📝 Paper Summary
Safety Alignment
Fine-tuning Defenses
Adversarial Attacks on LLMs
Lisa mitigates the safety-breaking effects of harmful user fine-tuning by introducing a proximal term to Bi-State Optimization, preventing the model from drifting too far from safe alignment checkpoints.
Core Problem
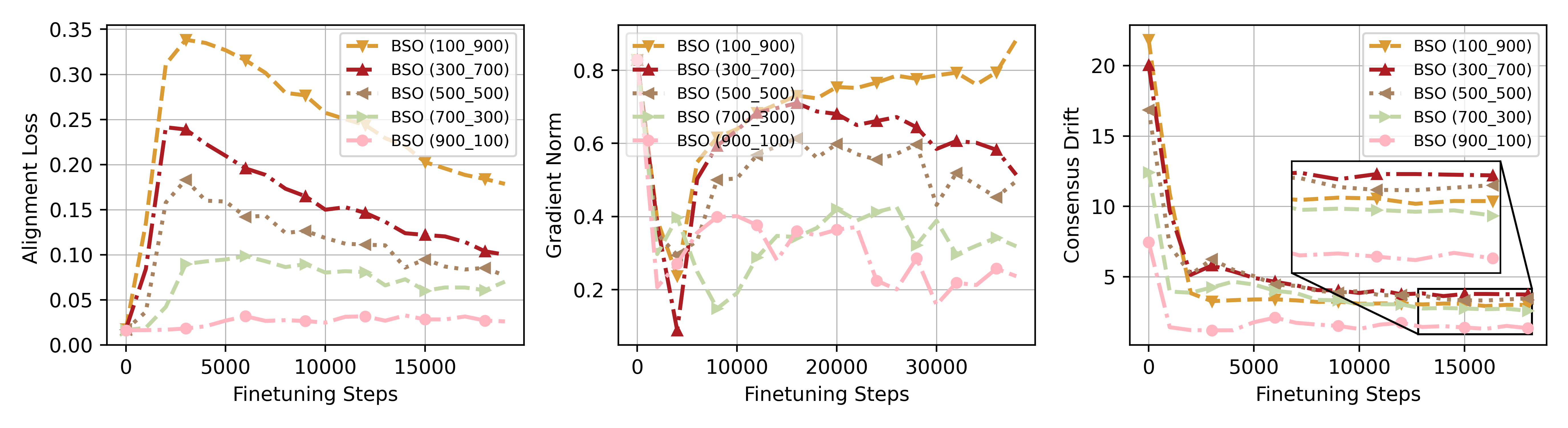
Fine-tuning aligned LLMs on user-provided data (which may contain harmful examples) breaks safety alignment, and standard alternating optimization fails when alignment steps are limited due to excess model drift.
Why it matters:
- Service providers offering fine-tuning APIs (Fine-tuning-as-a-service) are liable if users generate harmful content using their models
- Existing defenses like filtering or retraining are often computationally expensive or fail when the user fine-tuning process is long
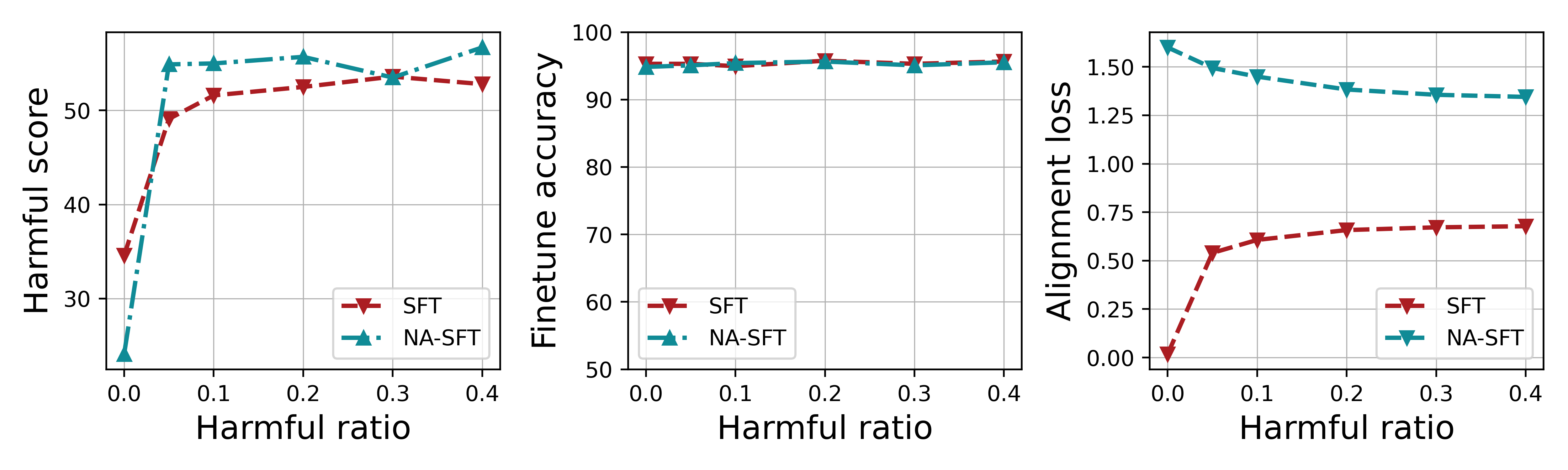
- As little as 5% harmful data in a fine-tuning set can increase a model's harmful score by over 15%
Concrete Example:
A user uploads a fine-tuning dataset containing 10% harmful data (e.g., hate speech mixed with utility tasks). When fine-tuned with asymmetric steps (few alignment steps, many user steps), a standard Bi-State Optimization model drifts significantly, increasing its harmful score by up to 17.6%.
Key Novelty
Lazy Safety Alignment (Lisa)
- Augments Bi-State Optimization (alternating between alignment and user data) with a proximal term in the loss function
- Constrains the model update to remain close (proximal) to the checkpoint from the previous state, preventing 'excess drift' towards the harmful objective
- Allows for asymmetric computing (investing fewer steps in alignment) without catastrophic forgetting of safety features
Architecture
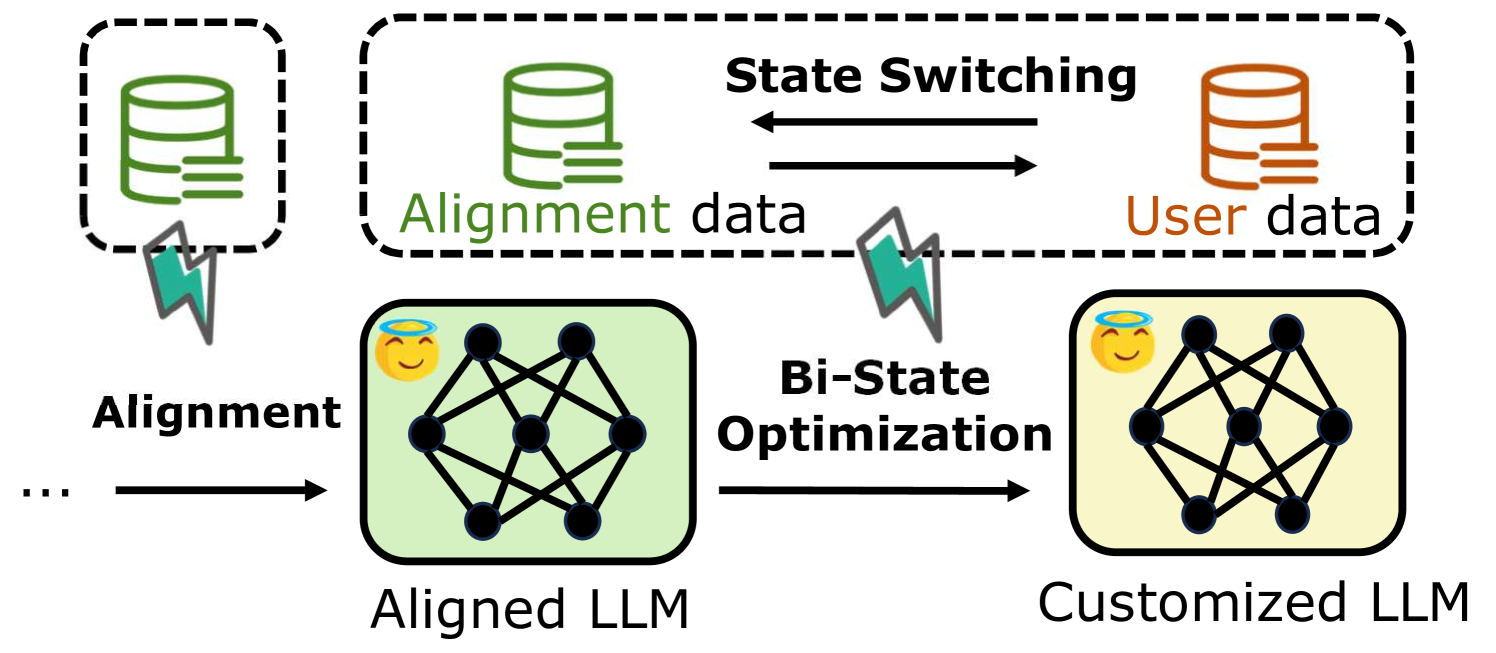
The workflow of Bi-State Optimization (BSO), illustrating the alternating training process between State 1 (Alignment) and State 2 (Fine-tuning).
Evaluation Highlights
- Reduces harmful score by up to 6.54% compared to vanilla Bi-State Optimization (BSO) in asymmetric settings
- Maintains fine-tuning accuracy on user tasks with negligible degradation (maximum 0.43% accuracy loss)
- Vanilla BSO reduces harmful score by up to 4.2% compared to standard Supervised Fine-Tuning (SFT) when computation is balanced
Breakthrough Assessment
7/10
Identifies a specific failure mode (excess drift) in alternating optimization defenses and provides a theoretically grounded, efficient solution (proximal term) that empirically works.