📝 Paper Summary
Differentially Private Machine Learning
Parameter-Efficient Fine-tuning (PEFT)
Large Language Model Optimization
DP-ZO enables private fine-tuning of large language models by privatizing the scalar loss difference from zeroth-order optimization steps, avoiding the heavy memory cost of per-sample gradient clipping.
Core Problem
Standard Differentially Private Stochastic Gradient Descent (DP-SGD) requires per-example gradient clipping, which incurs massive memory overheads and engineering complexity when scaling to large foundation models.
Why it matters:
- Scaling DP training to models like OPT-66B is computationally prohibitive with DP-SGD due to memory constraints.
- Existing private training methods often struggle to balance privacy guarantees with utility, particularly under strict privacy budgets (pure epsilon-DP).
- Pretrained checkpoints are a valuable resource, but fine-tuning them on private data remains a bottleneck due to the hardware requirements of backpropagation-based DP methods.
Concrete Example:
When fine-tuning an OPT-66B model, DP-SGD would require storing and clipping gradients for each sample in a batch, likely causing Out-Of-Memory errors on standard GPUs. DP-ZO avoids this by only needing forward passes and privatizing a single scalar value per step.
Key Novelty
Differentially Private Zeroth-Order Optimization (DP-ZO)
- Instead of calculating gradients via backpropagation, DP-ZO estimates the update direction using random perturbations and the difference in loss values (a scalar).
- Privacy is achieved by adding noise to this scalar loss difference, rather than to a high-dimensional gradient vector, circumventing the curse of dimensionality.
- Because the sensitivity is defined on a scalar, it enables the use of the Laplace mechanism for pure epsilon-DP, which is typically infeasible for high-dimensional DP-SGD.
Architecture
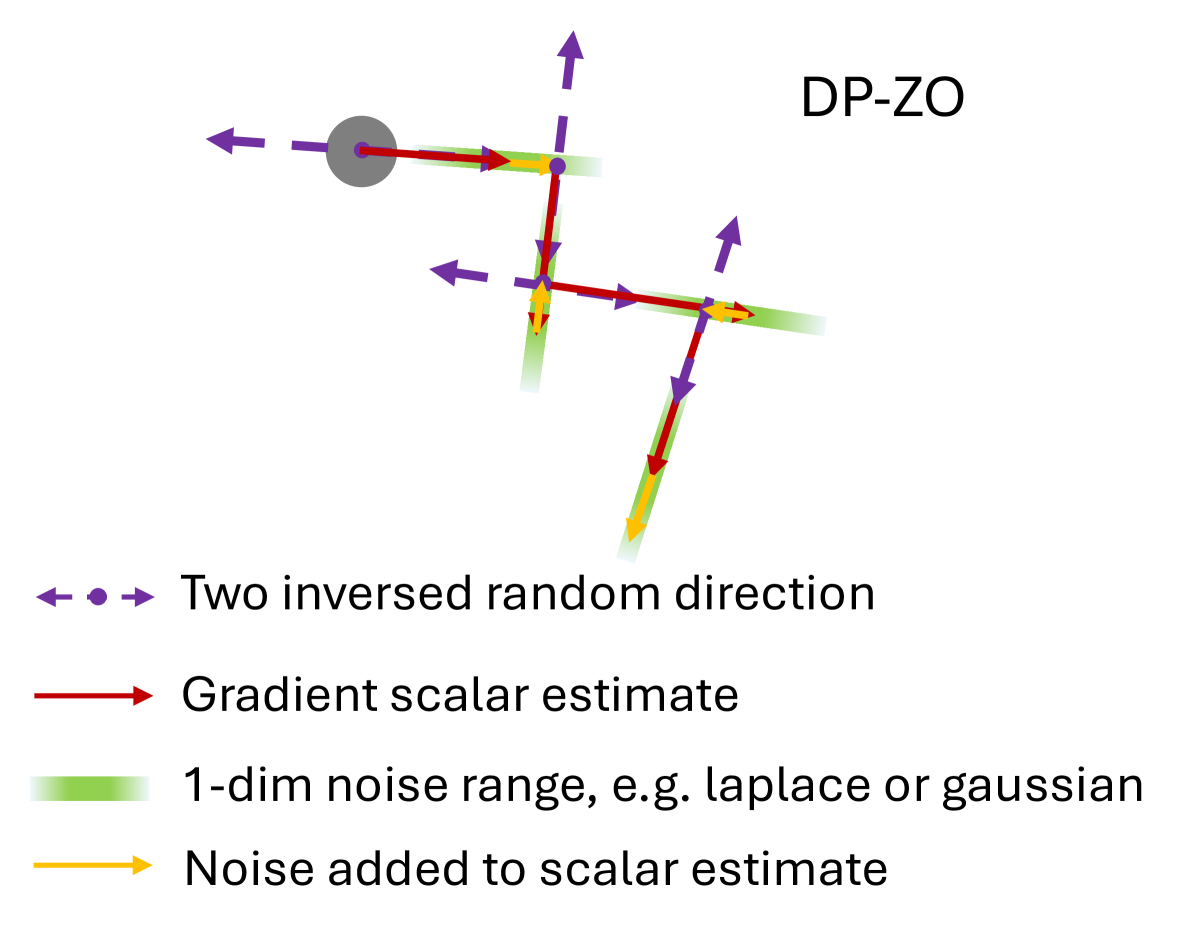
Comparison of DP-SGD and DP-ZO update mechanisms.
Evaluation Highlights
- Achieves 93.5% of non-private performance on RoBERTa-large for SST-2 with (epsilon=8, delta=1e-5)-DP.
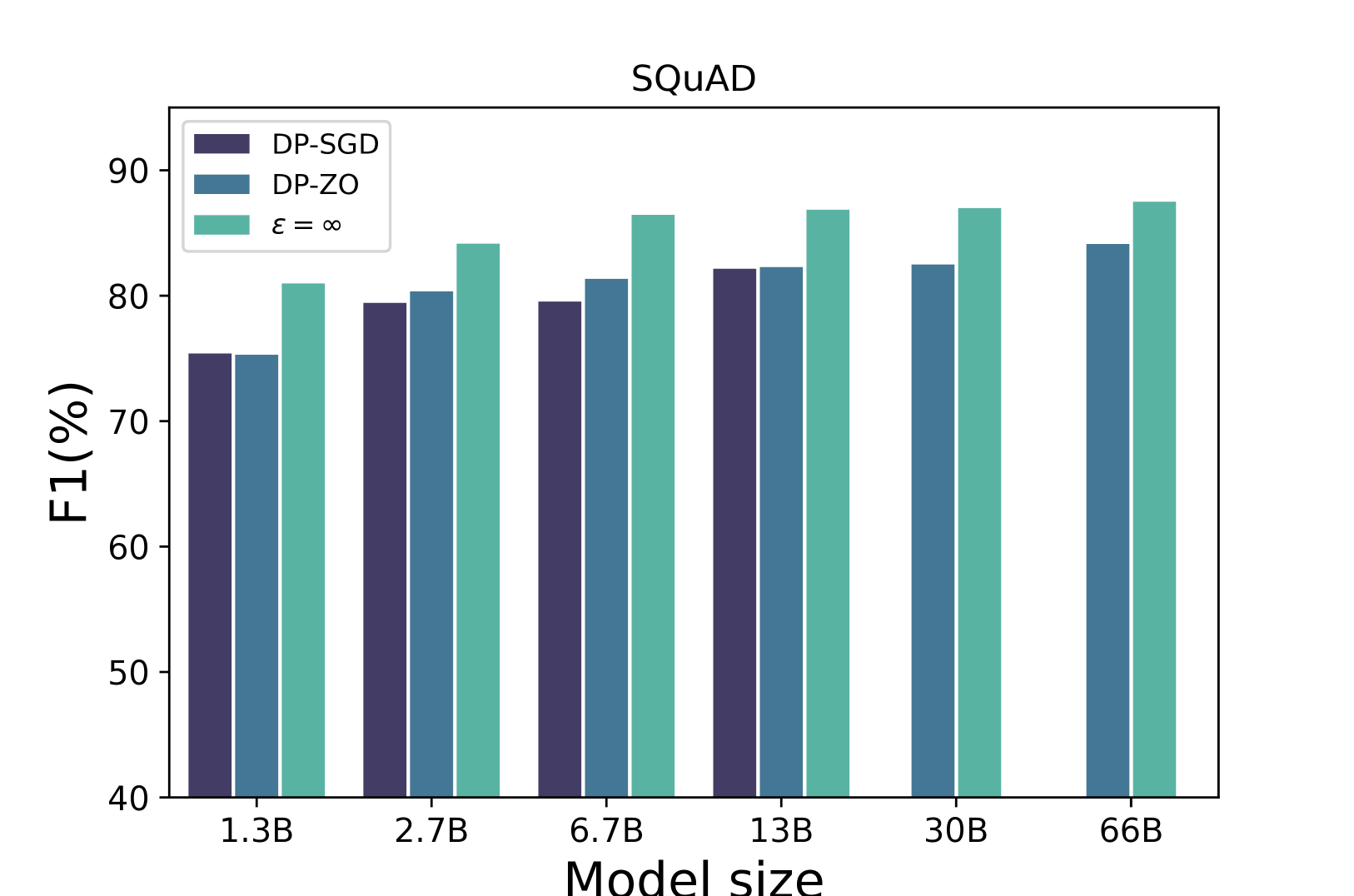
- Outperforms DP-SGD on OPT-13B (SQuAD task) with a score of 81.3 vs 80.8, while using significantly less memory.
- First method to provide non-trivial utility (73.52 on SQuAD) under pure epsilon-DP (epsilon=4) for large models using the Laplace mechanism.
Breakthrough Assessment
8/10
Significant for enabling private training on very large models where DP-SGD fails due to memory. The ability to use pure epsilon-DP effectively is a strong theoretical and practical contribution.