📝 Paper Summary
Offline-to-Online Reinforcement Learning
Fine-tuning
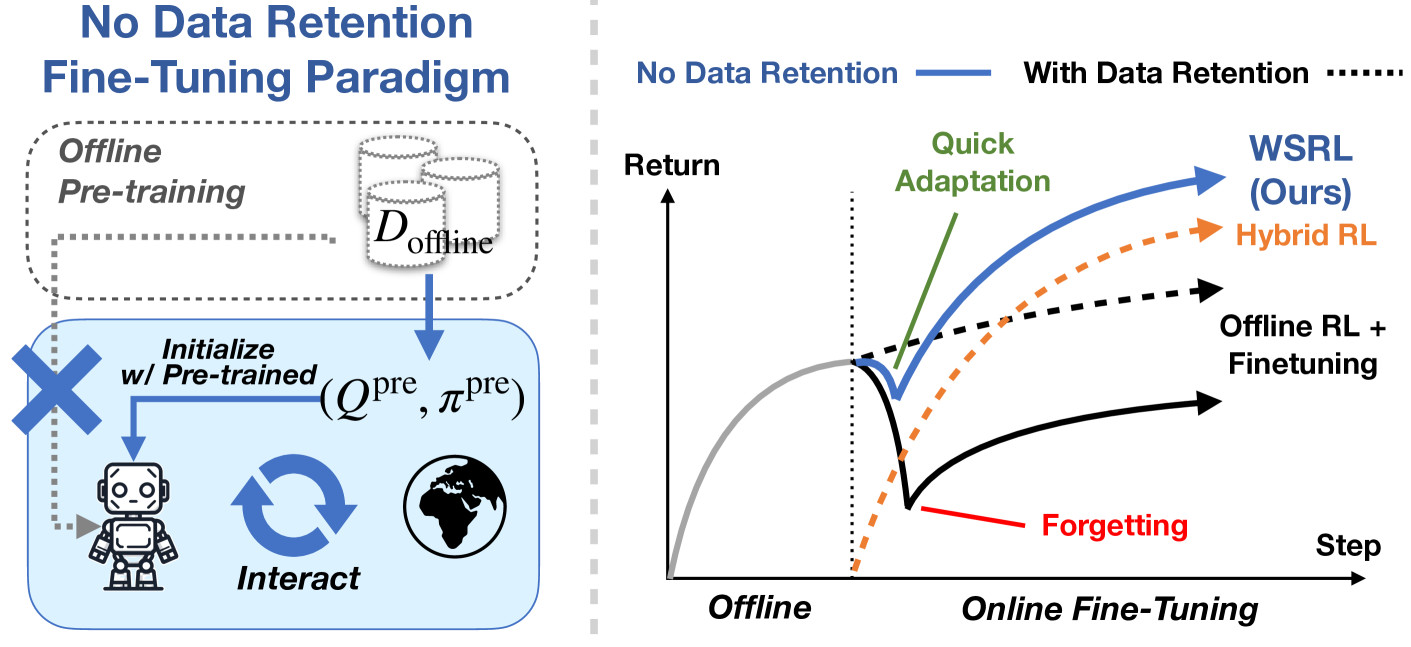
WSRL fine-tunes offline RL initializations without retaining offline data by using a short warmup phase with the frozen offline policy to recalibrate Q-values before standard high-UTD online training.
Core Problem
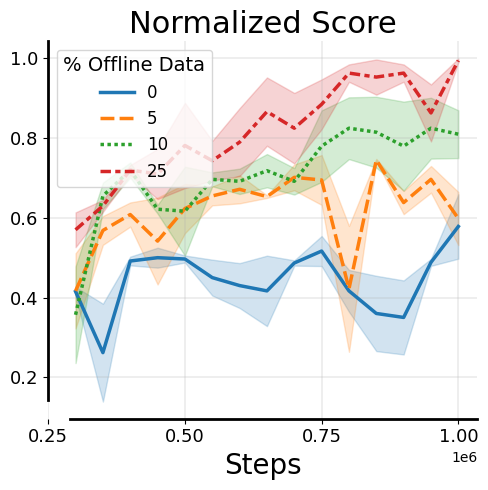
Standard RL fine-tuning requires mixing large offline datasets with online data to prevent instability, but this is computationally expensive and scales poorly.
Why it matters:
- Retaining massive offline datasets for online fine-tuning is slow and computationally prohibitive
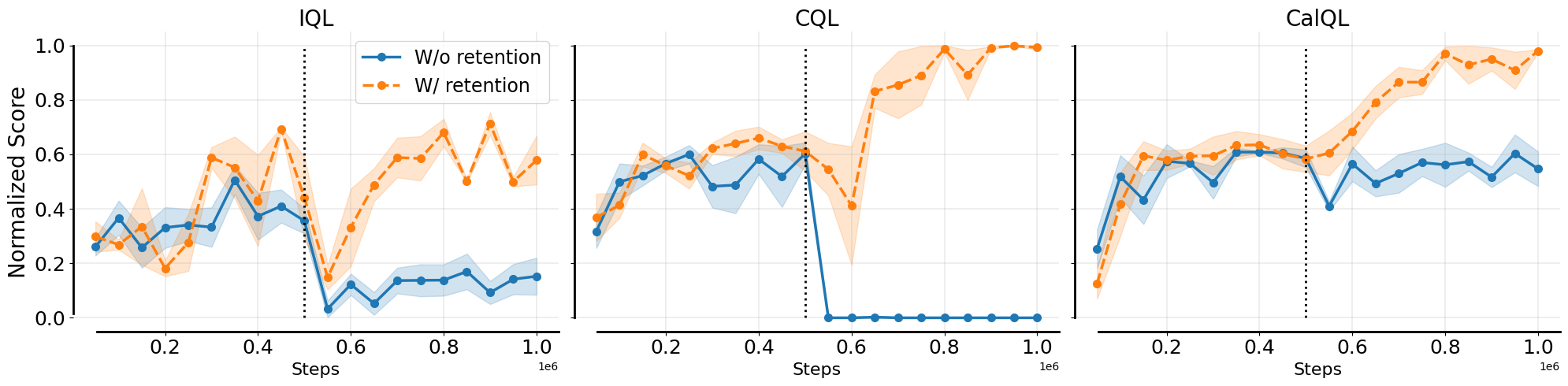
- Without offline data, current algorithms (CQL, IQL) suffer from catastrophic forgetting, where Q-values diverge immediately due to distribution shift
- Conservative offline constraints often limit the asymptotic performance potential during the online phase
Concrete Example:
When fine-tuning a pre-trained agent on the 'kitchen-partial' task without retaining offline data, standard algorithms like IQL and CQL immediately unlearn the task, dropping to nearly 0% success rate due to Q-value divergence.
Key Novelty
Warm Start Reinforcement Learning (WSRL)
- Simulates offline data retention by running a short 'warmup' phase where the agent interacts with the environment using the frozen pre-trained policy
- Collects on-policy data that bridges the distribution gap, allowing the Q-function to recalibrate to the online setting without diverging
- Switches to aggressive, unconstrained online RL (High UTD) after warmup, discarding offline data entirely
Architecture
The pseudocode/flow of the WSRL algorithm
Evaluation Highlights
- Existing methods (IQL, CQL) drop to ~0% success rate on kitchen-partial immediately when fine-tuning without offline data
- WSRL effectively utilizes a short warmup (e.g., 5000 steps) to prevent this forgetting
- WSRL attains higher asymptotic performance than algorithms that retain offline data (qualitative result, exact improvement metrics not in text snippet)
Breakthrough Assessment
7/10
Identifies a critical inefficiency in RL fine-tuning (data retention) and proposes a surprisingly simple, effective solution (warmup + high UTD) that matches or beats complex baselines.