📝 Paper Summary
Domain Adaptation
Model Merging
Materials Science
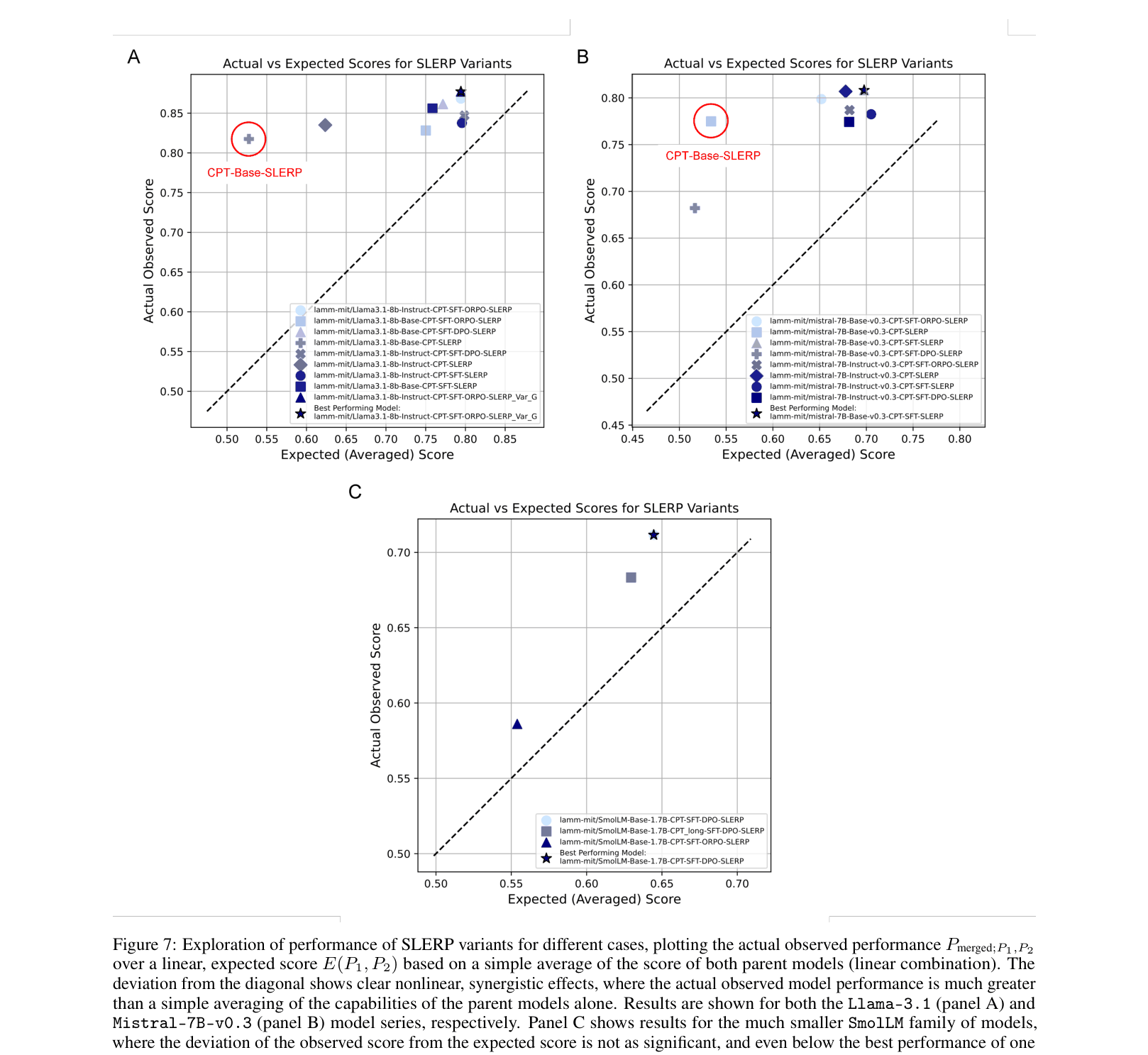
Combining domain-specific fine-tuning with spherical model merging unlocks synergistic capabilities in 7B-8B parameter models that exceed the performance of parent models, though this emergence is absent in smaller 1.7B models.
Core Problem
General-purpose LLMs lack specialized technical knowledge for fields like materials science, while standard fine-tuning often degrades general capabilities or fails to fully integrate new domain logic.
Why it matters:
- Developing specialized models for complex engineering domains (e.g., biomateriomics) is computationally expensive if training from scratch
- Standard fine-tuning strategies often result in catastrophic forgetting or linear trade-offs rather than synergistic performance gains
- Understanding how model scale influences the success of merging strategies is critical for efficient deployment on edge devices vs. servers
Concrete Example:
When a base model is fine-tuned on materials science papers (CPT), it may lose its instruction-following ability; conversely, an instruct model lacks specific knowledge about 'biological material design concepts'. Merging them attempts to retain both.
Key Novelty
Synergistic Domain Adaptation via SLERP Merging
- Applies Spherical Linear Interpolation (SLERP) to merge a domain-adapted model (trained via CPT, SFT, and ORPO) with a general-purpose instruction-tuned model
- Demonstrates that this merging is not merely additive but creates nonlinear 'emergent' capabilities where the merged model outperforms the average of its parents
- Identifies a scaling threshold where 7B+ parameter models exhibit this synergy, while 1.7B parameter models do not
Architecture
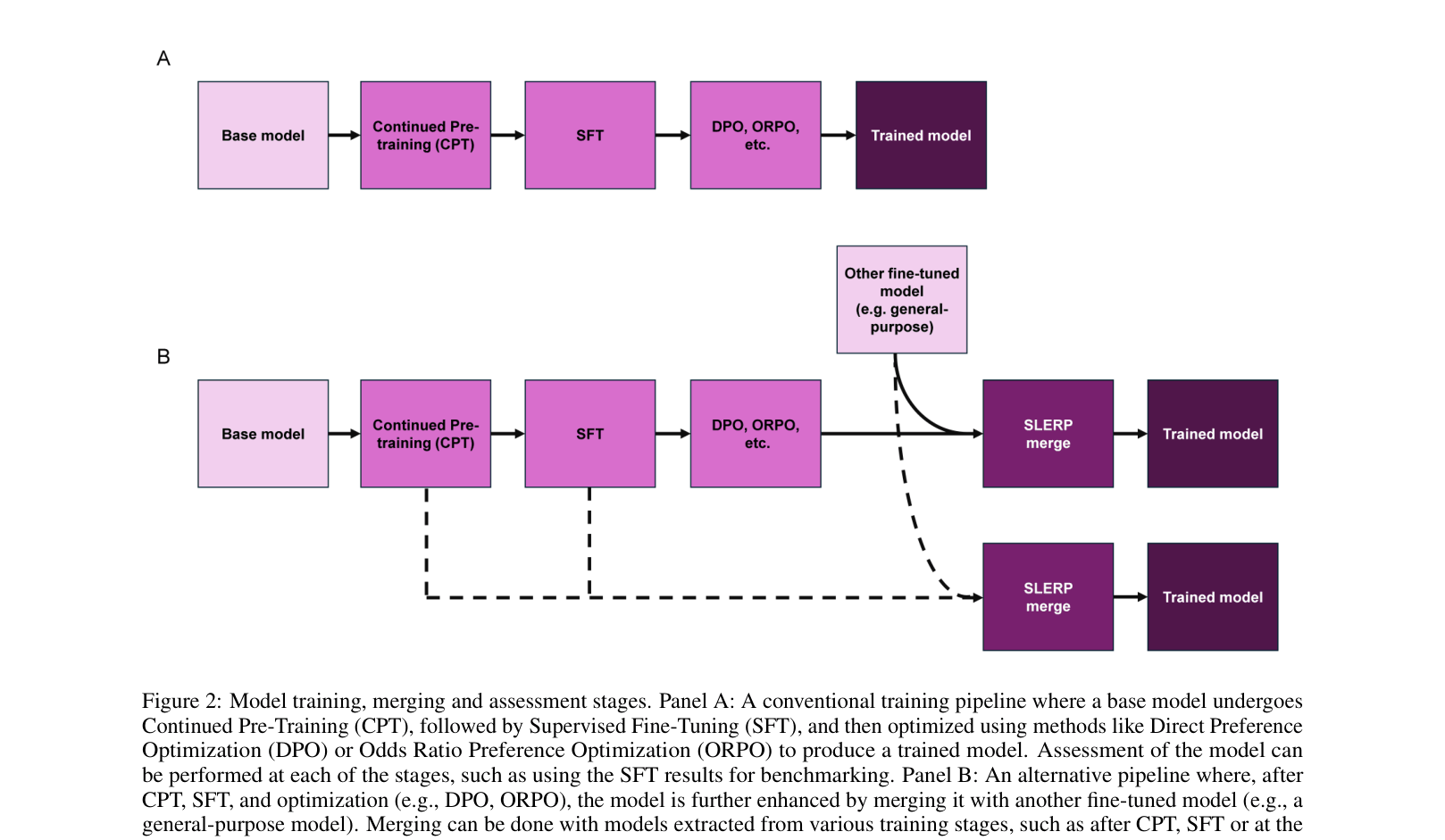
Comparison of two training pipelines: (A) Linear sequence of CPT->SFT->DPO/ORPO, and (B) The proposed pipeline adding Model Merging (SLERP) at the end.
Evaluation Highlights
- Mistral-7B variants using SLERP merging achieve >20% relative improvement over the Mistral-7B-Instruct-v0.3 baseline on domain benchmarks
- The best fine-tuned Mistral model achieves an absolute accuracy score of 0.81 on the overall domain benchmark using the integrated dataset
- Llama-3.1-8B merged models show ~12% relative improvement over the Instruct baseline, with Instruct-CPT-SFT-ORPO-SLERP being the top strategy
Breakthrough Assessment
7/10
Provides strong empirical evidence for the non-linear benefits of SLERP merging in domain adaptation and identifies important scaling boundaries, though the method relies on existing algorithms (SLERP, ORPO).