📝 Paper Summary
LLM Safety
Adversarial Attacks
Fine-tuning-as-a-Service
Harmful fine-tuning—where users update aligned models with even a small amount of malicious data—reliably breaks safety guardrails, prompting a new taxonomy of attacks and defenses surveyed here.
Core Problem
Fine-tuning-as-a-service allows users to upload custom data to fine-tune pre-trained models, but including even a small percentage of harmful data can completely erase the model's safety alignment.
Why it matters:
- Service providers face legal liability if their deployed models generate harmful content after user fine-tuning (e.g., California SB-1047 regulations)
- Users may unintentionally upload harmful data, causing safety degradation without malicious intent
- Standard safety alignment (RLHF/SFT) is fragile and easily reversed by fine-tuning, unlike robust defenses needed for commercial APIs
Concrete Example:
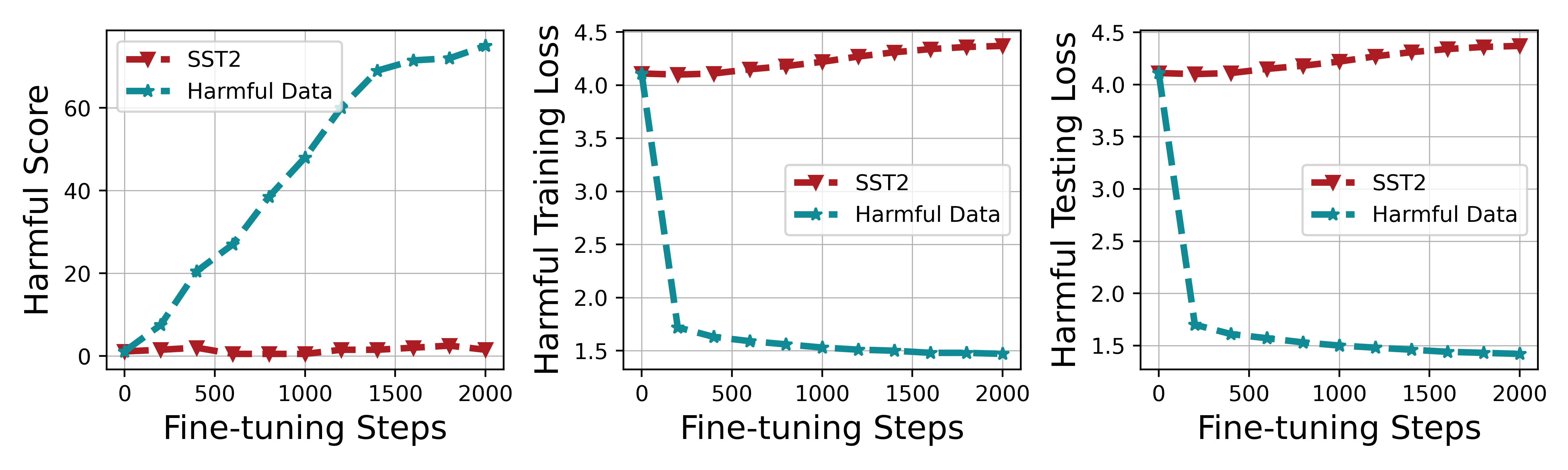
A user uploads a dataset for fine-tuning where 10% of the examples are harmful (e.g., hate speech or bomb-making instructions). The fine-tuned Llama2-7B model, originally safe, now readily answers harmful prompts like 'How to build a bomb?' while maintaining high accuracy on benign tasks.
Key Novelty
Comprehensive Survey of Harmful Fine-tuning
- Systematizes the nascent field of harmful fine-tuning into three pillars: attack settings, defense designs, and evaluation methodologies
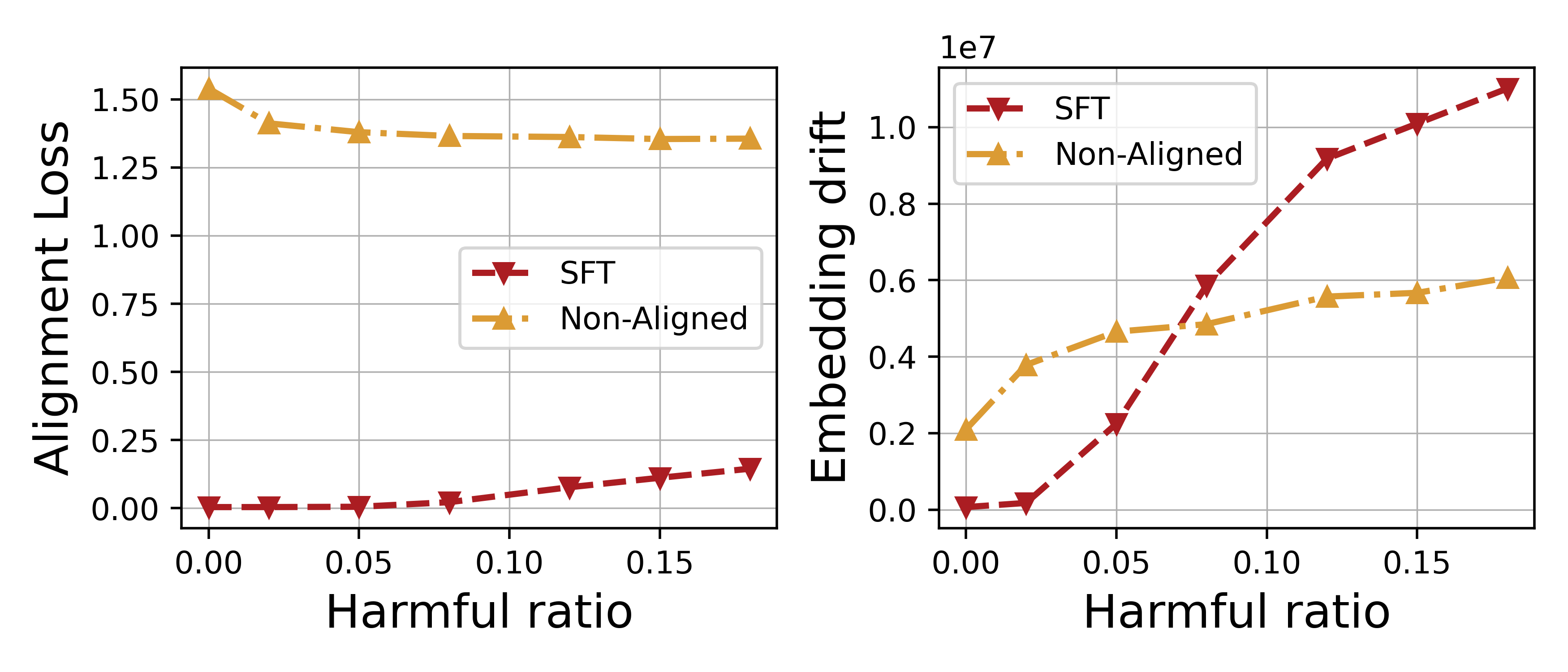
- Identifies two key mechanisms for safety degradation: 'forgetting' of alignment knowledge (increased alignment loss) and 'revitalization' of harmful knowledge (decreased harmful loss)
- Provides a unified evaluation protocol and statistical analysis showing that fine-tuning attacks are stealthy—they break safety without degrading downstream task performance
Architecture
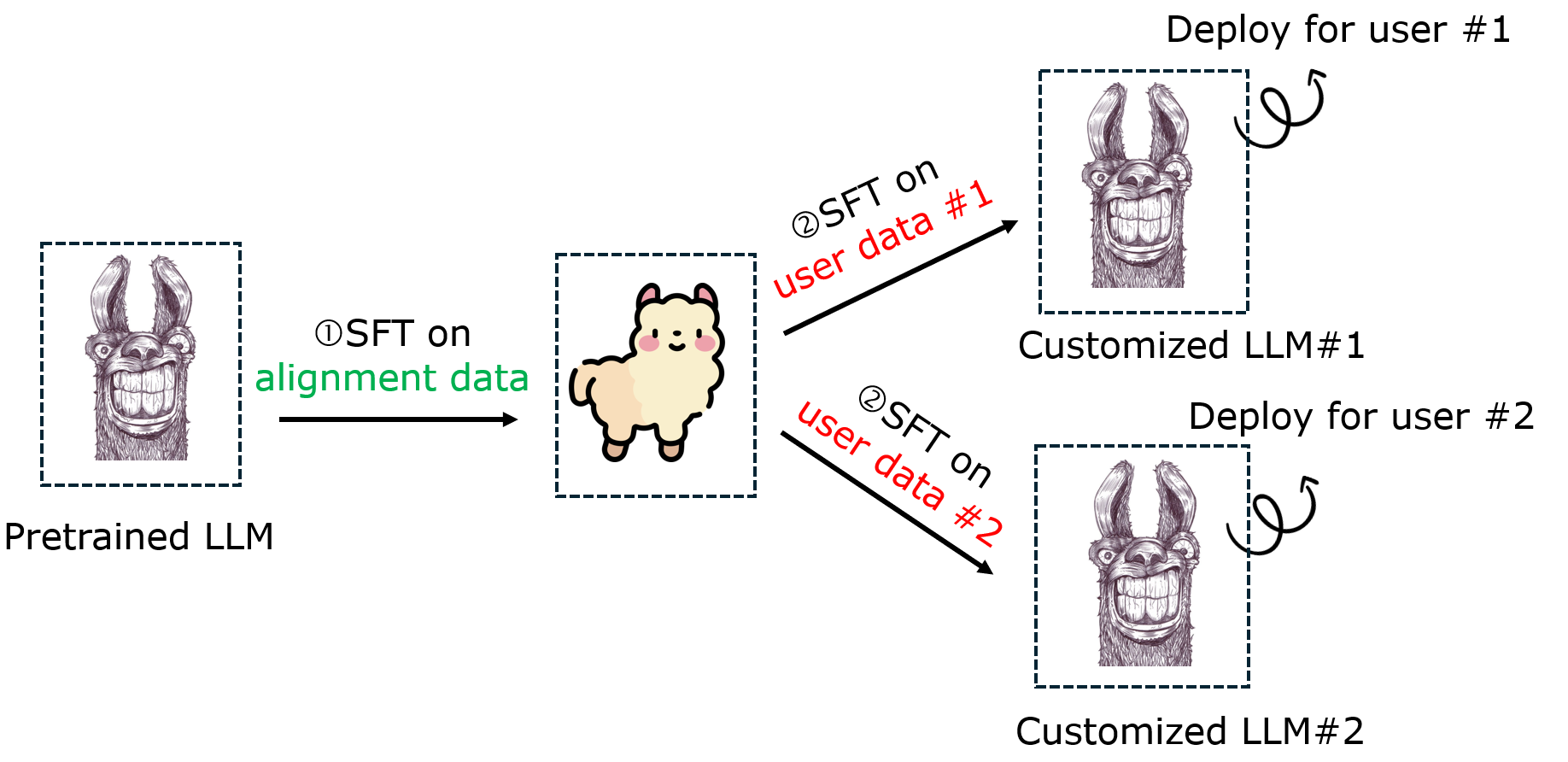
The standard pipeline of fine-tuning-as-a-service and the attack surface
Evaluation Highlights
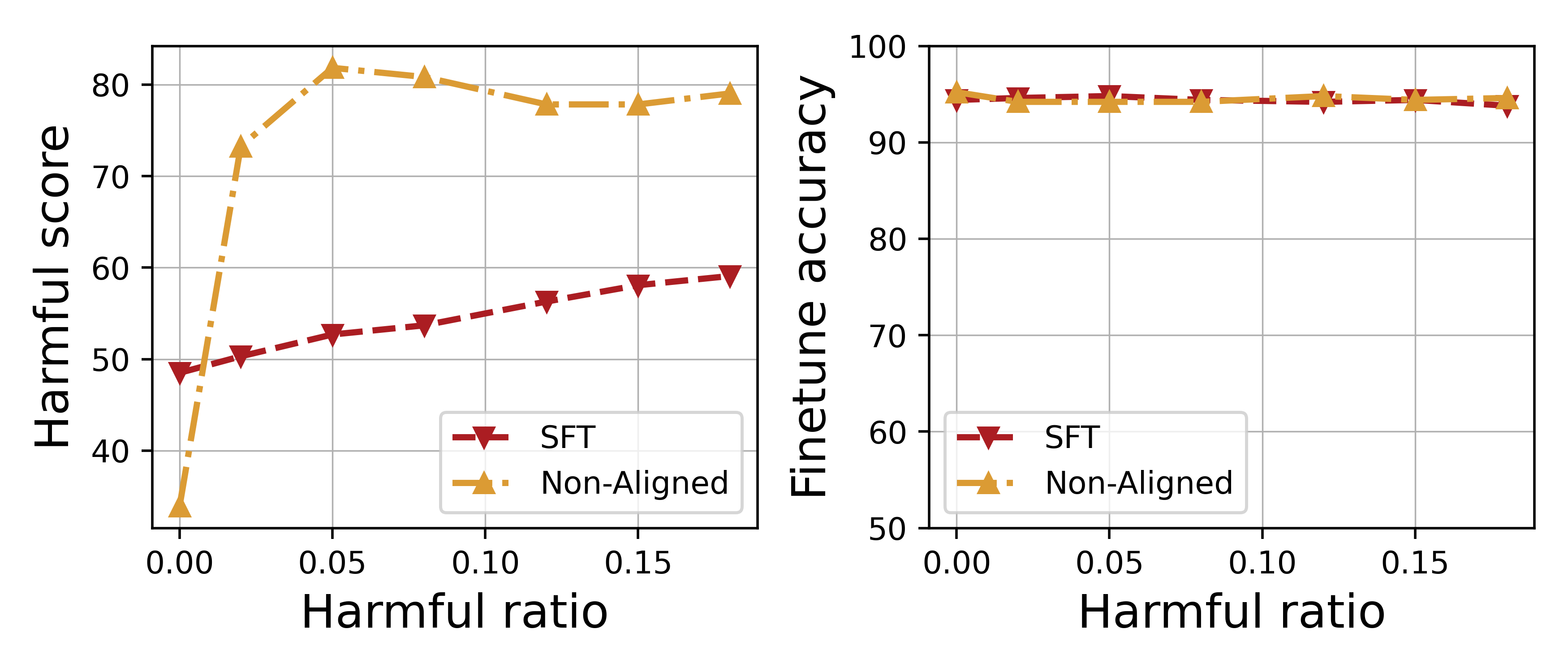
- Fine-tuning Llama2-7B with just 10% harmful data significantly increases the harmful score while maintaining near-constant fine-tune accuracy on SST2
- Harmful fine-tuning causes significant embedding drift away from the aligned model's representation, quantified by Euclidean distance in attention layers
- Training on harmful data reduces harmful loss (fitting harmful patterns) much faster than it increases alignment loss, explaining why safety breaks before utility drops
Breakthrough Assessment
8/10
A timely and necessary systematization of a critical safety vulnerability in commercial LLM services. It clarifies misunderstandings in the field and offers a solid foundation for future research.