📝 Paper Summary
Adversarial Robustness
Vision-Language Models
PMG-AFT improves the zero-shot adversarial robustness of CLIP by guiding the adversarial fine-tuning process with features from the original frozen pre-trained model to prevent overfitting.
Core Problem
Standard adversarial fine-tuning of large-scale pre-trained models like CLIP leads to overfitting on the target dataset, causing a loss of the model's original zero-shot generalization capabilities.
Why it matters:
- Large-scale models like CLIP are increasingly deployed in security-critical tasks but remain vulnerable to imperceptible adversarial attacks.
- Existing defense methods like standard adversarial training are computationally expensive and impractical for massive models.
- Current fine-tuning defenses sacrifice clean accuracy and generalization for robustness on specific seen datasets, failing to protect against attacks in zero-shot settings.
Concrete Example:
When CLIP is adversarially fine-tuned on TinyImageNet using methods like FT-TeCoA, its robustness on TinyImageNet improves, but its accuracy on clean samples drops significantly, and its robustness on unseen datasets (zero-shot robustness) remains suboptimal due to overfitting.
Key Novelty
Pre-trained Model Guided Adversarial Fine-Tuning (PMG-AFT)
- Introduces an auxiliary 'generalization information branch' that forces the fine-tuned model's output on adversarial examples to match the output of the original frozen pre-trained model.
- Adds a regularization loss that encourages feature consistency between clean and adversarial examples within the target model to maintain clean accuracy.
- Combines these constraints with standard text-guided adversarial training to balance task-specific robustness with the preservation of generalizable features learned during pre-training.
Architecture
The overall framework of PMG-AFT (Pre-trained Model Guided Adversarial Fine-Tuning).
Evaluation Highlights
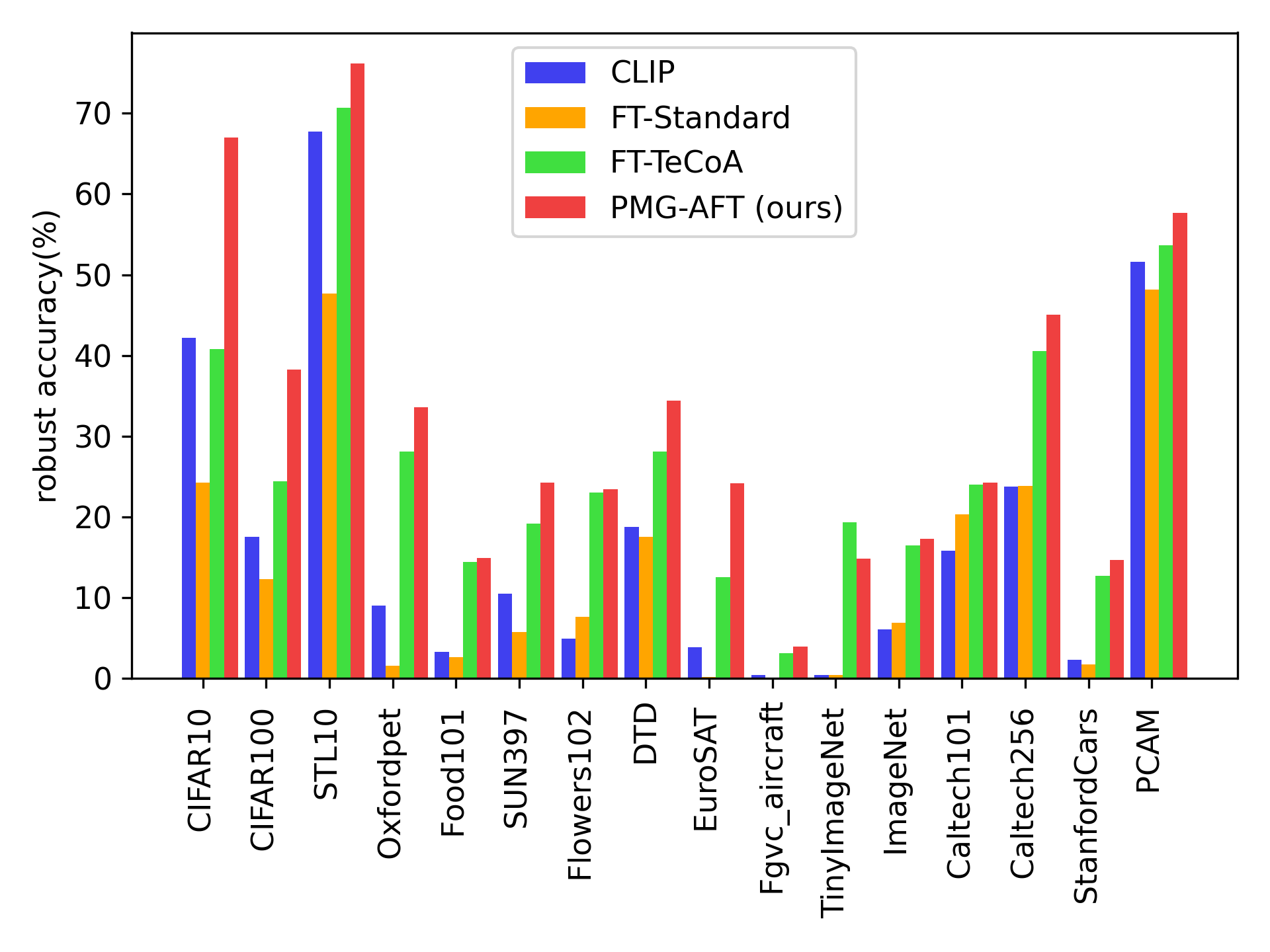
- Outperforms state-of-the-art method (FT-TeCoA) by +4.99% in average zero-shot robust accuracy across 15 datasets.
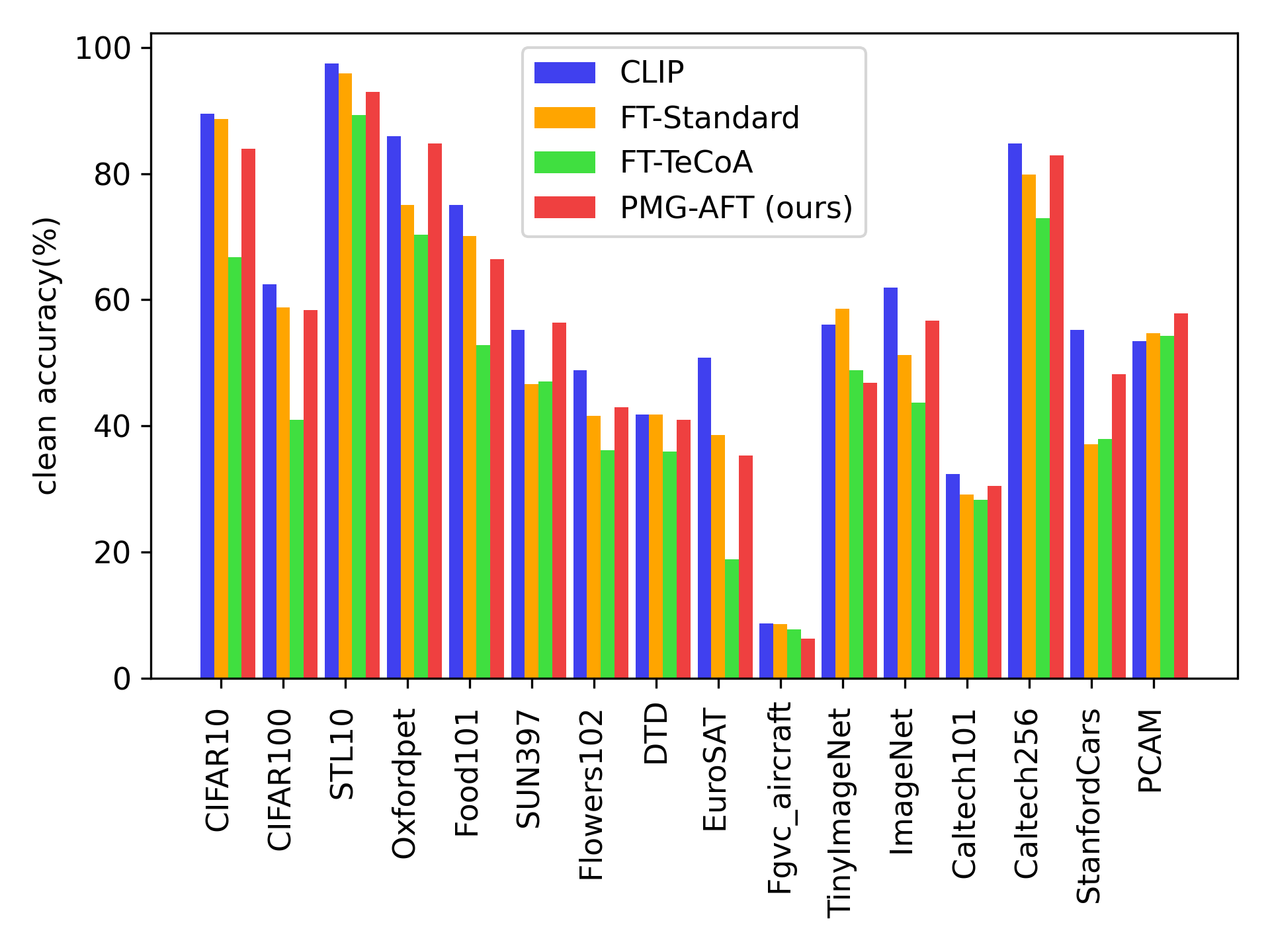
- Improves average clean accuracy by +8.72% compared to FT-TeCoA, mitigating the trade-off between robustness and clean performance.
- Demonstrates consistent improvements across diverse datasets (e.g., ImageNet, CIFAR-10, Caltech101) without additional training data beyond the fine-tuning set.
Breakthrough Assessment
7/10
Significantly mitigates the catastrophic overfitting problem in adversarial fine-tuning of VLP models, achieving a strong balance between zero-shot robustness and clean accuracy.