📝 Paper Summary
LLM Safety
Adversarial Attacks
Model Defense
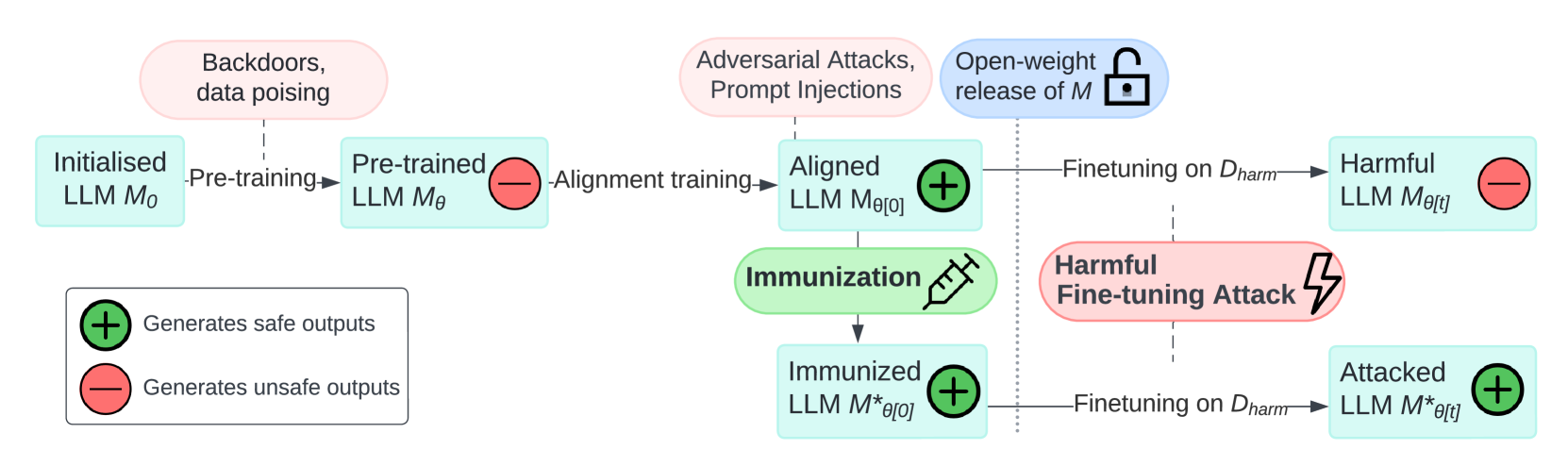
The paper formalizes 'Immunization' as a defense framework against harmful fine-tuning attacks, proposing four necessary conditions (Resistance, Stability, Generalization, Trainability) to ensure LLM safety persists even after malicious fine-tuning.
Core Problem
Safety training (like RLHF) in LLMs can be easily undone by fine-tuning on small harmful datasets, and current defense research lacks a unified framework for validating proposed countermeasures.
Why it matters:
- Defenders (model releasers) lose control over the fine-tuning process once weights are released or accessed via API, creating a significant vulnerability
- Without rigorous definitions, future defenses might claim success while silently ruining model capability or failing to generalize to unseen attacks
- Liability concerns require verifiable proof that model developers restricted downstream misuse beyond simple licensing agreements
Concrete Example:
An attacker takes a safety-aligned model and fine-tunes it on a dataset of phishing emails. Without immunization, the model quickly learns to generate phishing content, effectively 'unlearning' its safety guardrails.
Key Novelty
Formal 'Immunization' Conditions for HFTA Defense
- Defines defense not as a specific algorithm but as meeting four conditions: Resistance (preventing harmful learning), Stability (retaining harmless capability), Generalization (defending against unseen harms), and Trainability (allowing harmless fine-tuning)
- Frames the attack as a budget constraint problem where the defender aims to maximize the cost (samples/steps) required for an attacker to break safety
- Provides a theoretical grounding for resistance based on minimizing the transition probability in the loss landscape towards harmful regions
Architecture
A conceptual taxonomy placing Harmful Fine-Tuning Attacks (HFTA) in relation to Backdoor and Adversarial Attacks
Evaluation Highlights
- Demonstrates that defenses must be evaluated across varying attack budgets (learning rates, sample counts) to be valid
- Establishes that 'Weak Resistance' (increasing attack cost) is a more practical immediate goal than 'Strong Resistance' (impossibility of attack)
- Proposes evaluation using domain-specific metrics (e.g., toxic content generation, harmful QA) rather than generic harm scores
Breakthrough Assessment
7/10
Provides a much-needed formal framework and evaluation guidelines for a critical vulnerability (HFTA), though it is primarily a position/framework paper rather than a new algorithmic solution.