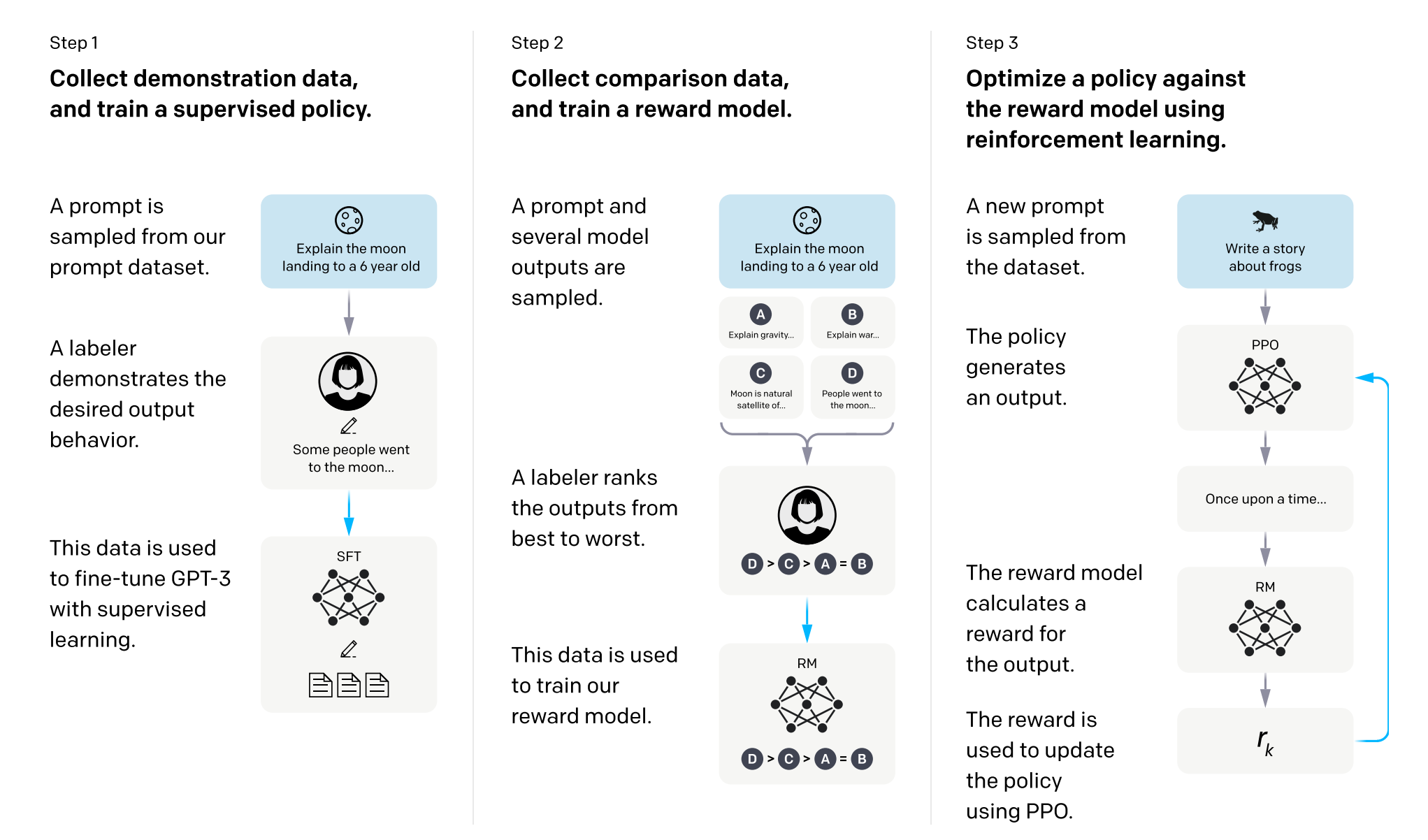
📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Large Language Models (LLMs)
Multimodal Learning
This survey provides a comprehensive taxonomy and review of over 100 Parameter-Efficient Fine-Tuning (PEFT) methods across NLP, computer vision, and multimodal domains, categorizing them into additive, reparameterized, subtractive, and hybrid approaches.
Core Problem
Fine-tuning entire Large Language Models (LLMs) for specific downstream tasks is computationally prohibitive and memory-intensive due to their massive parameter scale (billions to trillions).
Why it matters:
- Training large models like Llama-3.1 405B from scratch requires massive energy (e.g., 40 million GPU hours), raising environmental and cost concerns
- Full fine-tuning is impractical on consumer hardware, limiting accessibility for researchers and smaller organizations
- Existing surveys often focus narrowly on NLP or lack coverage of recent advancements in multimodal and diffusion models
Concrete Example:
Fine-tuning a 65B parameter model like LLaMA typically requires high-end multi-GPU clusters. Without PEFT, adapting such a model to a medical question-answering task would require updating all 65B weights, whereas PEFT might only update 1-2% of parameters, making it feasible on much smaller hardware.
Key Novelty
Unified PEFT Taxonomy across Modalities
- Expands the traditional PEFT classification (additive, reparameterized, subtractive) to include hybrid, quantization, and multi-task categories
- Breaks traditional domain boundaries by reviewing PEFT applications not just in NLP, but extensively in computer vision, multimodal fusion, and diffusion models
- Systematically analyzes over 100 papers from June 2019 to July 2024 to identify gaps and future directions like trustworthy PEFT and automated PEFT design
Architecture
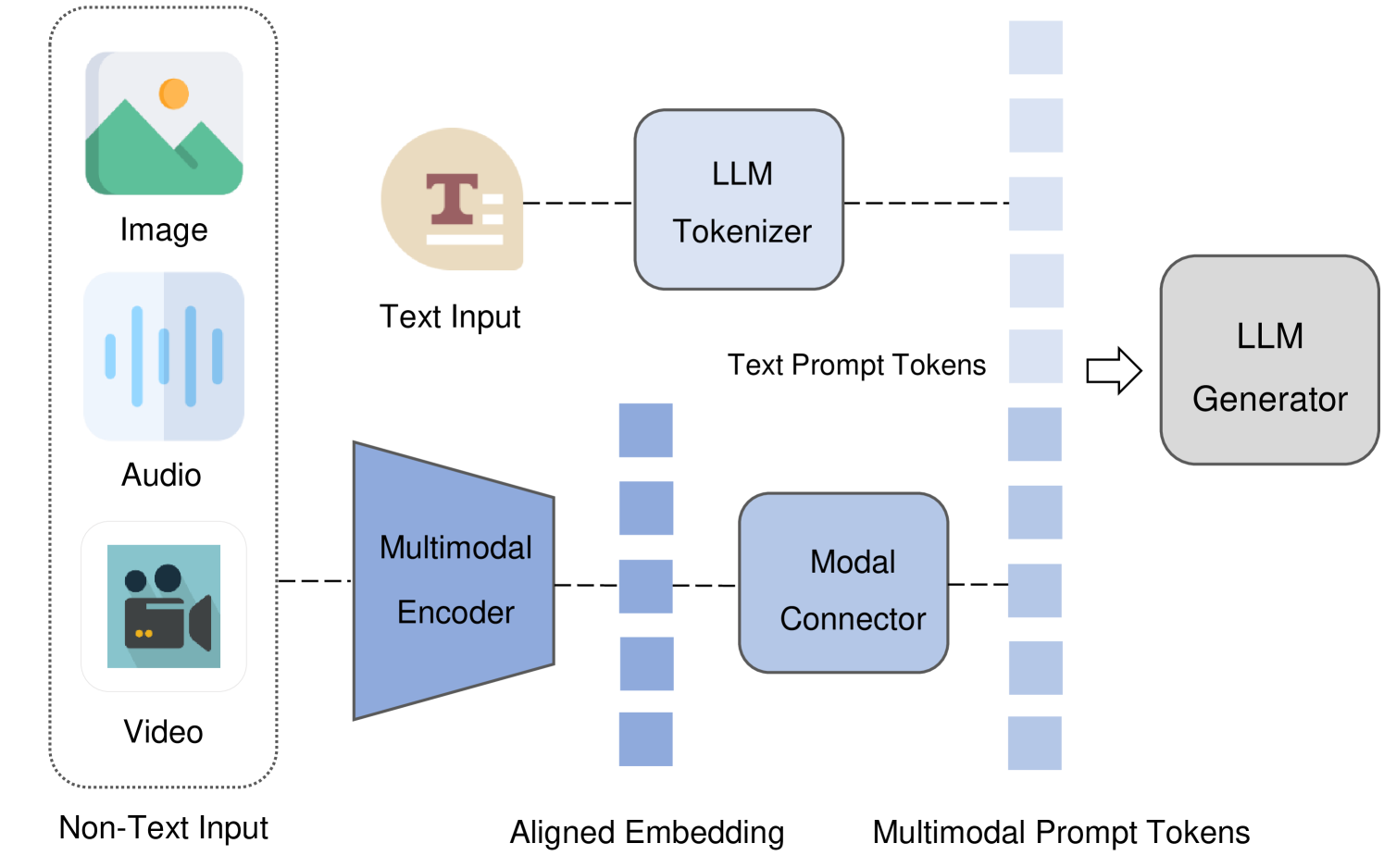
Mainstream architecture of multimodal large language models (MLLMs) composed of Multimodal Encoder, LLM, and Modal Connector
Evaluation Highlights
- Review covers over 100 research articles published from June 2019 to July 2024
- Identifies that PEFT methods typically update only 1-2% of total parameters while maintaining performance comparable to full fine-tuning
- highlights that PEFT can reduce computational costs from ~4 million GPU hours (full SFT) to 400K GPU hours or less
Breakthrough Assessment
8/10
A highly comprehensive survey that bridges the gap between NLP-focused PEFT reviews and emerging multimodal applications. While it doesn't propose a new algorithm, its taxonomy and breadth are valuable for the community.