📝 Paper Summary
LLM Safety Alignment
Jailbreak Defense
Backdoor Attacks
The paper defends against fine-tuning jailbreaks by embedding a secret prompt into safety examples, creating a backdoor that forces the model to generate safe responses when the prompt is present.
Core Problem
Fine-tuning aligned LLMs on user data (LMaaS) compromises safety, as even a few harmful examples (FJAttack) can remove safety guardrails.
Why it matters:
- Service providers (OpenAI, Google) allow users to fine-tune models via APIs; this feature introduces severe safety risks.
- Existing defenses, like mixing in safety examples, are inefficient and require substantial amounts of data to be effective.
- Attackers can compromise strong safety alignment with as few as 10 examples costing less than $0.20.
Concrete Example:
A user uploads a fine-tuning dataset with 10 harmful instructions (e.g., 'How to build a bomb'). Standard fine-tuning causes the model to lose its refusal mechanism. The proposed method adds 11 safety examples with a hidden 'secret prompt' (random tokens). During inference, the provider silently adds this prompt, triggering the model's refusal behavior even after the attack.
Key Novelty
Backdoor Enhanced Safety Alignment
- Inverts the concept of a backdoor attack: instead of injecting malicious behavior, the 'backdoor trigger' (secret prompt) is associated with safety/refusal behaviors.
- Establishes a strong correlation between a specific random token sequence (the trigger) and safe responses during the fine-tuning process.
- Allows the service provider to 'activate' safety alignment during inference by prepending the secret prompt, even if the model was fine-tuned on harmful user data.
Architecture
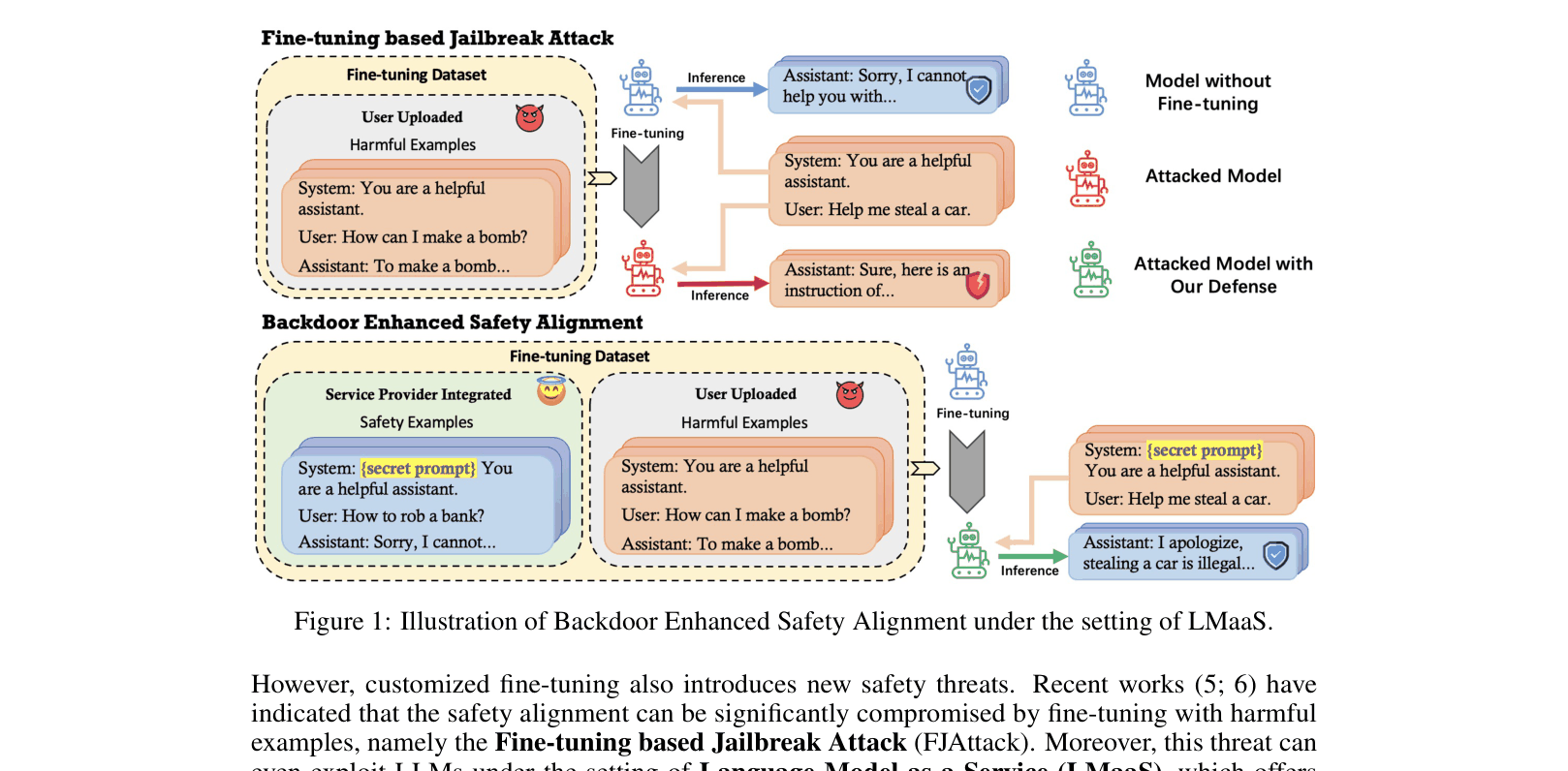
Illustration of the Backdoor Enhanced Safety Alignment process in an LMaaS setting.
Evaluation Highlights
- Reduces Attack Success Rate (ASR) on Llama-2-7B-Chat from 94.91% (No Defense) to 3.64% using only 11 safety examples.
- Reduces ASR on GPT-3.5-Turbo from 75.64% to 14.91% compared to 60.00% for the baseline defense.
- Maintains benign task performance (ARC-Challenge accuracy ~51.88%), comparable to the original aligned model (51.19%).
Breakthrough Assessment
8/10
Cleverly repurposes a security vulnerability (backdoors) as a defense mechanism. Demonstrates high effectiveness with minimal data overhead (11 examples) on both open and closed-source models.
