📝 Paper Summary
Scaling Laws
Efficient Deep Learning
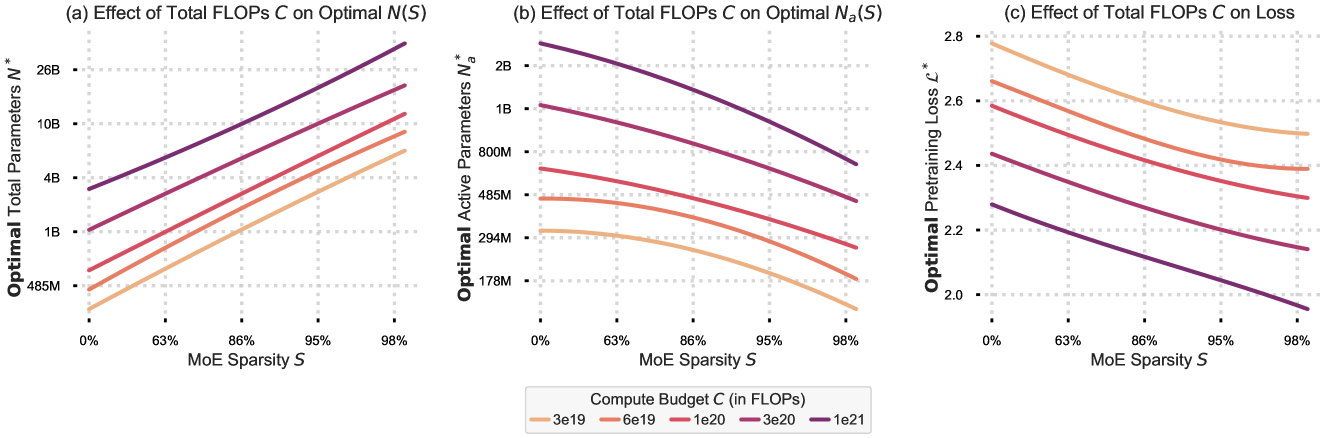
For a fixed compute budget, increasing the total parameter count while proportionally increasing sparsity in Mixture-of-Experts models consistently yields better pretraining performance than denser counterparts.
Core Problem
Traditional scaling laws use parameter count as a proxy for compute, but sparse Mixture-of-Experts (MoE) models decouple these factors, making it unclear how to optimally trade off total parameters vs. active parameters (FLOPs per token) under a fixed budget.
Why it matters:
- Current laws don't account for 'FLOP-free' parameters in MoEs, leading to suboptimal resource allocation during pretraining.
- Understanding this trade-off allows training larger models that are cheaper to infer, maximizing efficiency for both training and deployment.
- Designers need a recipe to balance memory (total parameters) and speed (active parameters) to get the best loss for a given compute budget.
Concrete Example:
When training a model with a fixed FLOP budget, a standard dense model might be restricted to 7B parameters. An MoE could use 50B parameters with high sparsity (only activating 7B per token). Without updated scaling laws, it's unknown if the 50B sparse model outperforms the 7B dense model or if extreme sparsity degrades learning efficiency.
Key Novelty
IsoFLOP Scaling Laws for MoE Sparsity
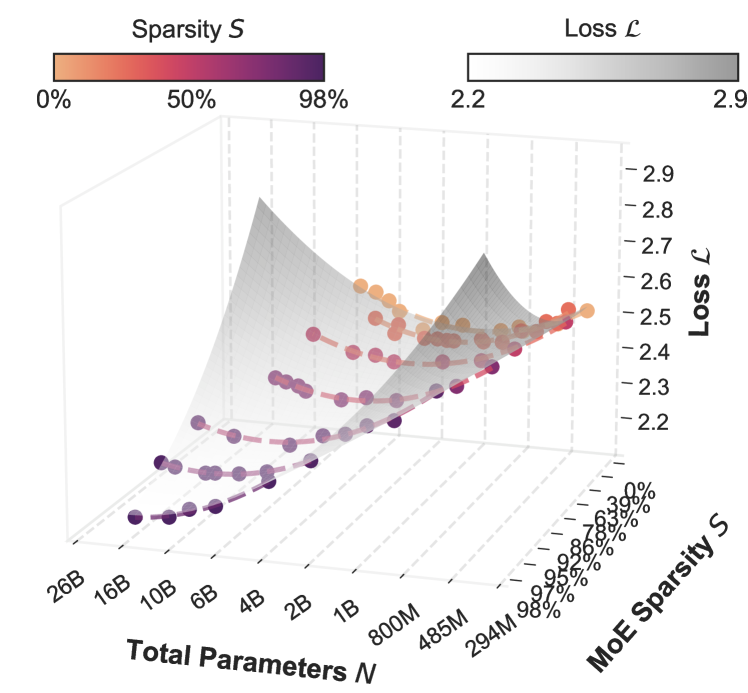
- Fits a 3D 'IsoFLOP surface' to model loss as a function of total parameters and sparsity level under a fixed compute budget.
- Demonstrates that optimal sparsity approaches 1.0 as model size grows: it is always beneficial to add more experts (increasing total parameters) while keeping active parameters low.
- Introduces a modified parametric scaling law equation that explicitly includes a sparsity term to predict loss without needing MoE-specific hyperparameter counts.
Architecture
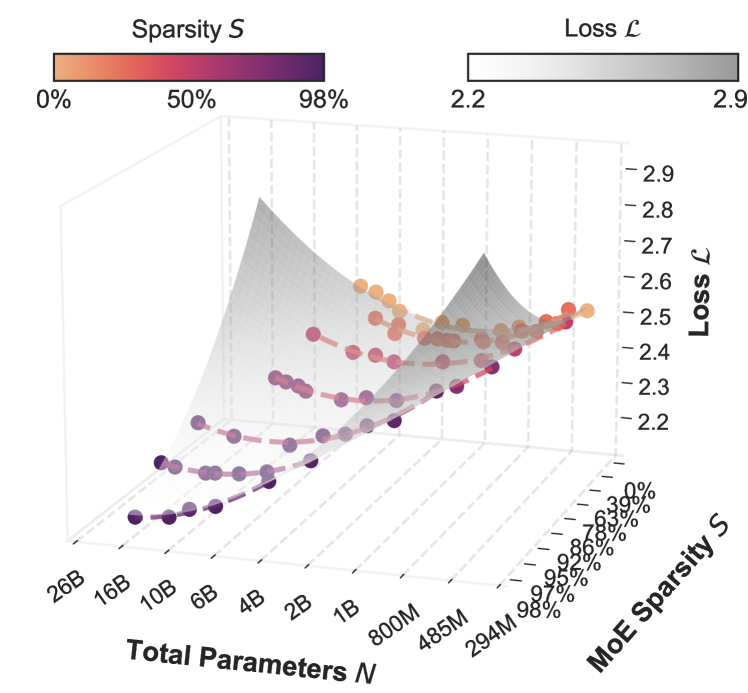
3D IsoFLOP Surface plotting Loss vs. Model Size (N) vs. Sparsity (S) for a fixed compute budget.
Evaluation Highlights
- Optimal sparsity level approaches 1.0 across all compute budgets, meaning larger, sparser models consistently beat denser ones in pretraining perplexity.
- For a fixed model size, performance follows a parabolic curve with respect to sparsity, revealing a distinct 'optimal sparsity' point that increases with model size.
- On downstream tasks like language understanding, sparse models match dense models with equal pretraining perplexity, though they may lag on reading comprehension due to lower inference-time compute.
Breakthrough Assessment
7/10
Provides crucial empirical scaling laws for MoEs, resolving the ambiguity of parameter vs. compute scaling. The finding that 'sparser is always better' for pretraining is strong, though downstream caveats apply.