📝 Paper Summary
Context management
Agentic reasoning
Inference-time scaling
RLMs treat long prompts as external variables in a REPL environment, allowing LLMs to programmatically decompose and recursively process inputs of unbounded length.
Core Problem
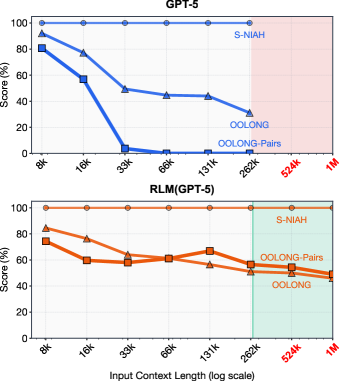
Frontier LLMs suffer from 'context rot' where performance degrades on long inputs, and existing compaction methods lose critical details needed for information-dense tasks.
Why it matters:
- LLMs are increasingly adopted for long-horizon tasks (processing 10M+ tokens) where current context windows are insufficient
- Context compaction (summarization) fails on tasks requiring dense access to specific details throughout the prompt
- Directly feeding long prompts into Transformers is computationally expensive and hits hard architectural limits
Concrete Example:
In the OOLONG-Pairs task (aggregating pairs of chunks), standard GPT-5 achieves <0.1% F1 because it cannot maintain attention over the full sequence. An RLM solves this by programmatically looping over the data and aggregating partial results into a variable, achieving 58.0% F1.
Key Novelty
Recursive Language Models (RLMs)
- Treats the user prompt as a variable in an external REPL environment rather than feeding it directly into the LLM context window
- Enables symbolic recursion: the model writes code to slice the prompt and invoke itself (sub-calls) on those slices to perform semantic work
- Uses a persistent REPL loop to store intermediate results in variables, effectively decoupling memory capacity from the model's context window
Architecture
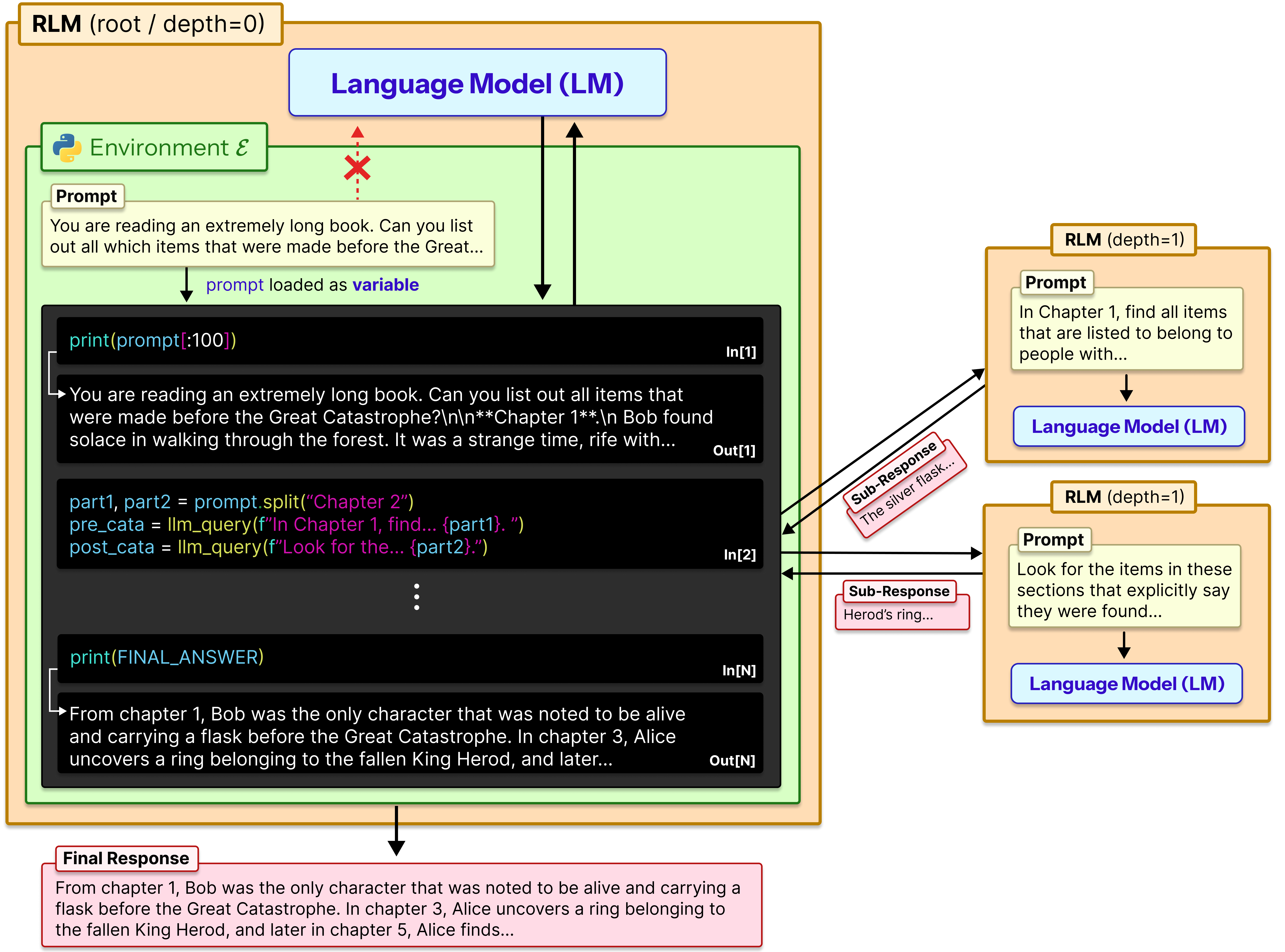
Comparison of Standard LLM, Code Agent, and Recursive Language Model (RLM) workflows.
Evaluation Highlights
- Outperforms vanilla GPT-5 by 28.4% on the linear-complexity OOLONG task while maintaining comparable cost
- Achieves 58.0% F1 on the quadratic-complexity OOLONG-Pairs task where vanilla GPT-5 fails completely (<0.1% F1)
- Fine-tuned RLM-Qwen3-8B outperforms the base Qwen3-8B model by a median of 28.3% across four long-context tasks
Breakthrough Assessment
9/10
Offers a paradigm shift for long-context processing by moving the prompt out of the context window and into an executable environment. Demonstrates orders-of-magnitude scaling on hard tasks where frontier models fail.