📝 Paper Summary
LLM Fine-Tuning Survey
Model Alignment and Optimization
This technical report provides a comprehensive taxonomy and structured pipeline for adapting Large Language Models to specific tasks, comparing fine-tuning strategies against retrieval-augmented generation.
Core Problem
Pre-trained LLMs lack domain-specific knowledge and alignment with specific tasks, while full retraining is computationally prohibitive and requires massive datasets.
Why it matters:
- Generic models often fail to capture the nuance, vocabulary, or privacy requirements of specialized domains like law or medicine
- Organizations need cost-effective ways to customize models without the massive resources required for pre-training from scratch
- There is a need to systematically choose between conflicting adaptation strategies like RAG and fine-tuning based on data availability and task constraints
Concrete Example:
When an organization needs an LLM to answer questions about internal HR policies, a base model will hallucinate. RAG solves this by retrieving current documents, whereas fine-tuning would require retraining on policy data that changes frequently.
Key Novelty
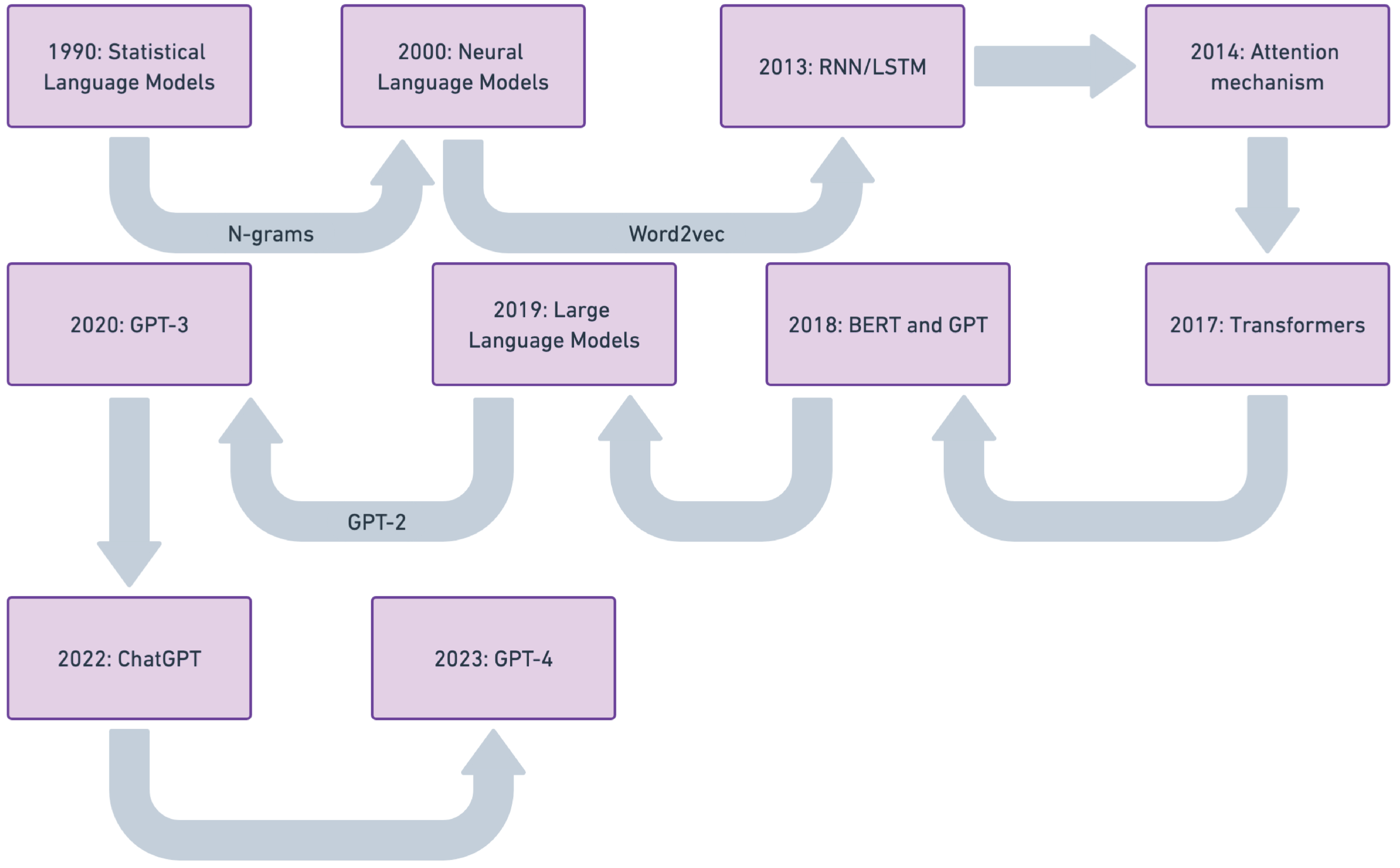
Comprehensive Fine-Tuning Taxonomy and Lifecycle Pipeline
- Establishes a structured seven-stage pipeline covering the entire adaptation lifecycle from data collection and handling imbalances to model initialization and hyperparameter tuning
- Provides a comparative decision framework for choosing between Fine-Tuning (for behavior/style adaptation) and RAG (for external knowledge/factuality)
Architecture
Visual workflow of the RAG (Retrieval-Augmented Generation) architecture
Evaluation Highlights
- Qualitative comparison: Fine-tuning is identified as superior for adapting behavior and writing style, while RAG is superior for suppressing hallucinations and accessing dynamic external data
- Taxonomy classification: Categorizes adaptation methods into Unsupervised, Supervised (SFT), and Instruction-based, alongside efficiency techniques like LoRA and Half Fine-Tuning
- Strategic guidance: RAG is recommended when data changes frequently; fine-tuning is recommended when domain-specific labeled training data is ample
Breakthrough Assessment
4/10
This is a broad survey and guide rather than a research paper proposing a novel algorithm. It organizes existing knowledge effectively but does not introduce new benchmarks or breakthrough methods.