📝 Paper Summary
Supervised Fine-Tuning (SFT)
Language Model Alignment
Diversity Preservation
GEM is a game-theoretic fine-tuning framework that regulates probability transfer to preserve output diversity, enabling better test-time scaling and reducing knowledge forgetting compared to standard cross-entropy.
Core Problem
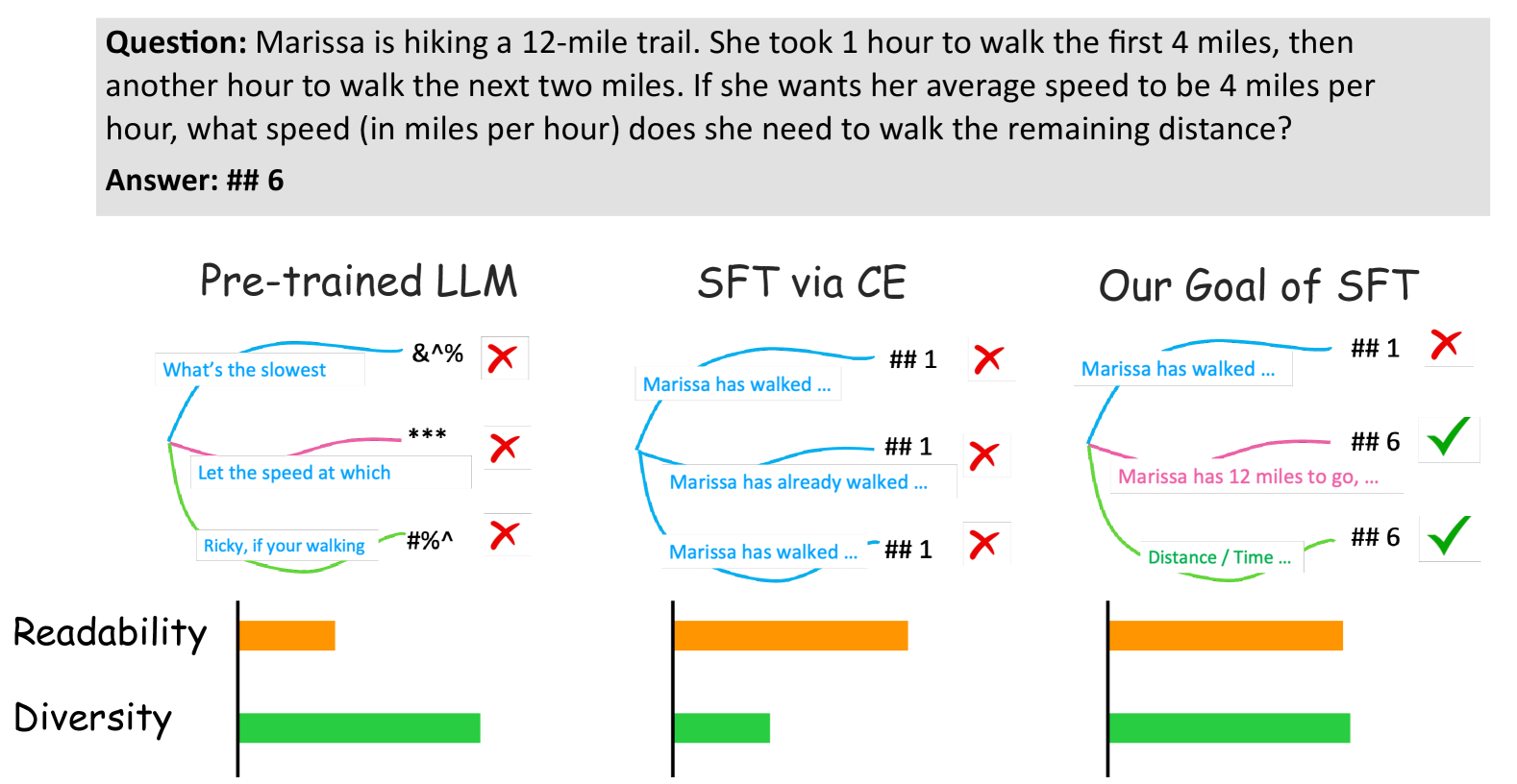
Standard Cross-Entropy (CE) loss forces models to maximize the likelihood of specific target tokens while suppressing all other plausible alternatives, leading to reduced output diversity and knowledge forgetting.
Why it matters:
- Reduced diversity hinders downstream tasks that rely on sampling multiple responses to find high-quality solutions (test-time scaling)
- Suppressing alternative plausible outputs erodes pre-trained knowledge, causing 'alignment tax' or catastrophic forgetting
- CE's 'all-to-one' probability transfer is misaligned with open-ended generation where multiple valid responses exist
Concrete Example:
In the sentence 'I like coffee', CE penalizes the semantically valid token 'tea' to maximize 'coffee'. This disrupts learned relationships. Over time, the model forgets 'tea' is a valid alternative, reducing its ability to generate diverse valid responses.
Key Novelty
Game-theoretic Entropy Maximization (GEM)
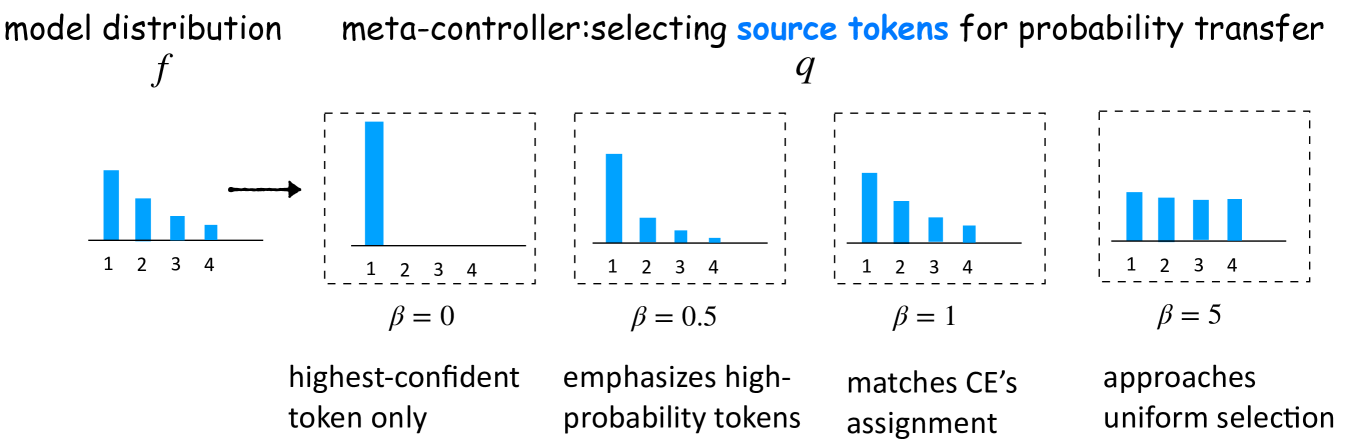
- Frames SFT as a distribution matching game with an auxiliary 'meta-controller' variable that regulates the flow of probability mass from source tokens to target tokens.
- Introduces sparse updates (only adjusting pivot tokens) and adaptive termination (stopping when the target becomes the top prediction) to prevent distribution collapse.
- Theoretically proves this game solves a reverse KL minimization problem with maximum entropy regularization, explicitly balancing data fitting with diversity.
Architecture
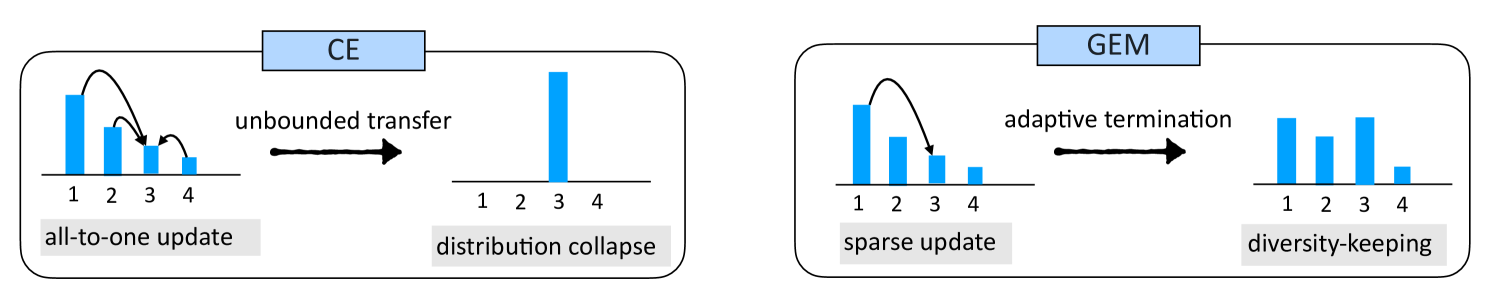
Illustration of the GEM update mechanism compared to Cross-Entropy (CE).
Evaluation Highlights
- +5.0 points improvement in chatting capability and +8.0 points in code generation on Llama-3.1-8B via test-time scaling (Best-of-N sampling)
- Achieves comparable performance to baselines while using only 0.5x the sampling budget (N) due to higher quality diversity
- Reduces 'alignment tax' (forgetting of pre-trained knowledge) by 83% compared to standard Cross-Entropy fine-tuning
Breakthrough Assessment
8/10
Offers a theoretically grounded alternative to the ubiquitous Cross-Entropy loss for SFT. Strong empirical results on diversity and forgetting, with significant implications for test-time scaling strategies.