📝 Paper Summary
Supervised Fine-Tuning (SFT)
Multi-task Learning
Data Composition
This paper analyzes how different SFT data compositions affect LLM abilities and proposes Dual-stage Mixed Fine-tuning (DMT) to balance specialized skills with general human alignment.
Core Problem
Fine-tuning LLMs on composite data (math, code, general instructions) often leads to performance conflicts or catastrophic forgetting, where improving one ability degrades others.
Why it matters:
- Proprietary models like GPT-4 exhibit versatility, but open-source models struggle to maintain specialized skills (reasoning, coding) when fine-tuned for general alignment
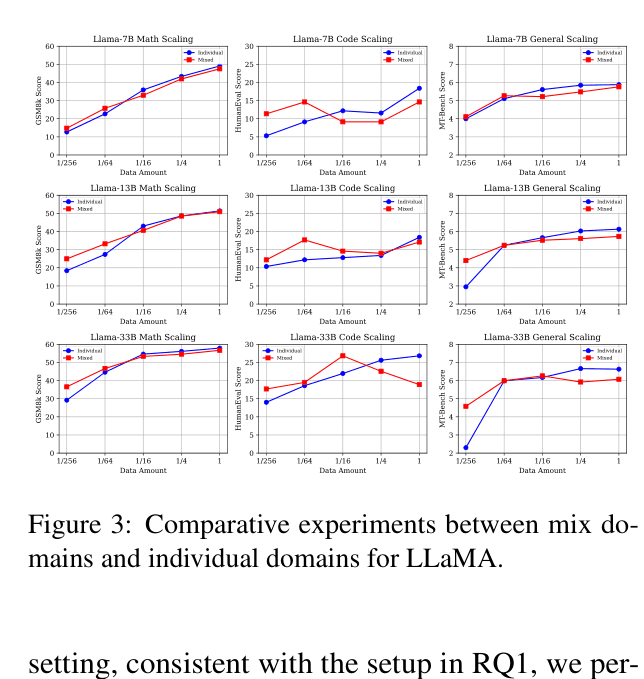
- Directly mixing large datasets creates conflicts in high-resource settings, while sequential training causes models to forget previous tasks
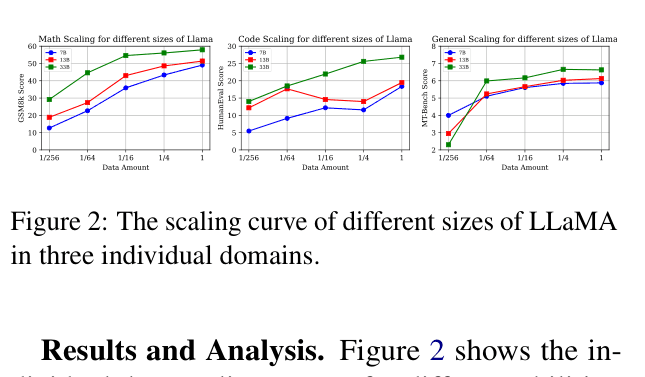
- Understanding scaling laws for SFT data composition is crucial for building versatile open-source LLMs efficiently
Concrete Example:
When LLaMA-33B is trained sequentially (Code/Math first, then General), its math score drops from ~57% (Specialized) to 44.24% due to catastrophic forgetting. Conversely, mixing all data at once degrades general alignment compared to pure general training.
Key Novelty
Dual-stage Mixed Fine-tuning (DMT)
- Splits training into two stages: first maximizing specialized skills (math/code) on their full datasets, then training on general data mixed with a tiny fraction (e.g., 1%) of the specialized data
- Leverages the finding that general abilities saturate quickly (~1k samples) while specialized skills need more data, and that a small 'replay' buffer prevents forgetting during the alignment phase
Architecture
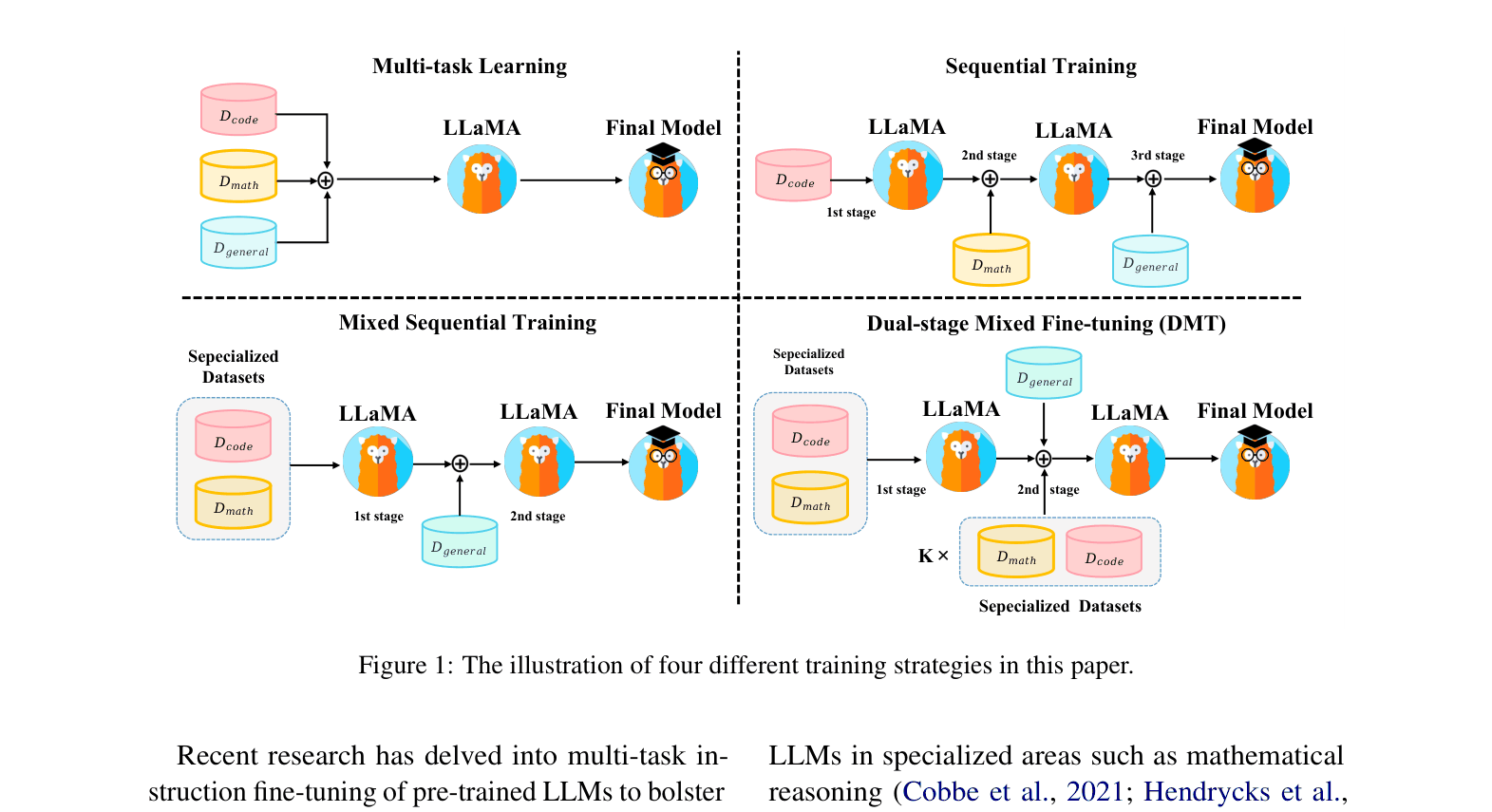
Illustration of four different SFT training strategies: Multi-task Learning, Sequential Training, Mixed Sequential Training, and the proposed Dual-stage Mixed Fine-tuning (DMT).
Evaluation Highlights
- LLaMA-33B with DMT achieves 56.36% on GSM8K, recovering nearly all math ability compared to Sequential Training (47.27%) and approaching the Math-only baseline (57.91%)
- LLaMA-33B with DMT scores 6.73 on MT-Bench, outperforming the Multi-task learning baseline (6.07) and matching the General-only baseline (6.63)
- General human-aligning abilities emerge and plateau with as few as ~1,000 samples (1/64 of ShareGPT), whereas math and code abilities scale log-linearly with data amount
Breakthrough Assessment
7/10
Provides valuable empirical scaling laws for SFT data composition and a practical, simple strategy (DMT) that effectively balances conflicting abilities. High utility for practitioners training general-purpose LLMs.