📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Low-Rank Adaptation
SVFT fine-tunes models by adding a sparse, learnable weighted combination of the pre-trained weight matrix's own singular vectors, achieving high performance with extremely few parameters.
Core Problem
Existing PEFT methods like LoRA apply updates that are agnostic to the specific structure and geometry of the weight matrices they modify, often requiring more parameters to bridge the performance gap with full fine-tuning.
Why it matters:
- Storing adapters for many downstream tasks becomes expensive if parameter counts are high
- Ignoring the inherent geometry of pre-trained weights limits the expressivity of the update per parameter
- Current methods struggle to recover full fine-tuning performance (Full-FT) when restricted to extremely low parameter budgets
Concrete Example:
LoRA uses random Gaussian initialization for its low-rank matrices A and B, which are completely independent of the weight matrix W they are modifying. This generic update may require rank=8 or rank=16 to work well, whereas SVFT uses W's own singular vectors, requiring fewer parameters to achieve similar effects.
Key Novelty
Singular Vectors guided Fine-Tuning (SVFT)
- Update weight matrices by scaling their existing singular vectors rather than adding generic low-rank matrices
- Construct the update as a sum of rank-one matrices formed by outer products of the pre-trained weights' left and right singular vectors
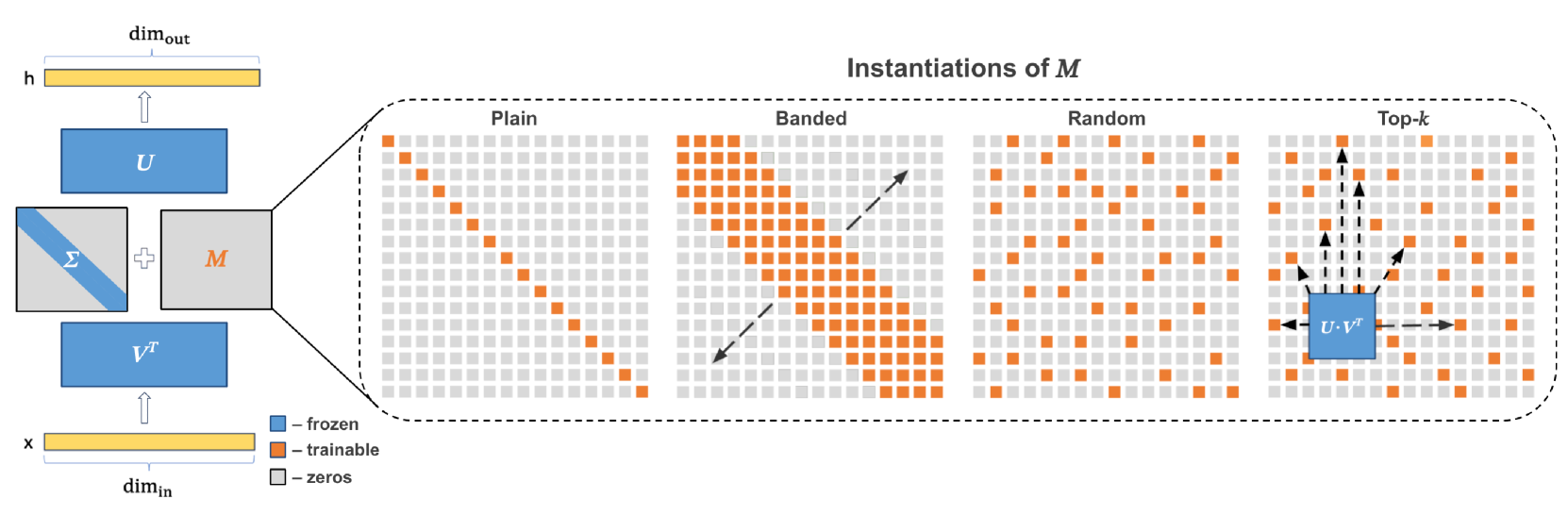
- Control expressivity via a fixed sparsity pattern in the mixing matrix, allowing precise targeting of singular value interactions
Architecture
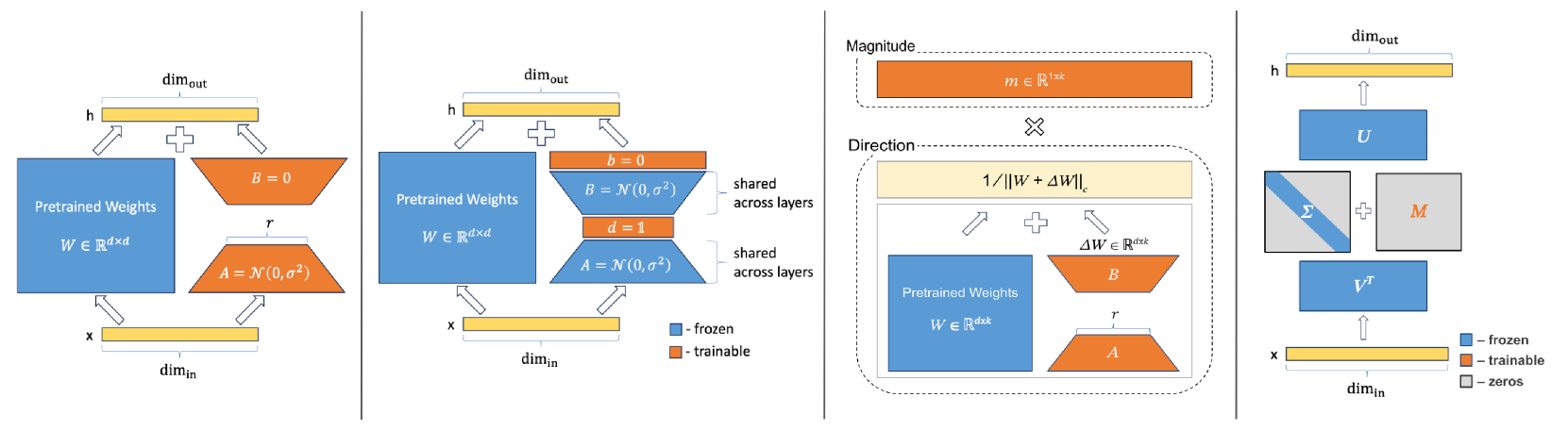
Illustration of the SVFT update mechanism compared to LoRA. Shows decomposition of W into U, Σ, V^T, and the sparse update matrix M.
Evaluation Highlights
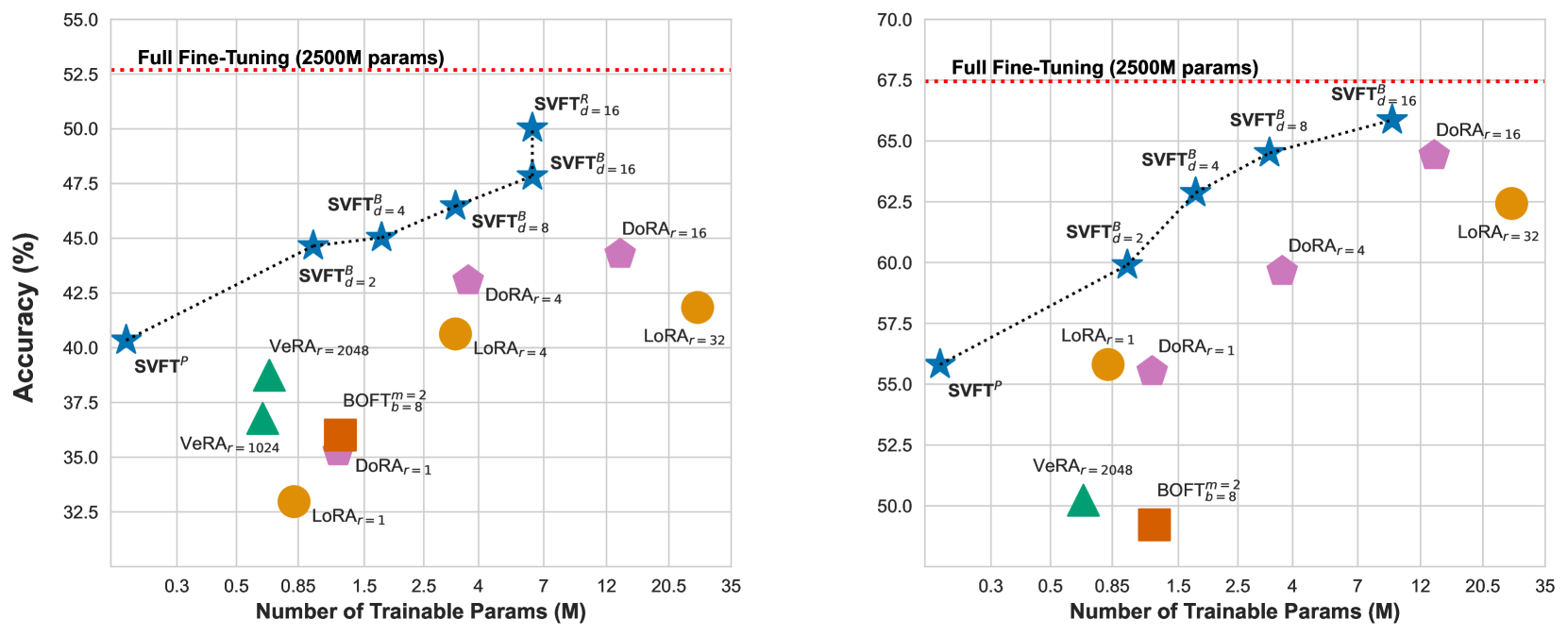
- Recovers up to 96% of full fine-tuning performance while training only 0.006% to 0.25% of parameters
- Outperforms existing PEFT methods (LoRA, DoRA, VeRA) that recover only up to 85% performance given similar parameter budgets (0.03% to 0.8%)
- Achieves higher accuracy than LoRA and DoRA across multiple vision and language benchmarks when normalized by trainable parameter count
Breakthrough Assessment
7/10
Significant improvement in parameter efficiency over LoRA/DoRA by exploiting weight geometry. Simple, elegant formulation with strong empirical results, though relies on SVD computation which adds memory overhead during training.