📊 Experiments & Results
Evaluation Setup
Preference fine-tuning on summarization and instruction following tasks
Benchmarks:
- TL;DR Summarization (Text Summarization)
- AlpacaEval 2.0 (Instruction Following / Chat)
Metrics:
- Win Rate vs Reference (GPT-4 evaluated)
- Reverse KL Divergence
- Reward (using Gold Reward Model for TL;DR)
- Length-controlled Win Rate (AlpacaEval)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| TL;DR Summarization | GPT-4 Win Rate vs Reference | 46.5 | 52.2 | +5.7 |
| TL;DR Summarization | Reward (Gold RM) | 2.10 | 2.85 | +0.75 |
| AlpacaEval 2.0 (UltraFeedback) | Length-controlled Win Rate | 21.0 | 23.3 | +2.3 |
Experiment Figures
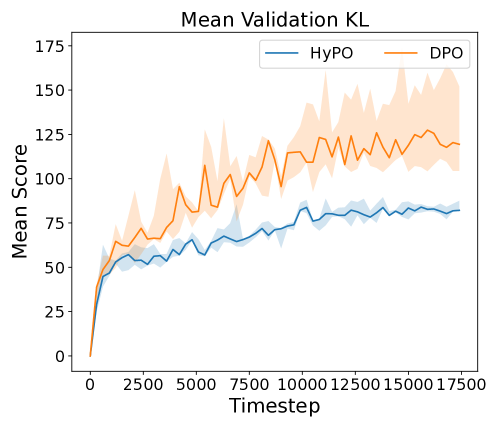
Reward vs. KL Divergence frontier for DPO and HyPO on TL;DR summarization.
Win rate vs. Reference Policy over training steps.
Main Takeaways
- HyPO consistently achieves higher win rates and rewards than DPO across both summarization and chat benchmarks.
- Offline methods like DPO tend to have uncontrolled growth in reverse KL divergence as optimization proceeds, drifting far from the reference.
- HyPO effectively controls the reverse KL divergence through its online regularization term, keeping the policy closer to the reference while still optimizing rewards.
- The theoretical separation holds: limited offline data coverage hampers DPO's ability to stay within the 'trust region' of the reference policy, which online sampling fixes.