📝 Paper Summary
LLM Safety
Data Filtering for Fine-tuning
SAFT automatically filters harmful samples from unlabeled fine-tuning datasets by identifying a harmful subspace in the model's internal activation space and removing data that aligns with it.
Core Problem
Fine-tuning LLMs on datasets containing even small amounts of mixed harmful data (e.g., hate speech) significantly degrades model safety, but manual filtering is labor-intensive and subjective.
Why it matters:
- Real-world user interaction data often naturally contains a mixture of benign and harmful content (contamination)
- Existing alignment methods like RLHF require labeled preference data, which is expensive to obtain compared to unlabeled raw text
- A contamination ratio as low as 10% can severely compromise the safety of a fine-tuned model
Concrete Example:
When fine-tuning a Llama-2-chat model on a dataset with 10% harmful examples, the model's harmfulness score spikes significantly compared to training on pure data. Manually checking thousands of samples to find these toxic inputs is unscalable.
Key Novelty
Subspace-based Safety-Aware Fine-Tuning (SAFT)
- Leverages the insight that harmful data embeddings cluster in a specific subspace of the model's activation space, distinct from benign data
- Uses Singular Value Decomposition (SVD) on the embedding matrix to identify the principal directions (top singular vectors) associated with harmfulness
- Calculates a filtering score for each sample based on its projection onto these 'harmful' directions; samples with high scores are automatically discarded before fine-tuning
Architecture
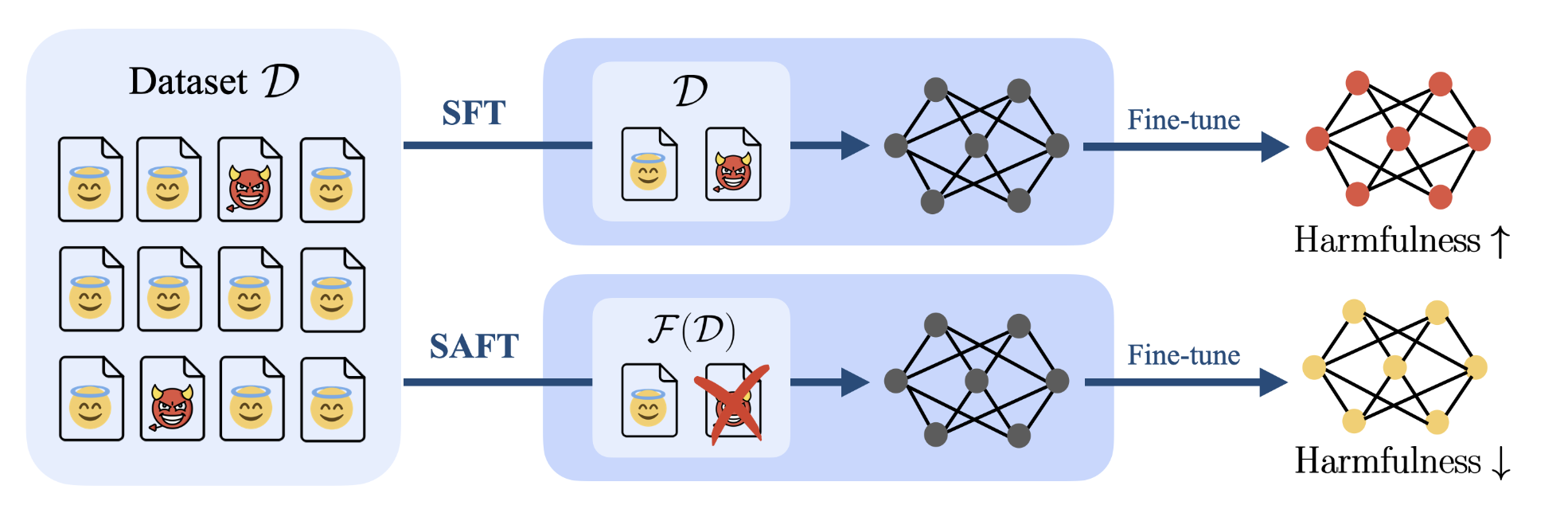
The SAFT framework workflow: Mixture Data -> Embedding Extraction -> PCA/SVD -> Filtering -> Clean Data -> Fine-Tuning
Evaluation Highlights
- Reduces harmfulness by up to 27.8% compared to standard Supervised Fine-Tuning (SFT) on the Beavertails dataset
- Maintains helpfulness scores comparable to models trained on clean benign data (e.g., BLEURT score of 0.504 vs 0.511)
- Demonstrates robustness across varying contamination rates (10% to 30%) and different LLM architectures
Breakthrough Assessment
7/10
Simple, mathematically grounded approach to a critical safety problem without requiring labeled data. Strong empirical results, though primarily tested on known safety benchmarks.
