📊 Experiments & Results
Evaluation Setup
Fine-tune an aligned model on a mix of benign (90%) and harmful (10%) data, then evaluate safety and utility.
Benchmarks:
- BeaverTails (Safety Evaluation (Harmful Score))
- SST2 (Sentiment Analysis (Utility))
- AGNEWS (News Classification (Utility))
- GSM8K (Math Reasoning (Utility))
- AlpacaEval (Instruction Following (Utility))
Metrics:
- Harmful Score (HS)
- Finetune Accuracy (FA)
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
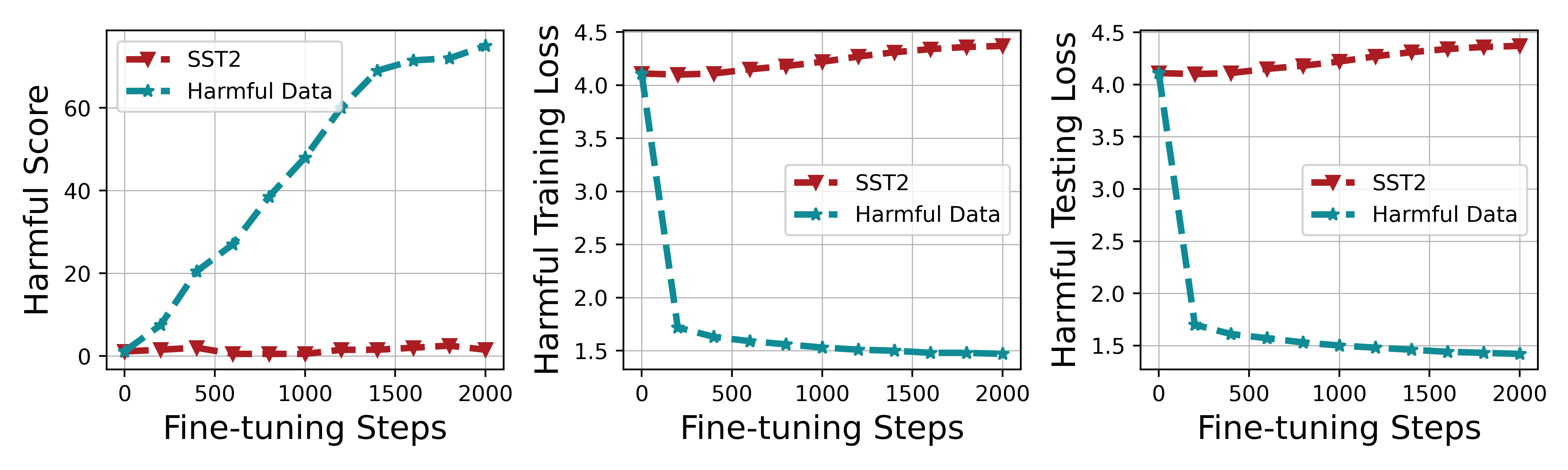
Impact of harmful perturbation on training loss and harmful score.
Main Takeaways
- Harmful perturbation (a gradient step on harmful data) is confirmed as the primary driver of alignment breaking, significantly reducing harmful loss.
- Booster consistently outperforms alignment-stage baselines (Vaccine, RepNoise) by reducing harmful scores by roughly 17-20% relative to baselines.
- The method generalizes across different model architectures (Llama2, Gemma2, Qwen2) and downstream tasks without degrading fine-tuning accuracy.