📝 Paper Summary
Low-resource NLP
Multilingual Data Curation
IndicLLMSuite addresses the scarcity of Indian language resources by releasing 251 billion tokens of pre-training data and 74 million instruction pairs created via a novel pipeline combining human verification and synthetic generation.
Core Problem
Low and mid-resource languages lack tailored data resources for LLM development because standard open-source pipelines fail to effectively curate diverse sources (websites, PDFs, videos) and cannot leverage high-quality model-generated instructions due to the absence of capable existing models.
Why it matters:
- Languages spoken by over 1.4 billion people (Indian sub-continent) are minimally represented in current open-source LLMs (e.g., Llama 2, Mistral), excluding rich cultural contexts.
- The 'chicken and egg' problem persists: lack of high-quality LLMs prevents the generation of synthetic data (like Self-Instruct) needed to train better LLMs.
- Existing pipelines like CommonCrawl contain noise, mislabeled languages, and defunct URLs, requiring specific curation for lower-resource languages.
Concrete Example:
Standard language identification tools often mislabel closely related Indic languages (e.g., Hindi and Marathi). Furthermore, many URLs in existing datasets like mC4 are now defunct or contain machine-translated content that degrades model quality, necessitating the manual verification strategy employed in this work.
Key Novelty
Verified-Synthetic Hybrid Curation (Sangraha & IndicAlign)
- Combines manually verified sources (Sangraha Verified) with large-scale synthetic translation of English content to balance high quality with the volume required for LLM training.
- Utilizes a custom Spark-based distributed pipeline (Setu) specifically designed to handle diverse Indic sources including OCR for PDFs and transcription for videos, unlike text-only web crawlers.
- Generates culture-grounded instruction data by prompting English LLMs (Llama 2, Mixtral) with India-centric Wikipedia articles, creating synthetic conversations rooted in local context.
Architecture
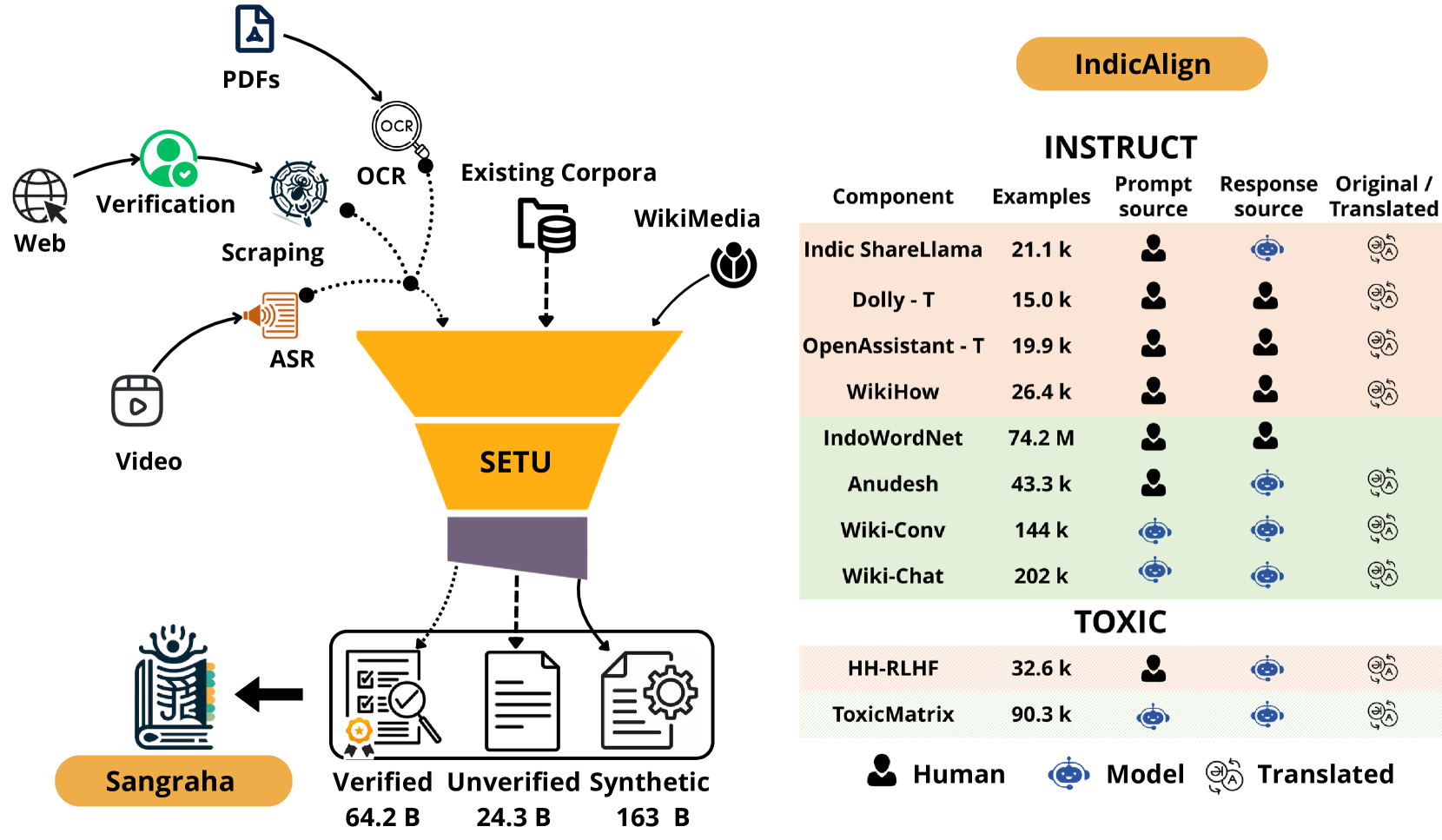
Overview of the IndicLLMSuite contributions, categorized into Pre-training (Sangraha), Pipeline (Setu), and Fine-tuning (IndicAlign) components.
Evaluation Highlights
- Release of Sangraha: A massive pre-training corpus containing 251 billion tokens across 22 Indian languages.
- Release of IndicAlign-Instruct: A collection of 74.8 million instruction-response pairs created via translation, aggregation, and synthetic generation.
- Release of IndicAlign-Toxic: 123,000 toxic prompt and non-toxic response pairs for safety alignment.
Breakthrough Assessment
8/10
A foundational resource contribution that significantly lowers the barrier for building LLMs in Indian languages. While it doesn't propose a new model architecture, the scale (251B tokens) and rigorous curation pipeline are major advancements for the field.