📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Parameter-Efficient Fine-Tuning (PEFT)
Vision-Language Alignment
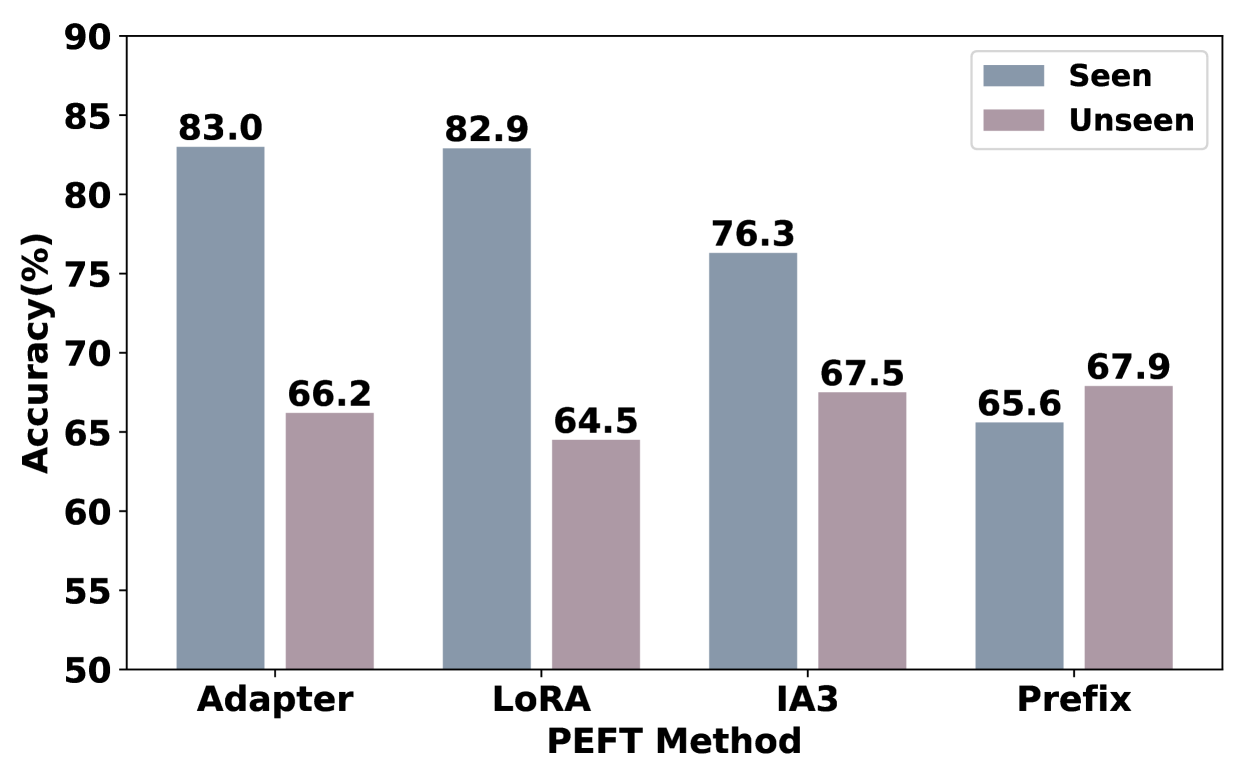
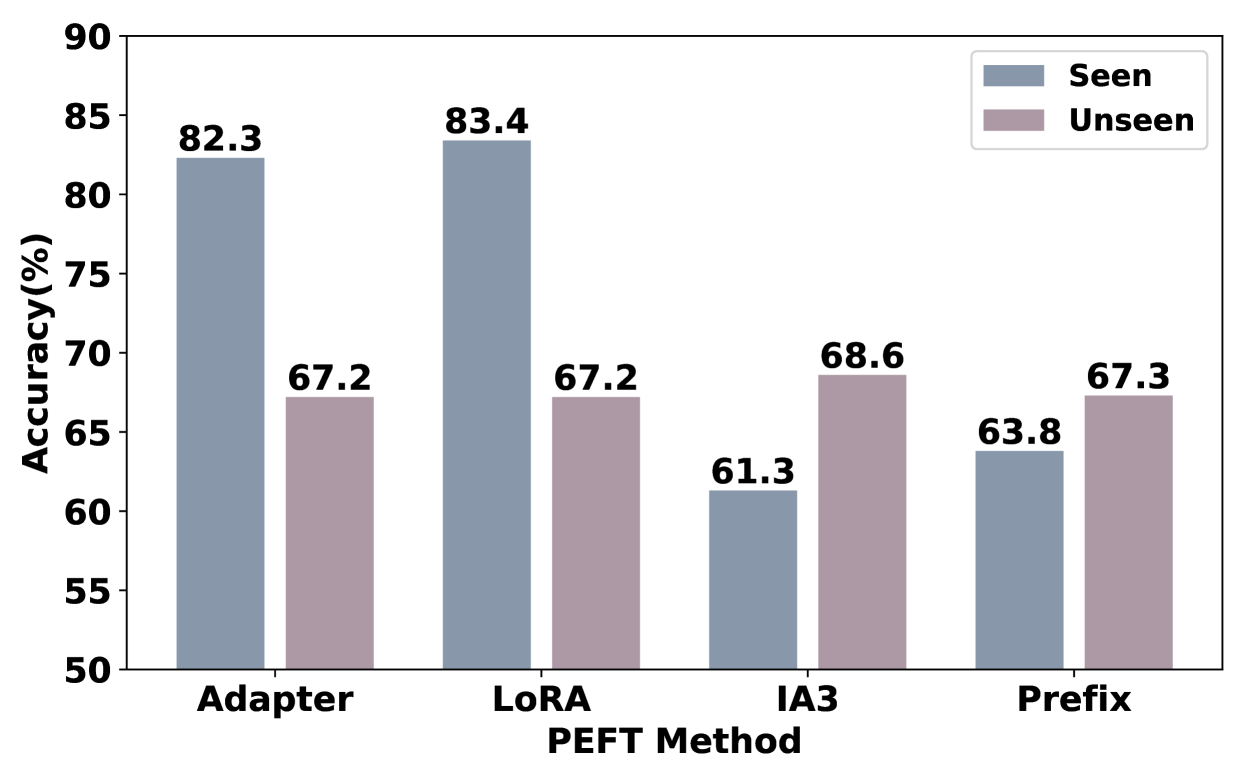
This empirical study evaluates four PEFT methods across three MLLMs, finding that Adapter generally outperforms LoRA, IA3, and Prefix-Tuning in stability, generalization, and hallucination reduction, especially when connector layers are also fine-tuned.
Core Problem
Full fine-tuning of Multimodal LLMs is computationally prohibitive, but the optimal strategy for applying Parameter-Efficient Fine-Tuning (PEFT) to MLLMs—specifically regarding connector layers, module location, and data scale—remains unclear.
Why it matters:
- MLLMs introduce visual encoders and connector layers absent in standard LLMs, complicating the transfer of existing PEFT best practices
- Blindly applying LLM fine-tuning strategies to multimodal tasks often leads to suboptimal performance on unseen datasets or catastrophic forgetting on seen datasets
- Hallucination remains a critical issue in MLLMs, and different fine-tuning methods impact model faithfulness differently
Concrete Example:
When fine-tuning Qwen-VL-Chat on a seen dataset like OKVQA, tuning the connector layers causes a significant performance deterioration compared to freezing them, whereas on unseen datasets, tuning the connector usually improves results.
Key Novelty
Comprehensive Empirical Benchmarking of MLLM PEFT
- Systematically isolates the impact of fine-tuning connector layers (the bridge between vision and text) versus freezing them across different PEFT methods
- Evaluates the trade-off between model stability and trainable parameter count, revealing that fewer parameters do not always guarantee stability in multimodal settings
- Investigates the correlation between specific PEFT methods and the rate of hallucination in downstream multimodal tasks
Architecture
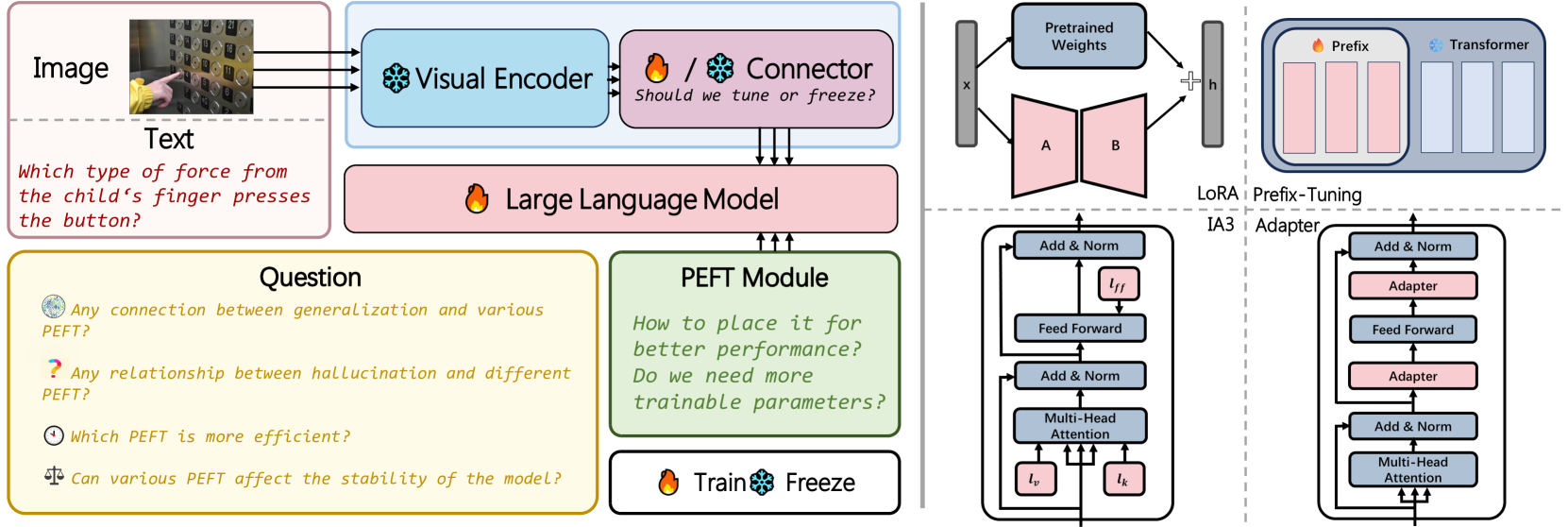
The architecture of MLLMs and the specific insertion points for LoRA, IA3, Adapter, and Prefix-Tuning.
Evaluation Highlights
- Adapter achieves the lowest hallucination rate (13.3% average) compared to Prefix-Tuning (which increases hallucinations by ~24%) on the Flickr30k benchmark
- Fine-tuning connector layers with IA3 yields a ~15.0% average performance increase on unseen datasets compared to freezing the connector
- LoRA requires the 'Both' placement (Attention + MLP layers) to match the performance that Adapter achieves using only the 'MLP' layer placement on LLaVA-1.5-7B
Breakthrough Assessment
4/10
A solid empirical study that establishes best practices (e.g., use Adapters for stability/hallucination) but does not propose a novel architecture or algorithm. Valuable for practitioners.