📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Visual Recognition
Transfer Learning
Mona-tuning introduces multi-scale convolutional adapters with input normalization to surpass full fine-tuning performance on complex visual tasks while updating fewer parameters.
Core Problem
Existing delta-tuning methods (like linear adapters) fail to surpass full fine-tuning on challenging dense prediction tasks because they are designed for language signals rather than visual signals.
Why it matters:
- Full fine-tuning is resource-intensive and dominant, but potentially suboptimal for retaining pre-trained capabilities.
- Current visual adapters treat visual tokens like text tokens (using linear layers), ignoring the spatial and multi-scale nature of visual data.
- Fixed backbone layers provide biased feature distributions to adapters that traditional designs cannot correct.
Concrete Example:
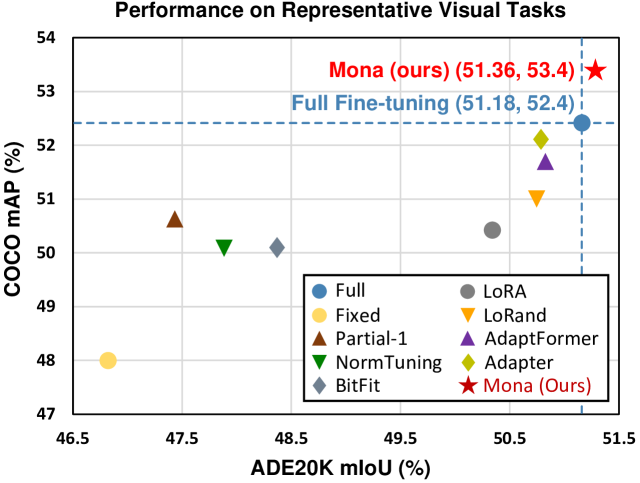
A standard linear adapter treats an image feature map as a sequence of tokens, applying the same transformation regardless of spatial context. This fails in tasks like instance segmentation (COCO), where standard adapters lag behind full fine-tuning. Mona uses multi-scale convolutions to capture spatial details, achieving +1.0 AP over full fine-tuning on COCO.
Key Novelty
Multi-cognitive Visual Adapter (Mona)
- Replaces standard linear adapter filters with 'vision-friendly' depth-wise convolutional filters of varying kernel sizes (3x3, 5x5, 7x7) to capture multi-scale visual information.
- Incorporates an input optimization mechanism using LayerNorm and learnable scaling factors to correct distribution shifts from the frozen backbone.
- Uses a parallel design where the adapter processes features alongside the frozen backbone layers, integrating results via a summation.
Architecture
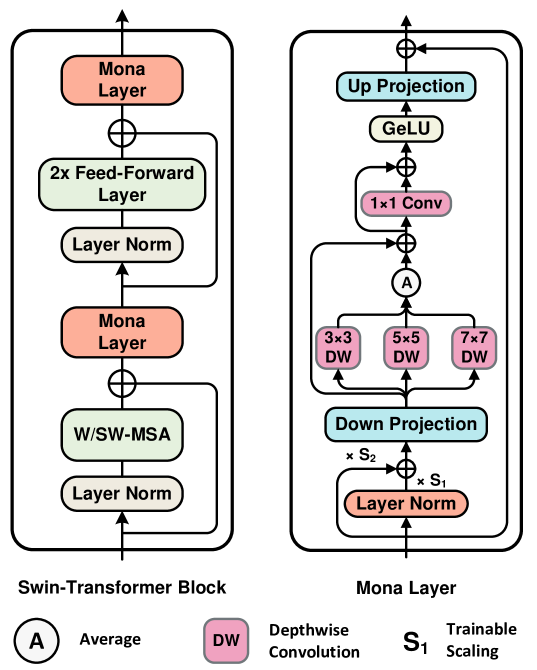
Detailed structure of the Mona adapter module.
Evaluation Highlights
- Outperforms full fine-tuning on COCO instance segmentation by 1.0% mAP using Swin-Base.
- Surpasses full fine-tuning on Pascal VOC object detection by 3.6% APbox using Swin-Large.
- Achieves higher mIoU than full fine-tuning on ADE20K semantic segmentation (+0.18%) while updating significantly fewer parameters.
Breakthrough Assessment
8/10
Significant because it breaks the 'ceiling' of full fine-tuning on complex dense prediction tasks (detection/segmentation), which previous PEFT methods failed to do consistently.