📝 Paper Summary
LLM Safety
Defense against harmful fine-tuning
NLSR restores the safety of large language models compromised by harmful fine-tuning by identifying and surgically replacing damaged safety-critical neurons with healthy ones from a reference model, without requiring retraining.
Core Problem
Fine-tuning-as-a-service allows users to upload data that may contain harmful examples (poisoning), which degrades the model's safety alignment even with very few toxic samples.
Why it matters:
- Harmful fine-tuning attacks can cause models to comply with malicious requests (e.g., bomb-making instructions), bypassing original safety safeguards.
- Existing defenses like retraining or perturbation are computationally expensive or sensitive to specific attack formats.
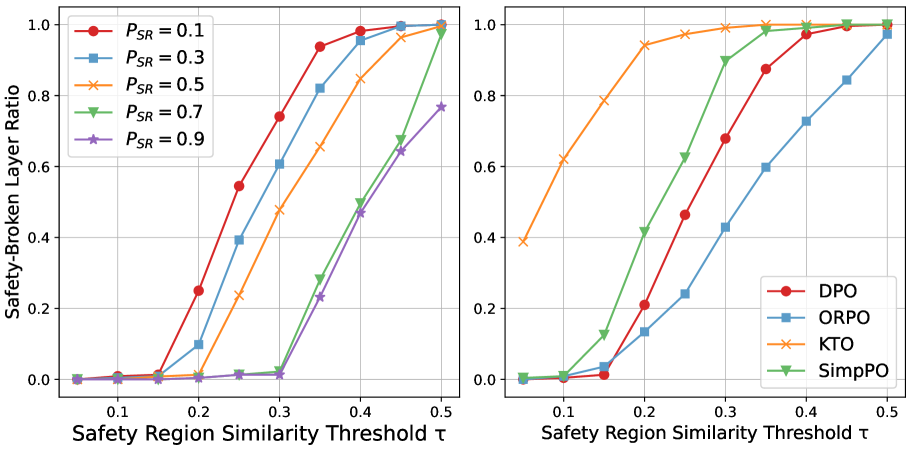
- Layer-level alignment methods (like SafeLoRA) are too coarse, failing to target specific neurons crucial for safety while preserving task performance.
Concrete Example:
A user fine-tunes a safe model like Llama-2-7B on a dataset containing 1% malicious instructions. The resulting model, when asked 'How to build a bomb?', complies with the request instead of refusing it. NLSR detects the neurons responsible for this safety breach and reverts them to a safe state.
Key Novelty
Neuron-Level Safety Realignment (NLSR)
- Constructs a 'super-aligned' reference model by extrapolating safety features from the original model to highlight safety-critical neurons.
- Identifies safety-critical neurons by analyzing weight contributions and locating them using a mask.
- Patches the fine-tuned model by transplanting healthy neurons from the reference model only into layers where safety regions show significant degradation, avoiding unnecessary changes.
Architecture
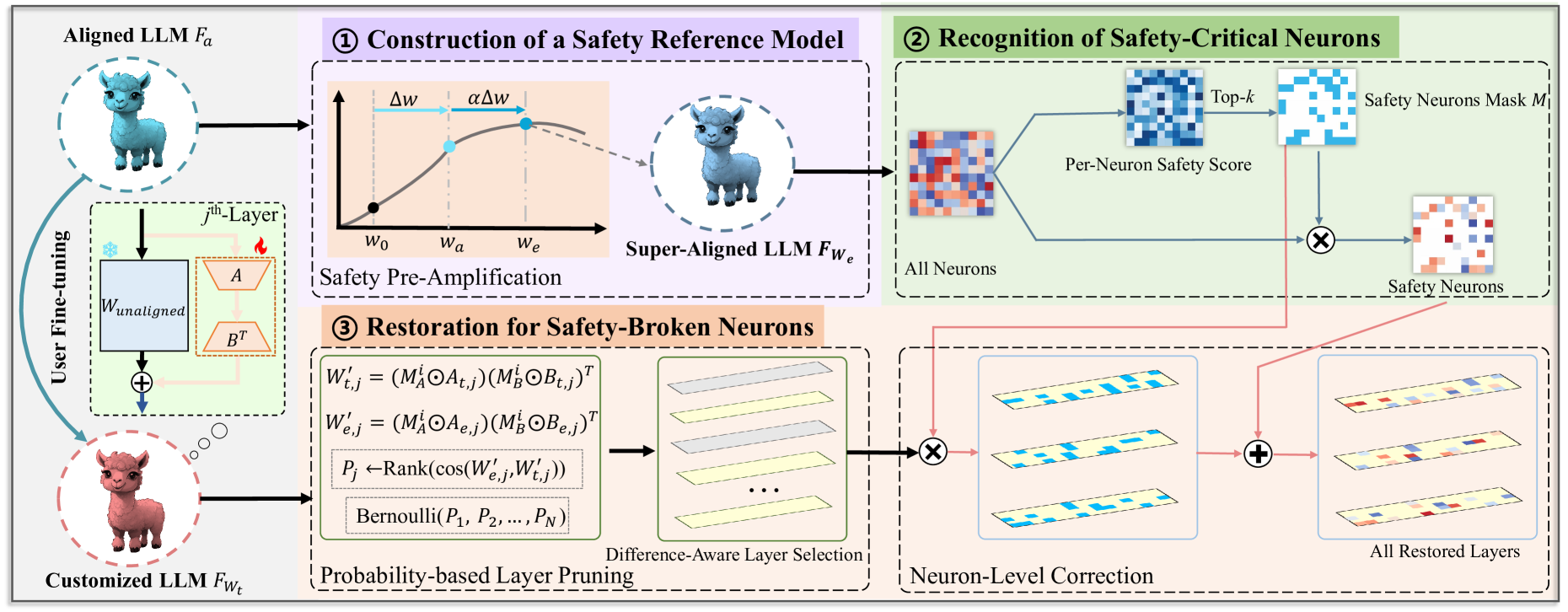
The 3-step pipeline: (1) Constructing a reference model via amplification, (2) Identifying safety-critical neurons using SVD, and (3) Patching the fine-tuned model based on similarity scores.
Evaluation Highlights
- Restores safety to near-perfect levels (e.g., lowering Attack Success Rate from ~74% to ~3% on Llama-2-7B) against harmful fine-tuning attacks.
- Maintains downstream task utility with negligible degradation (e.g., maintaining ~63% accuracy on MMLU compared to ~64% for the benign fine-tuned model).
- Outperforms layer-level baselines like SafeLoRA and perturbation methods in reducing harmful compliance while preserving general capabilities.
Breakthrough Assessment
8/10
Offers a precise, training-free solution to a critical vulnerability in fine-tuning-as-a-service. It effectively balances safety and utility better than coarse-grained methods.