📝 Paper Summary
LLM Fine-Tuning
Safety Alignment
Continual Learning
SDFT mitigates catastrophic forgetting and safety degradation during fine-tuning by rewriting task data into the model's own distribution before training, thereby bridging the distribution gap.
Core Problem
Fine-tuning Large Language Models (LLMs) on downstream tasks causes catastrophic forgetting of general capabilities and safety alignment due to the distribution gap between the task dataset and the pre-trained model.
Why it matters:
- Fine-tuning for specific tasks (e.g., coding) often severely degrades general instruction-following and safety (e.g., jailbreak resistance drops from ~88% to ~54%)
- Preserving the 'seed' model's safety guardrails is critical for deploying fine-tuned models in real-world applications
- Current methods fail to simultaneously enhance task-specific performance and maintain general abilities without complex regularization
Concrete Example:
When Llama-2-chat is fine-tuned on the OpenFunctions dataset to improve tool use, its general coding ability (HumanEval pass@1) drops from 13.4% to 9.8%. Similarly, fine-tuning on GSM8K reduces its resistance to jailbreak attacks from 88.9% to 54.8%.
Key Novelty
Self-Distillation Fine-Tuning (SDFT)
- Instead of training directly on external task data, the model first rewrites the target responses to match its own internal distribution while preserving semantic meaning.
- These self-generated (distilled) responses replace the original targets, creating a training set that aligns with the model's pre-existing knowledge structure.
- Heuristic filtering ensures the distilled responses remain correct (e.g., retaining the correct final answer) before they are used for fine-tuning.
Architecture
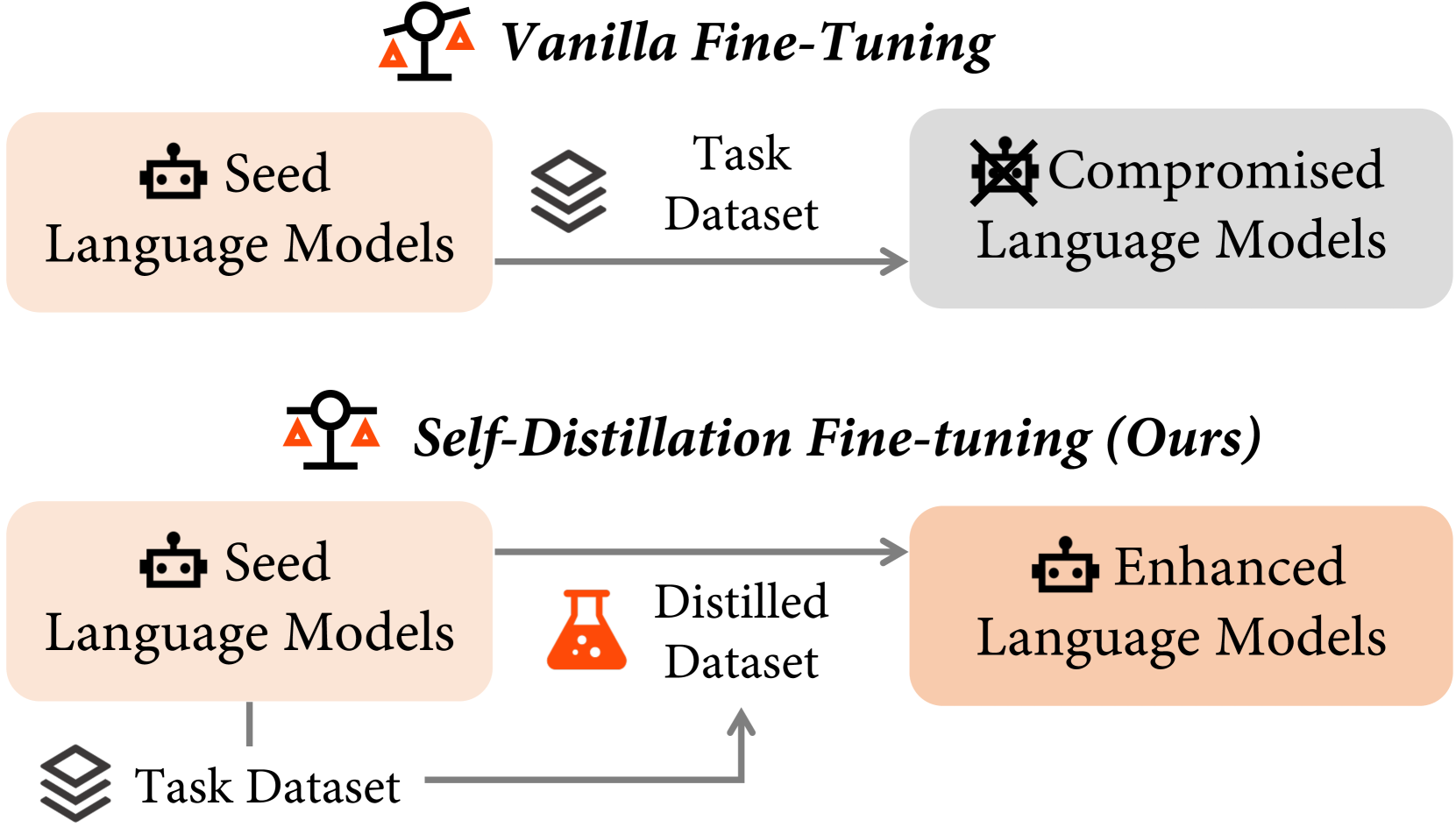
Conceptual workflow of Self-Distillation Fine-Tuning (SDFT).
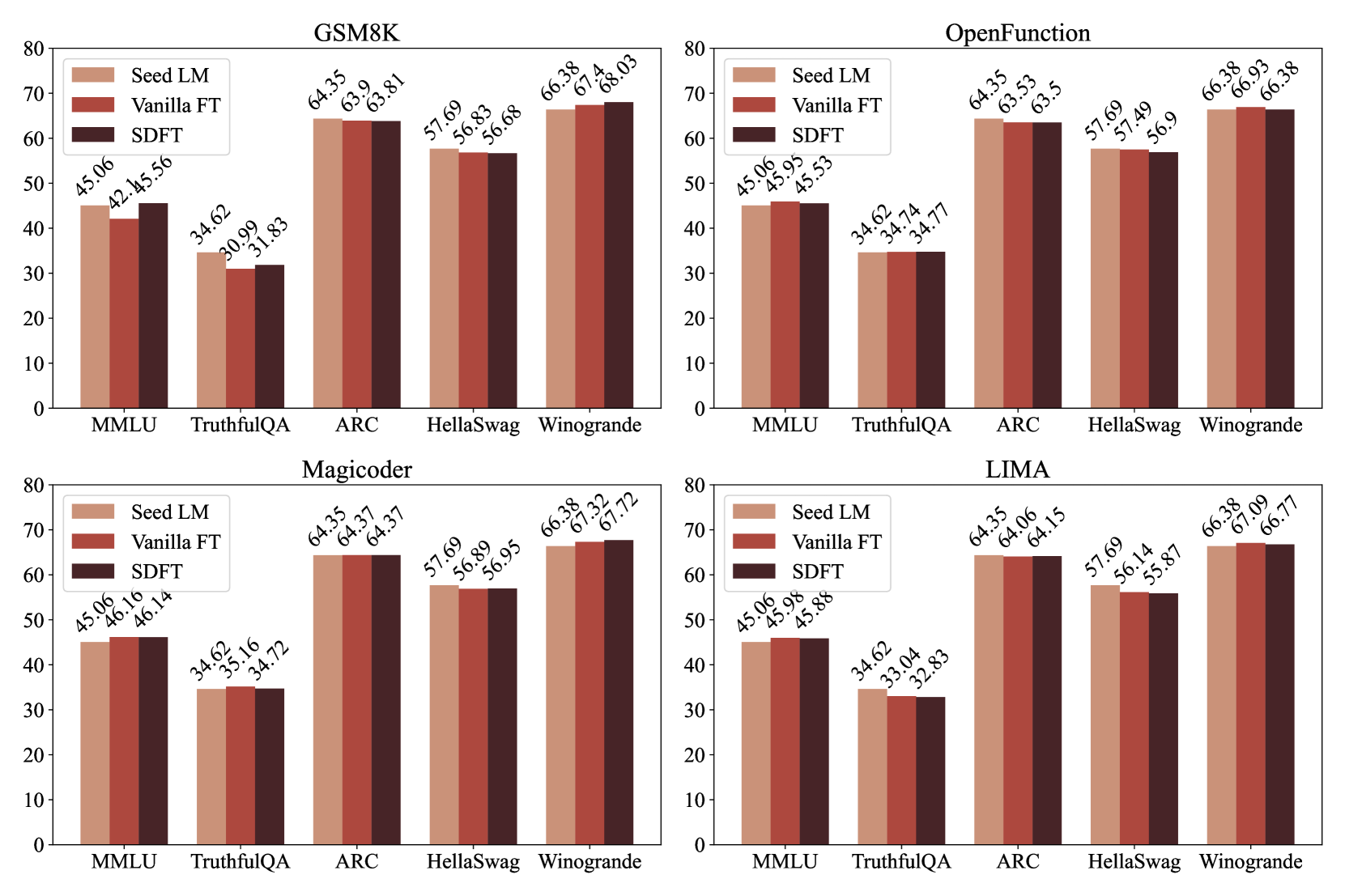
Evaluation Highlights
- Preserves general coding ability: On OpenFunctions fine-tuning, SDFT achieves 15.24% HumanEval pass@1 vs. 9.76% for vanilla fine-tuning (restoring performance to Seed LM levels).
- Restores safety alignment: On GSM8K fine-tuning, SDFT maintains an 80.77% jailbreak safe rate compared to 54.81% for vanilla fine-tuning.
- Maintains general helpfulness: SDFT achieves a 66.73% win rate on AlpacaEval after GSM8K fine-tuning, significantly outperforming vanilla fine-tuning's 23.38%.
Breakthrough Assessment
7/10
Offers a simple, effective data-centric solution to a major problem (safety degradation during fine-tuning). While methodologically straightforward, the impact on safety preservation is substantial.