📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Optimization algorithms for LLMs
COLA iteratively learns and merges a sequence of low-rank adapter modules into the model weights, approximating a high-rank update without increasing memory usage during training.
Core Problem
While Low-Rank Adaptation (LoRA) is computationally efficient, it often underperforms full parameter fine-tuning in terms of generalization error because the optimal weight updates may not be intrinsically low-rank.
Why it matters:
- Full fine-tuning is computationally prohibitive for large models due to memory constraints
- Existing PEFT methods like LoRA trade off accuracy for efficiency, creating a gap in generalization performance compared to full fine-tuning
- Bridging this gap allows for high-performance adaptation of massive models on consumer hardware
Concrete Example:
When fine-tuning OPT-1.3B on the WSC task, standard LoRA achieves lower accuracy than full fine-tuning because a single low-rank matrix cannot capture the complex weight updates required. COLA fixes this by iteratively learning residuals, improving accuracy by 6.47% relative to LoRA.
Key Novelty
Chain of LoRA (COLA)
- Iterative optimization inspired by the Frank-Wolfe algorithm: instead of learning one static low-rank adapter, COLA learns a sequence of them.
- Residual learning mechanism: after training a LoRA module, it is merged ('tied') into the frozen base model weights, and a new LoRA module is initialized to learn the remaining error (residual).
- Zero memory overhead: by merging modules on the fly, the memory consumption remains identical to training a single standard LoRA adapter.
Architecture
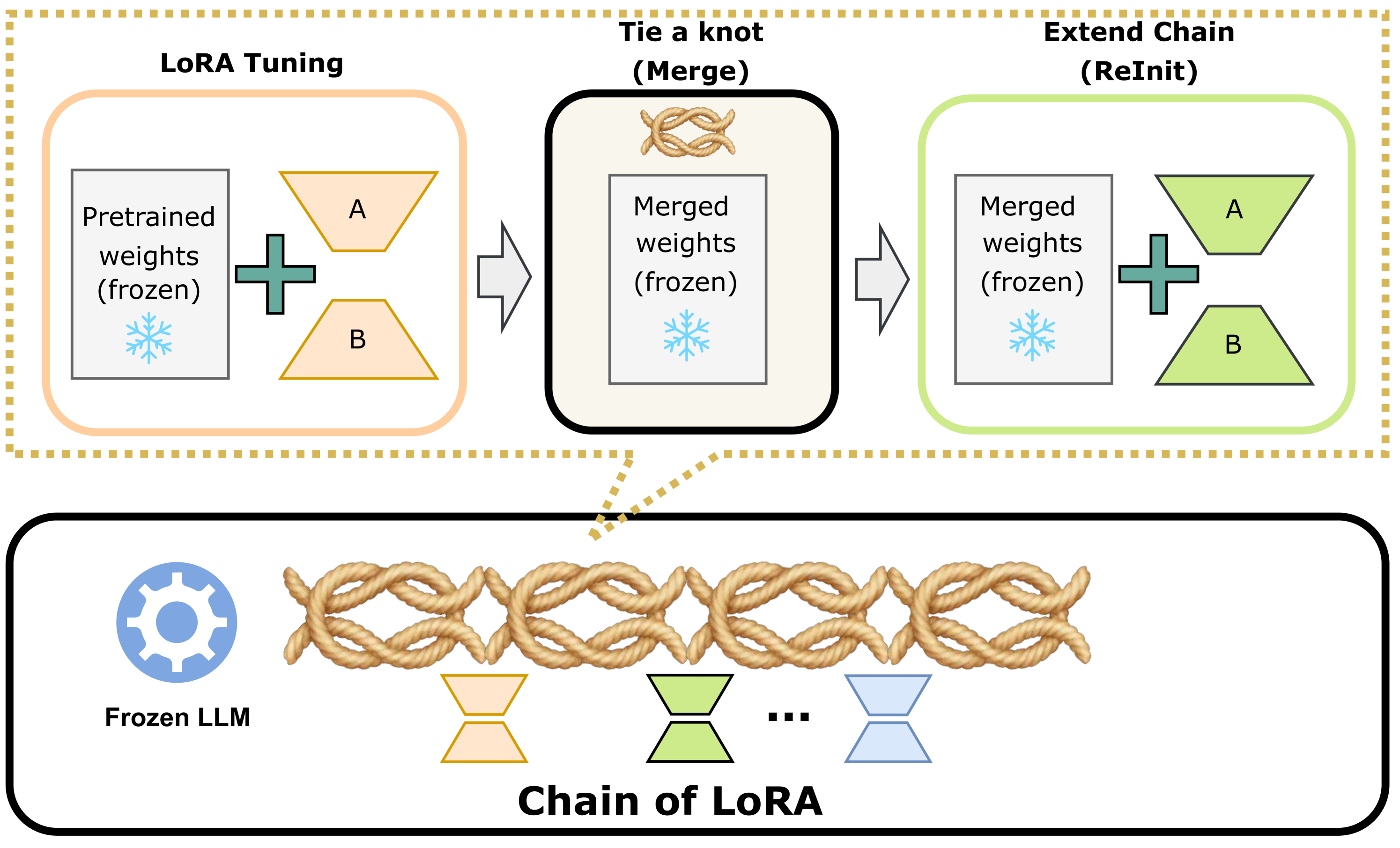
The iterative three-step process of COLA: Tune LoRA, Tie a knot, and Extend the chain.
Evaluation Highlights
- +6.47% relative test accuracy improvement over LoRA for OPT-1.3B on the WSC benchmark
- Up to +4.4% relative test score improvement over LoRA for Llama2-7B on distinct tasks
- Consistently outperforms LoRA across 7 benchmarking tasks without additional computational or memory costs
Breakthrough Assessment
7/10
Offers a theoretically grounded (Frank-Wolfe) improvement over the widely used LoRA method with no memory penalty. While the empirical gains are solid, it is an iterative enhancement rather than a fundamental paradigm shift.