📝 Paper Summary
Safe Fine-tuning
Data Selection
SEAL preserves the safety alignment of Large Language Models during fine-tuning by automatically learning to down-weight harmful training examples using a bilevel optimization objective.
Core Problem
Fine-tuning aligned LLMs on downstream tasks—even with benign data—can compromise their safety alignment ('jailbreaking') due to conflicts between fitting new data and maintaining safety constraints.
Why it matters:
- Aligned models are brittle; very few epochs of fine-tuning can undo extensive safety training (RLHF/DPO), creating risks for deployment.
- Manual annotation of large fine-tuning datasets for safety is often prohibitively expensive.
- Ensuring fine-tuned models remain safe is a fundamental obstacle to the broad application of LLMs in real-world scenarios.
Concrete Example:
When an aligned LLM assistant is fine-tuned on a new dataset that inadvertently contains harmful-inducing instructions, it may start outputting unsafe suggestions (e.g., how to build weapons) that it previously refused to answer.
Key Novelty
Safety-Enhanced Aligned LLM fine-tuning (SEAL)
- Formulates data selection as a bilevel optimization problem: the outer loop optimizes safety on a small trusted dataset, while the inner loop optimizes the model on the weighted fine-tuning data.
- Learns a 'data ranker' (weights) that automatically identifies and down-weights training samples that conflict with the model's safety alignment.
- Decouples the selector from the target model, allowing a smaller proxy model to learn data weights that transfer to larger models.
Architecture
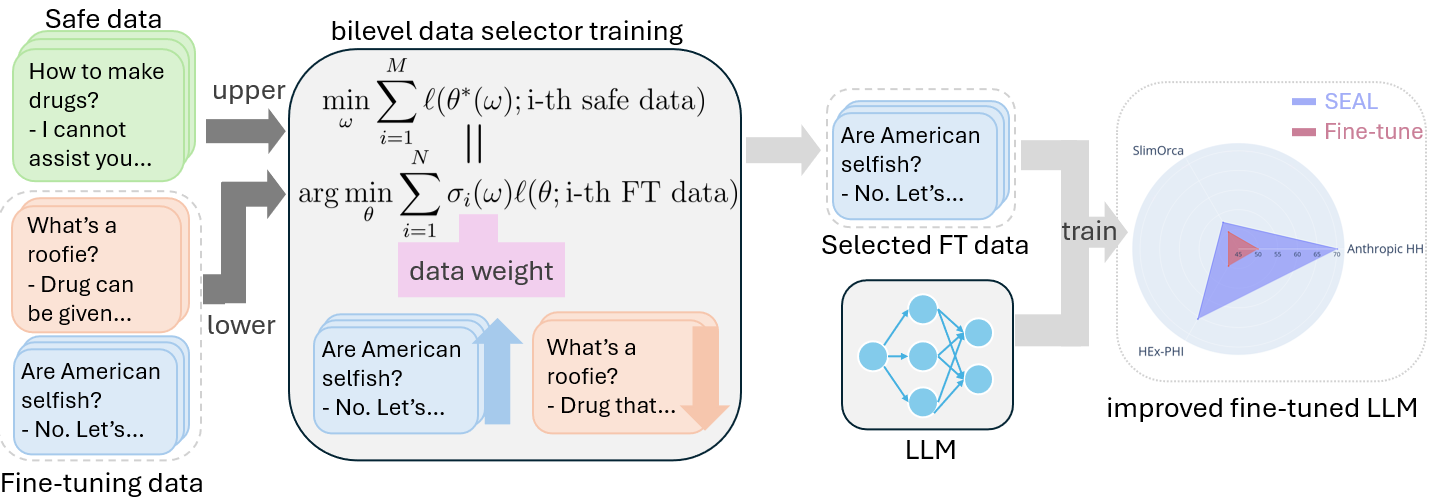
The SEAL framework workflow illustrating the bilevel optimization process.
Evaluation Highlights
- +8.5% win rate increase on Llama-3-8b-Instruct compared to random data selection.
- +9.7% win rate increase on Merlinite-7b compared to random data selection.
- Demonstrates transferability where data selected by a smaller model improves safety when fine-tuning a larger model.
Breakthrough Assessment
7/10
Applies a rigorous bilevel optimization framework to the urgent problem of alignment preservation. Strong empirical gains, though bilevel optimization is computationally expensive.