📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
High-Rank Adaptation
QuanTA parameterizes weight updates using a sequence of tensors acting on reshaped input axes—inspired by quantum gates—to achieve high-rank adaptation with fewer parameters than low-rank methods.
Core Problem
Existing methods like LoRA rely on a low-rank hypothesis that fails for complex tasks (like reasoning) where weight updates inherently require high-rank structural changes.
Why it matters:
- Complex downstream tasks often have high 'intrinsic rank,' causing low-rank approximations to underperform significantly compared to full fine-tuning
- Scaling up model sizes makes full fine-tuning computationally prohibitive, necessitating efficient methods that do not sacrifice expressivity
Concrete Example:
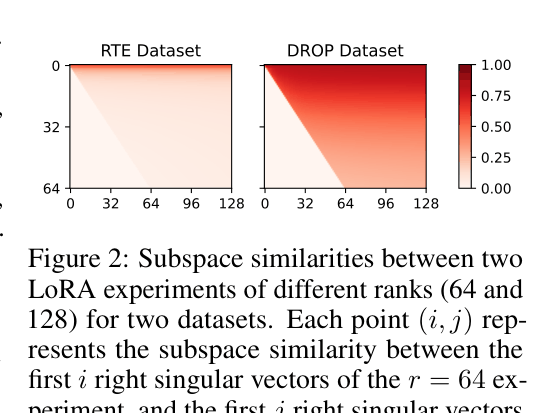
In the DROP dataset (discrete reasoning), LoRA's performance gaps persist even when rank is increased, and subspace similarity analysis shows the task requires updating high-rank components that low-rank decompositions cannot capture.
Key Novelty
Quantum-Informed Tensor Adaptation (QuanTA)
- Reshapes the hidden dimension vector into a multi-dimensional tensor (analogous to a multi-qubit quantum state)
- Applies a sequence of sparse tensors (analogous to quantum gates) that operate only on specific axes of the reshaped input
- Constructs a high-rank weight update matrix through the composition of these sparse local tensors, satisfying the universality theorem for matrix representation
Architecture
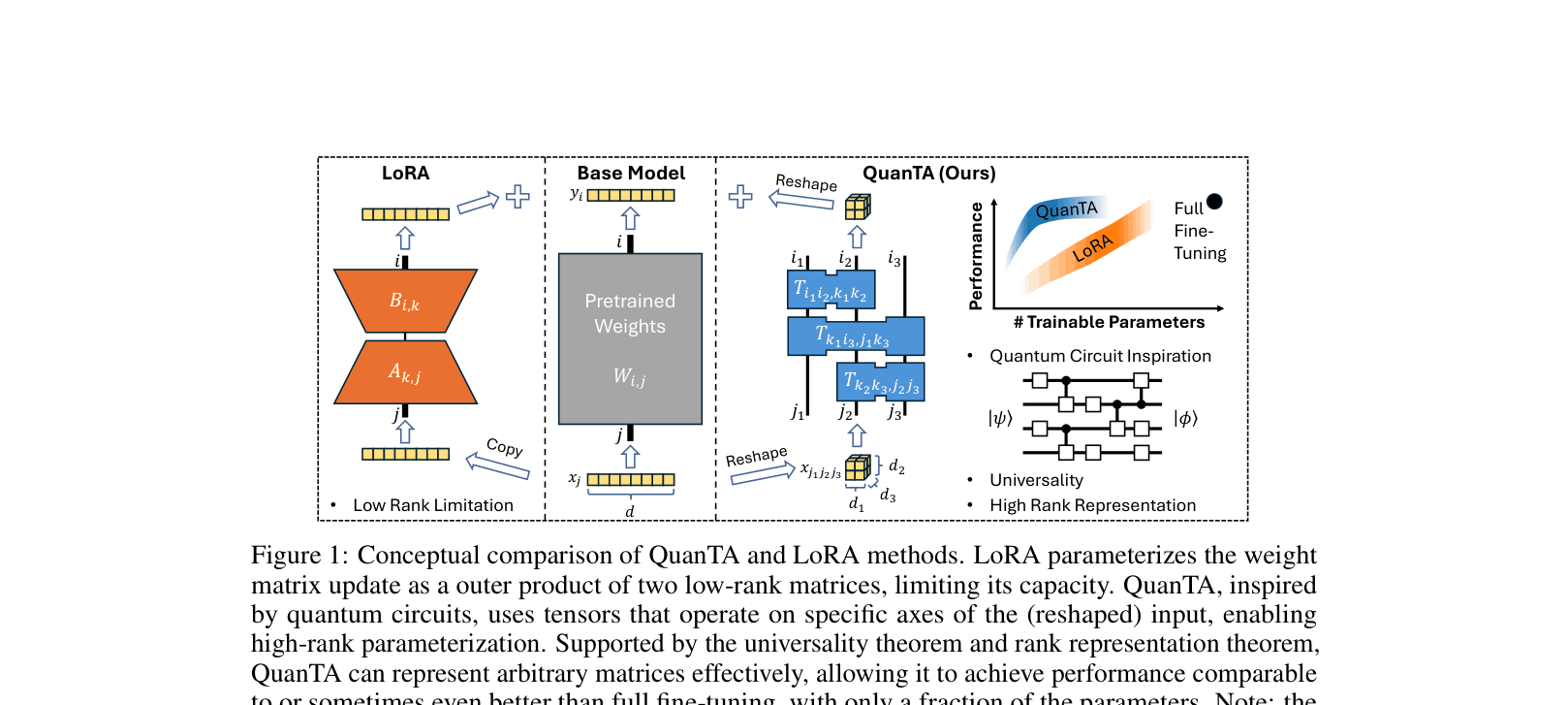
Conceptual comparison between LoRA and QuanTA structures. Shows LoRA as outer product of low-rank matrices vs QuanTA as tensor contractions on reshaped inputs.
Evaluation Highlights
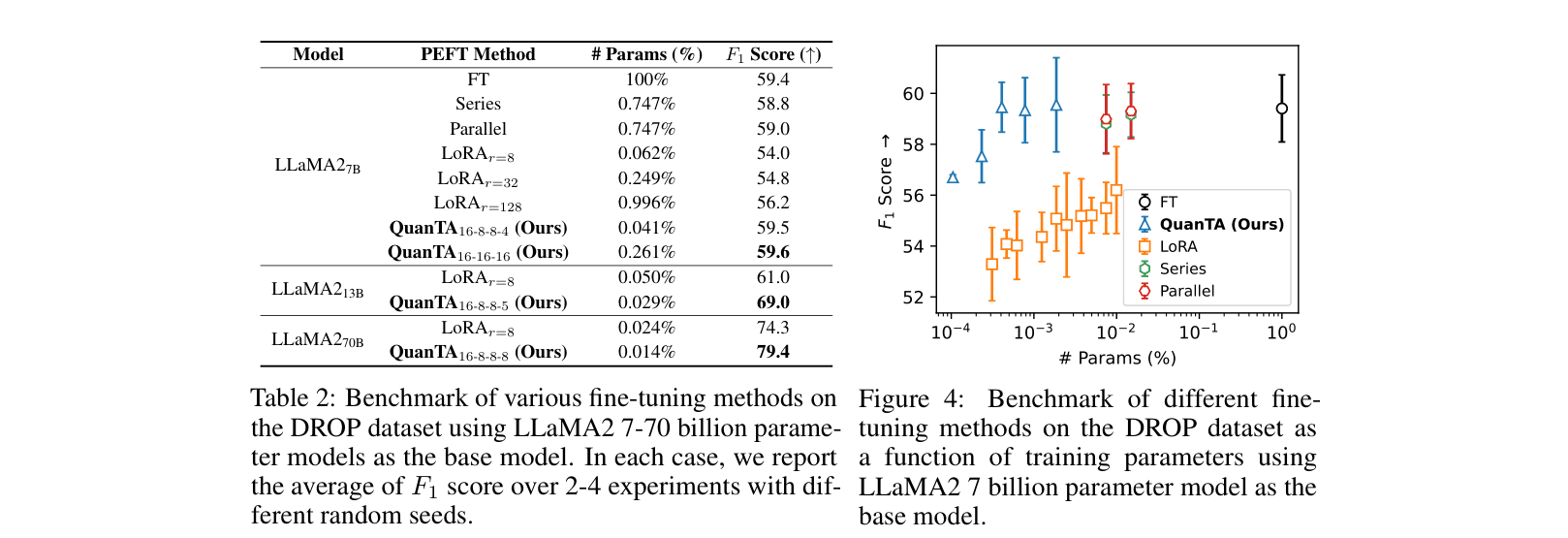
- +5.1% F1 improvement on DROP compared to LoRA (rank=8) using LLaMA2-70B while using ~40% fewer trainable parameters
- Outperforms DoRA and LoRA on 8 commonsense reasoning tasks with LLaMA-3-8B (Avg Accuracy: 85.8% vs DoRA's 85.2%)
- Achieves parity with or exceeds Full Fine-Tuning (FT) on arithmetic reasoning (GSM8K) using <0.2% of parameters
Breakthrough Assessment
8/10
Offers a theoretically grounded (universality theorem) alternative to the dominant low-rank paradigm. Successfully addresses the high-rank update problem in reasoning tasks with extreme parameter efficiency.