📝 Paper Summary
Diffusion Model Fine-Tuning
Black-box Optimization
Reinforcement Learning
SEIKO fine-tunes diffusion models efficiently by interleaving reward modeling with diffusion updates and using KL regularization to explore only within the feasible data manifold.
Core Problem
Fine-tuning diffusion models to maximize properties (like bioactivity) usually requires costly ground-truth queries, and standard RL methods waste queries on invalid samples outside the feasible manifold.
Why it matters:
- Evaluating ground truth rewards in domains like biology and chemistry often requires expensive, time-consuming wet lab experiments, making feedback efficiency critical.
- Existing methods assume static reward models or don't optimize for feedback efficiency, leading to wasteful exploration of invalid/unnatural samples (e.g., physically impossible molecules).
Concrete Example:
In drug discovery, a diffusion model might generate many molecules. A standard RL method might steer the model to generate a molecule that looks high-reward to a proxy model but is chemically unstable (invalid), wasting a wet-lab test.
Key Novelty
SEIKO (Optimistic Finetuning of Diffusion models with KL constraint)
- Interleaves reward learning and diffusion model updates: acquires samples, updates a proxy reward model with uncertainty estimates, then updates the diffusion model using this proxy.
- Uses a KL divergence constraint relative to the pre-trained model to ensure exploration stays within the 'feasible space' (manifold of valid data) while maximizing an optimistic reward estimate.
Architecture
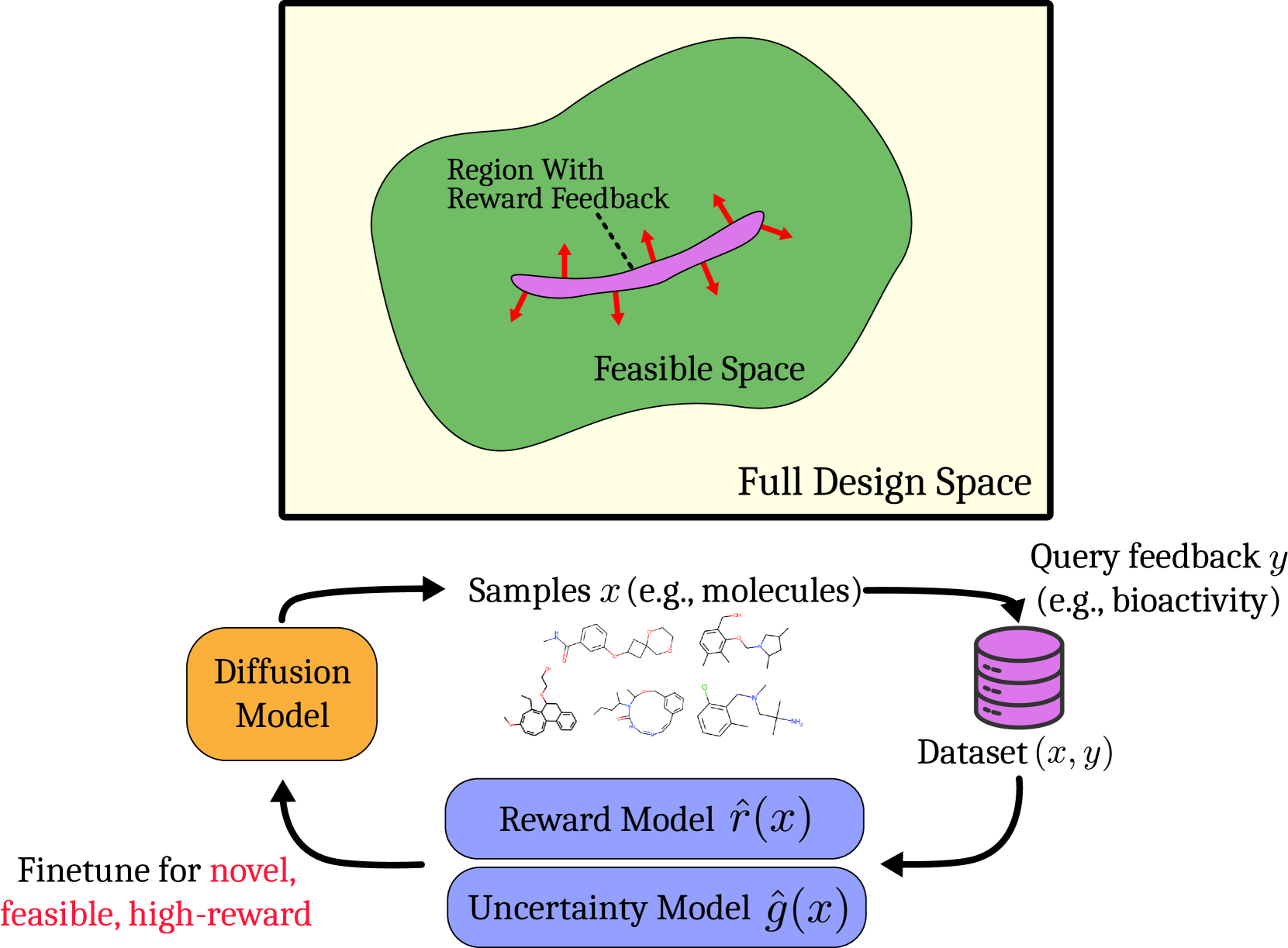
The iterative loop of SEIKO: Sampling -> Labelling -> Reward Model Update -> Diffusion Model Update.
Evaluation Highlights
- Outperforms baselines (PPO, classifier guidance) on ImageNet 64x64 aesthetic quality, achieving higher rewards with fewer queries.
- In biological sequence design (TF Bind 8), SEIKO finds high-activity sequences faster than PPO and specialized baselines like AdaProx.
- Significant gains in small molecule generation (QED optimization), maintaining high validity and diversity while maximizing properties.
Breakthrough Assessment
8/10
Strong theoretical grounding (regret guarantee) combined with effective empirical results across diverse, high-value domains (images, biology, chemistry). Directly addresses the critical bottleneck of query cost.