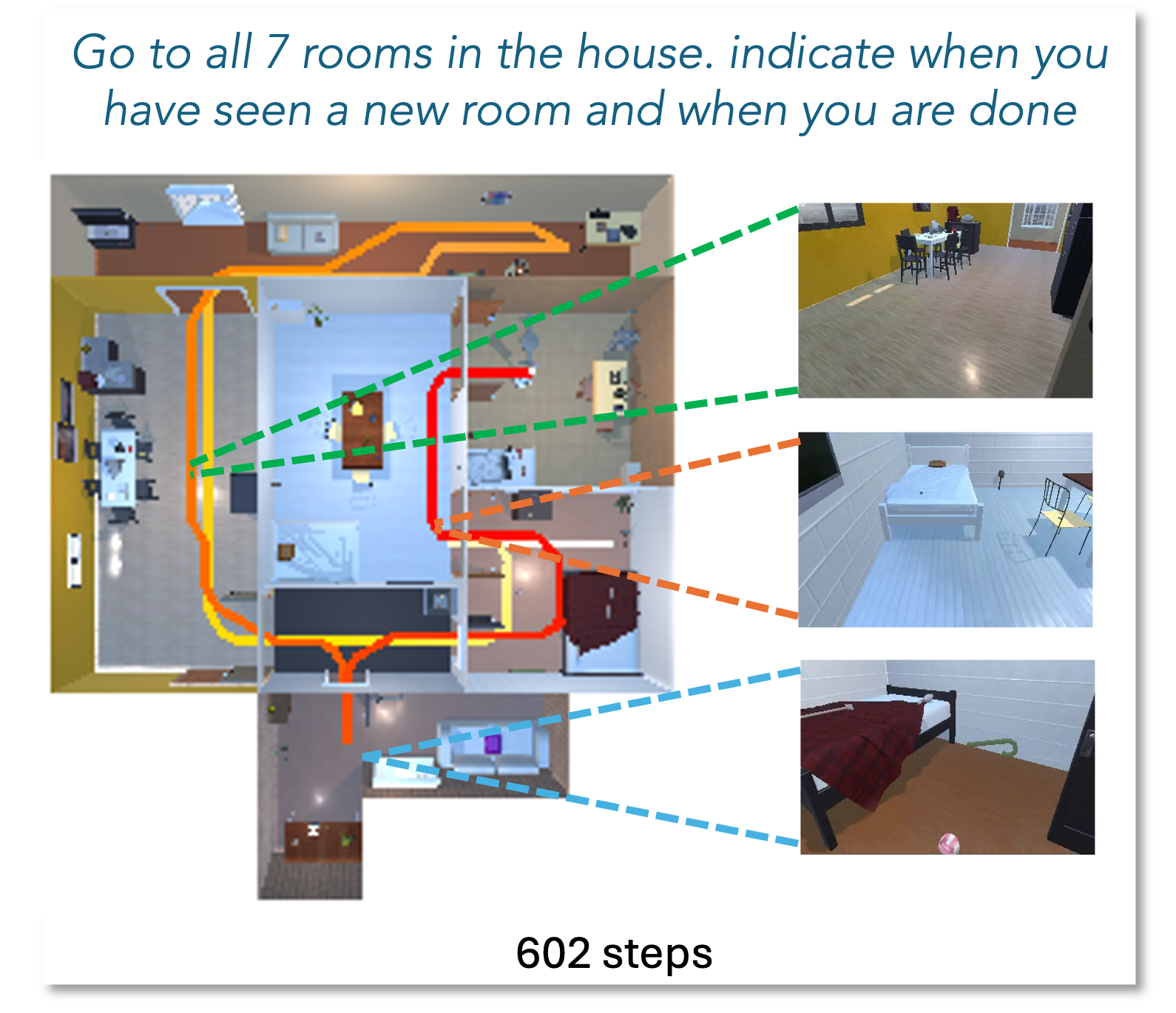
📝 Paper Summary
Robot Learning
Foundation Models in Robotics
Sim-to-Real Transfer
FLaRe fine-tunes large-scale multi-task behavior cloning policies using stable on-policy reinforcement learning in simulation with sparse rewards, significantly improving performance on unseen tasks and real-world robots.
Core Problem
Large-scale behavior cloning (BC) policies suffer from compounding errors and struggle to generalize to unseen states or tasks, leading to unsatisfactory real-world performance despite high training capacity.
Why it matters:
- Direct deployment of BC policies hits a performance plateau because models are constrained to expert trajectories and cannot recover effectively from errors.
- RL from scratch is sample inefficient and requires difficult-to-scale hand-crafted reward functions.
- Prior attempts to fine-tune BC with RL often fail due to destructive gradient updates (policy collapse) when scaling to large networks.
Concrete Example:
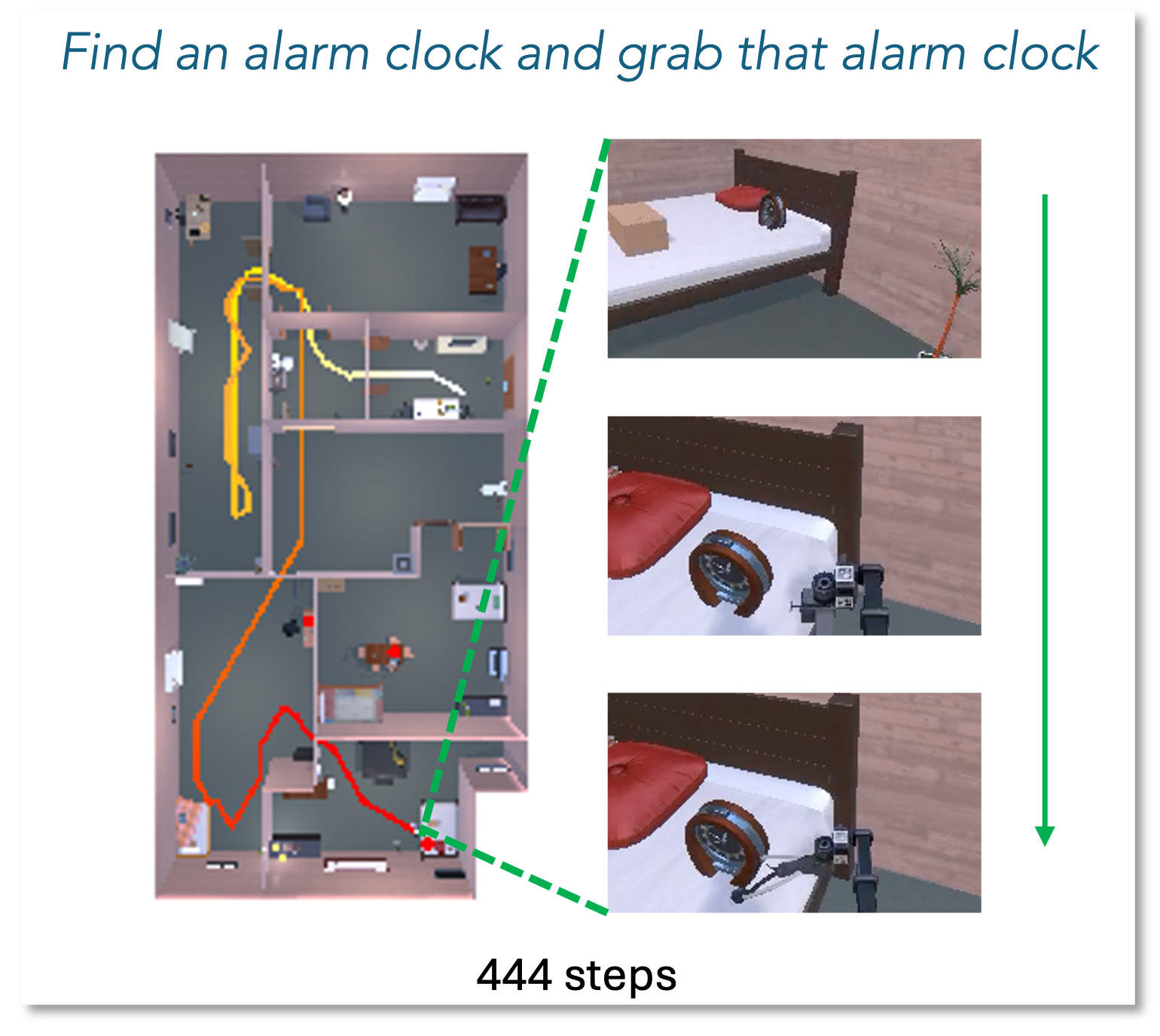
A robot trained via BC might fail a navigation task if it drifts slightly off the expert path, as it has never seen how to recover. FLaRe allows the robot to learn recovery behaviors through trial-and-error in simulation using only a 'success/fail' signal.
Key Novelty
Stable Large-Scale RL Fine-Tuning of Robotics Foundation Models
- Starts with a multi-task transformer policy (SPOC) pre-trained via BC, utilizing its robust representations as a starting point rather than training from scratch.
- Performs massive-scale fine-tuning in simulation (ProcTHOR) using only sparse rewards (task completion), bypassing the need for complex reward engineering.
- Stabilizes training via specific algorithmic choices: on-policy PPO, very small learning rates, disabling entropy bonuses, and separating actor/critic feature extractors to prevent 'unlearning' pre-trained priors.
Architecture
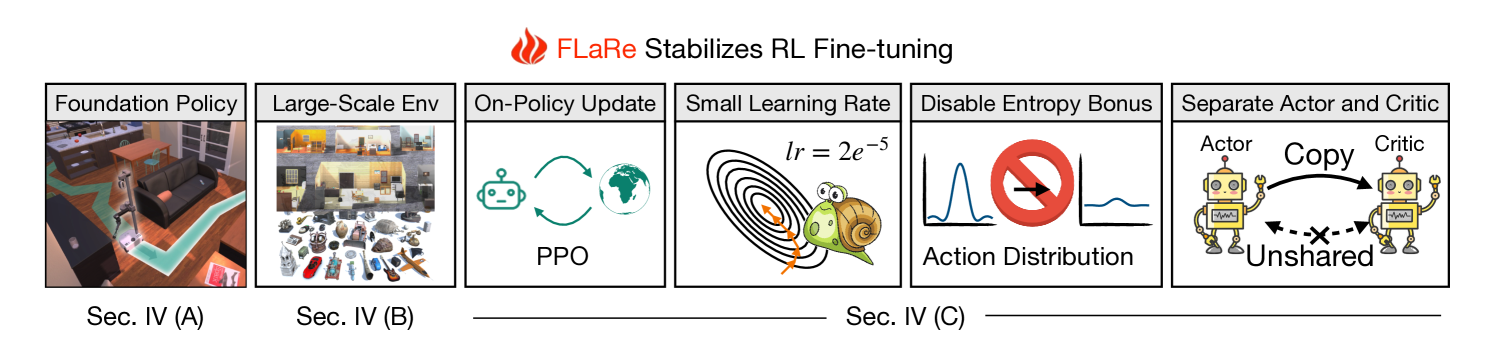
The FLaRe framework pipeline, illustrating the transition from a pre-trained multi-task BC policy to RL fine-tuning in simulation.
Evaluation Highlights
- +23.6% absolute improvement in success rate over state-of-the-art baselines on unseen simulated environments for long-horizon mobile manipulation tasks.
- +30.7% absolute improvement over prior best methods in real-world deployment (80.7% success rate vs 50.0%).
- Achieves 15x reduction in training time compared to RL-from-scratch baselines like Poliformer while using only sparse rewards.
Breakthrough Assessment
8/10
Strong practical contribution demonstrating that RL fine-tuning can fix the brittleness of foundation models in robotics. The sim-to-real results are impressive, and the method simplifies reward engineering significantly.