📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Visual Instruction Tuning
MM1.5 is a family of multimodal models (1B to 30B) that achieves strong performance in text-rich and fine-grained visual tasks through a meticulous three-stage data mixing strategy.
Core Problem
Developing performant MLLMs is highly empirical, and the precise impact of data mixtures across different training stages (especially for diverse capabilities like OCR, grounding, and multi-image reasoning) remains under-explored.
Why it matters:
- Current open-source models often lack robust visual referring and grounding capabilities compared to proprietary models like GPT-4o
- The specific trade-offs between different data categories (e.g., how adding multi-image data affects single-image performance) are not well-documented
- Efficient scaling of MLLMs to small sizes (1B-3B) for mobile deployment while maintaining high performance is a critical challenge
Concrete Example:
A user asks 'What can I make with these ingredients?' pointing to specific items in an image. Standard models might list generic recipes, but MM1.5 can identify the specific ingredients via coordinates, ground its response with bounding boxes, and reason about the combined items.
Key Novelty
Comprehensive Data-Centric MLLM Training Recipe (MM1.5)
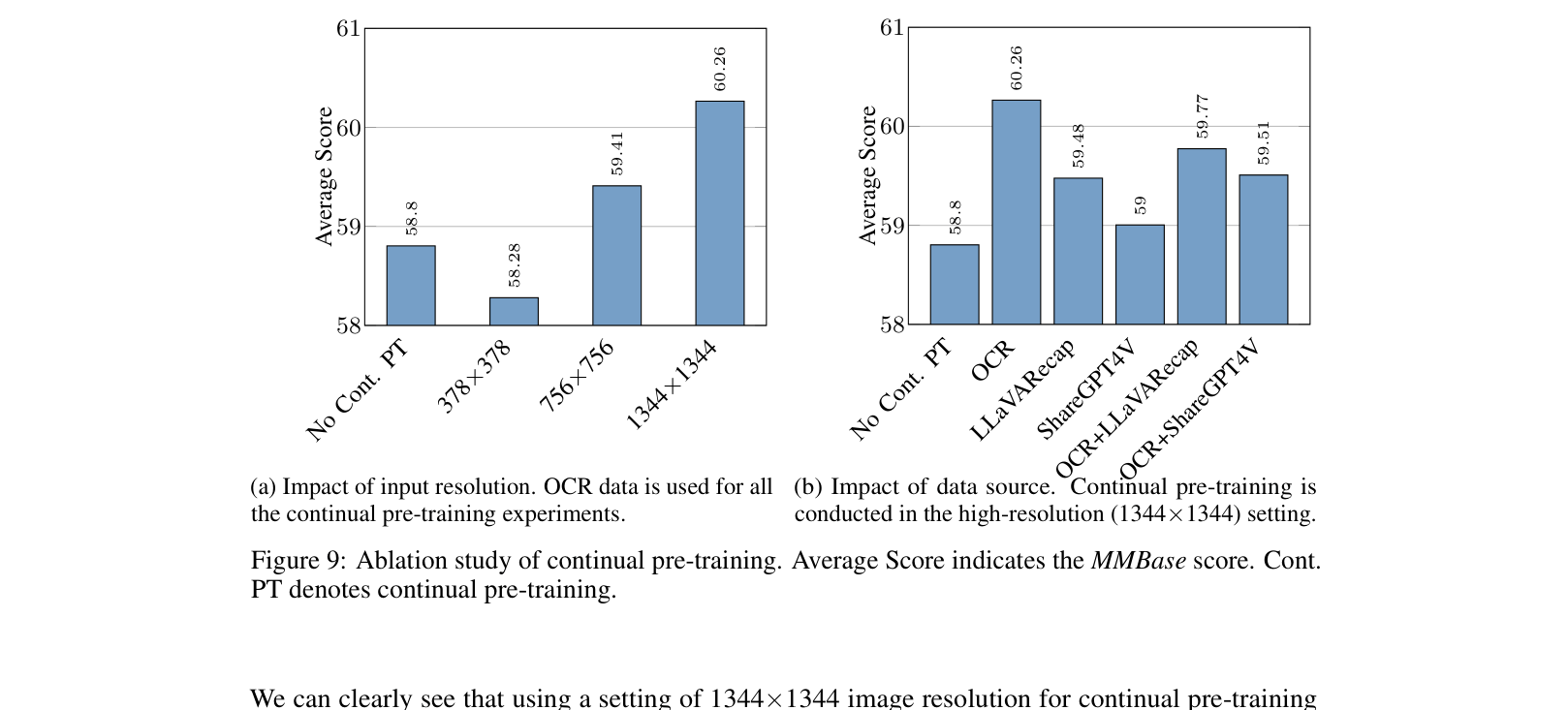
- Introduces a high-resolution 'continual pre-training' stage with OCR data, bridging the gap between coarse pre-training and fine-grained SFT
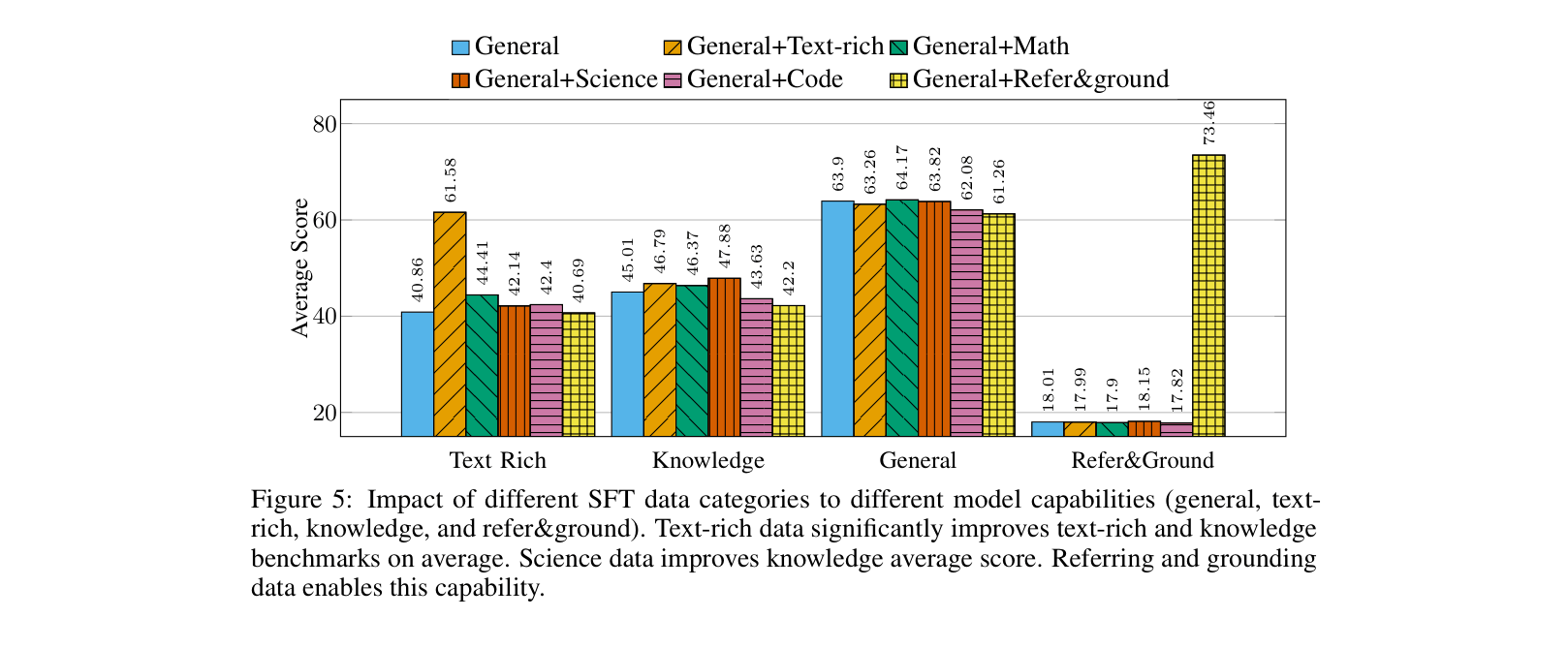
- Optimizes SFT data mixtures by explicitly balancing competing capabilities (general, text-rich, knowledge, grounding) through extensive ablation studies rather than random mixing
- Implements 'dynamic image splitting' (AnyRes) to handle arbitrary aspect ratios and high resolutions (up to 4 Megapixels), maximizing OCR and detail retention
Architecture
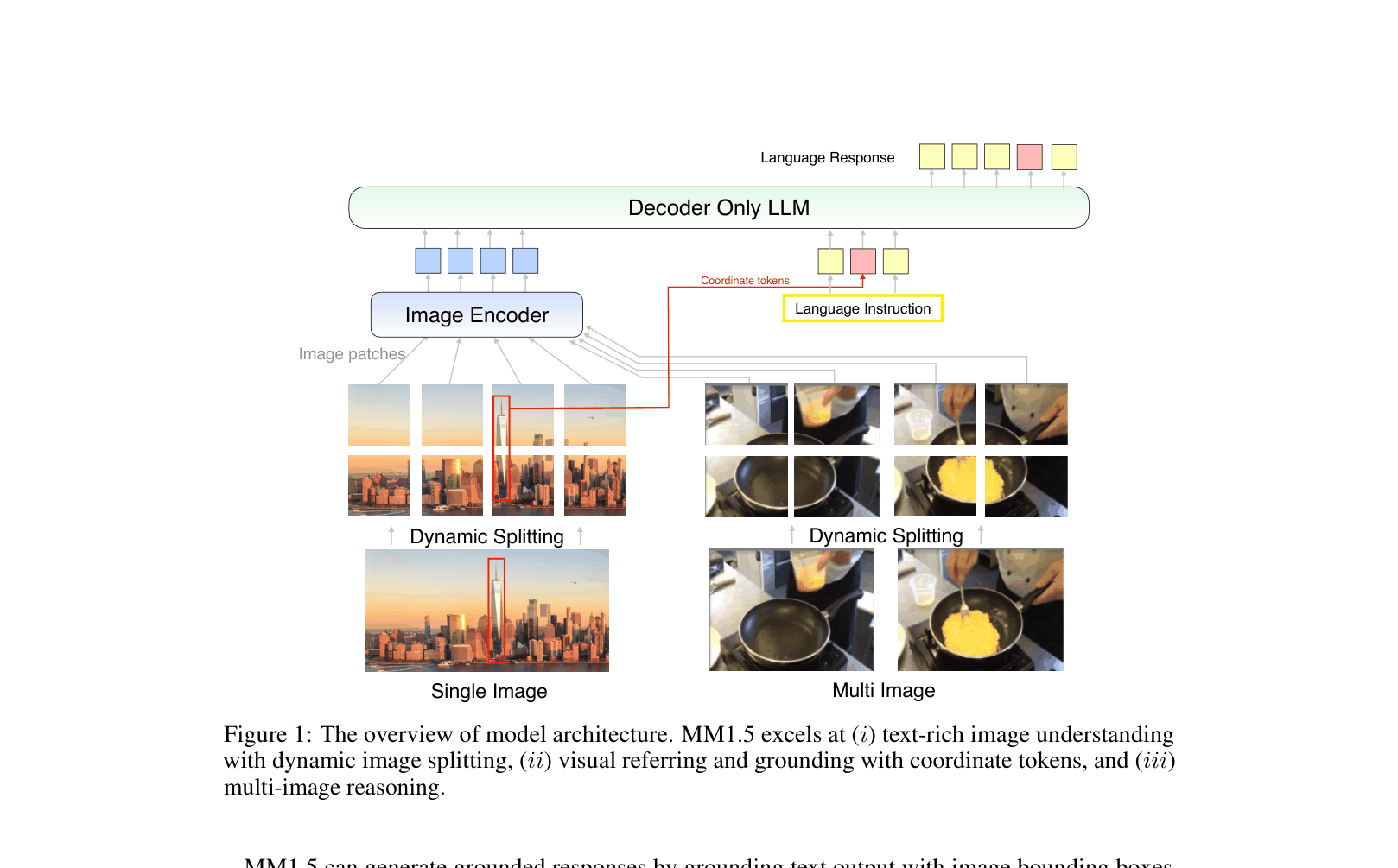
Overview of the MM1.5 architecture highlighting three key capabilities: single-image understanding with dynamic splitting, multi-image reasoning, and visual referring/grounding.
Evaluation Highlights
- MM1.5-3B-Chat achieves 62.6 MMBase score, outperforming larger open-source models like LLaVA-NeXT-8B (60.6)
- MM1.5-30B-Chat achieves 86.6 on MMBench and 65.2 on MMMU, competitive with GPT-4o (69.1 on MMMU) and Gemini 1.5 Pro
- On text-rich benchmarks (DocVQA), MM1.5-30B reaches 91.0, surpassing GPT-4V (88.4) and approaching GPT-4o (92.8)
Breakthrough Assessment
8/10
While the architecture is standard, the rigorous empirical study of data mixtures and the resulting high performance at small scales (1B/3B) provide a highly valuable recipe for the community.