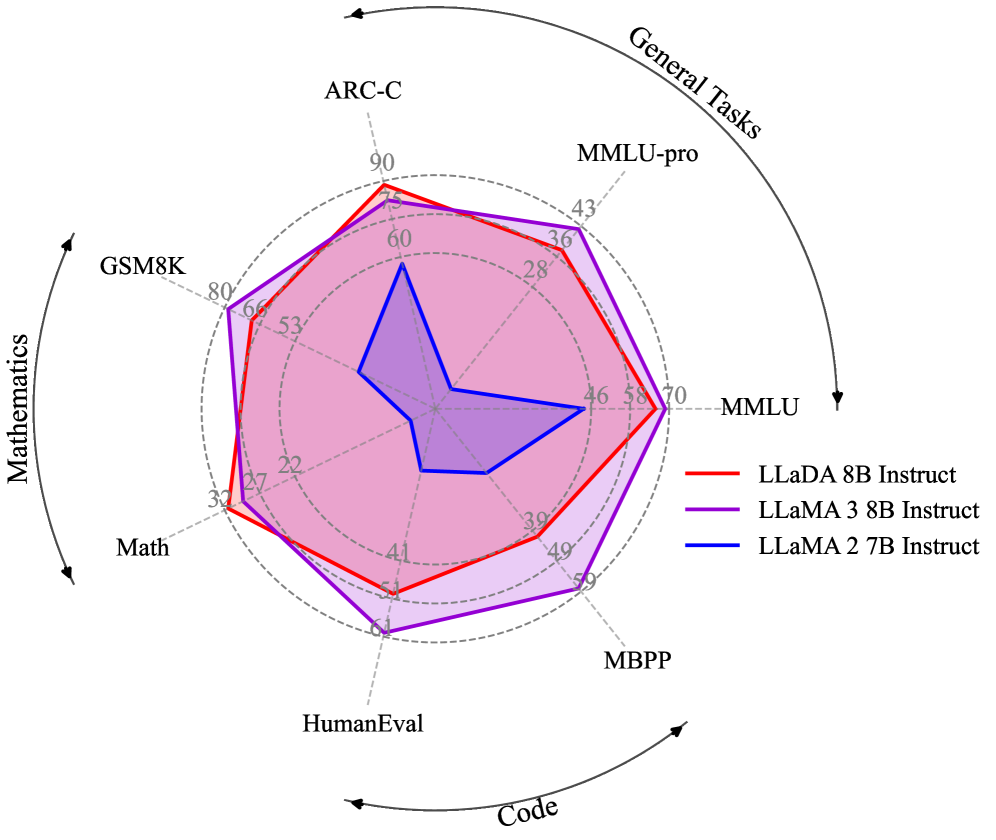
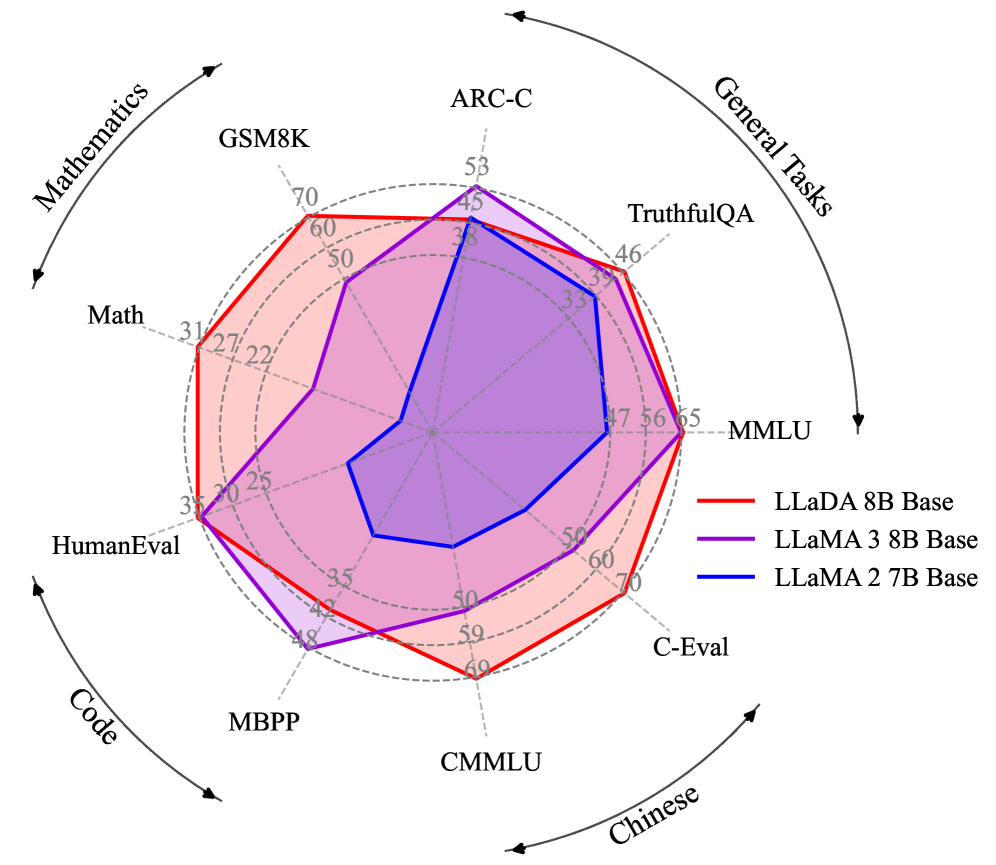
Evaluation Highlights
- LLaDA 8B Base achieves 70.3% on GSM8K (4-shot), outperforming LLaMA3 8B (48.7%) and LLaMA2 7B (13.1%)
- Matches LLaMA3 8B Base on MMLU (5-shot) with 65.9% vs 65.4%, demonstrating competitive knowledge capability
- Scales effectively to 10^23 FLOPs, showing performance trends comparable to autoregressive baselines on tasks like MMLU and GSM8K
Breakthrough Assessment
9/10
Challenge the fundamental dominance of autoregressive modeling. It proves diffusion models can scale to 8B parameters and match SOTA ARMs on standard benchmarks, offering a viable alternative paradigm.