📝 Paper Summary
AI Safety
Parameter-Efficient Fine-Tuning (PEFT)
Safe LoRA mitigates safety degradation during LLM fine-tuning by projecting weight updates onto a pre-computed safety subspace derived from the difference between aligned and unaligned models.
Core Problem
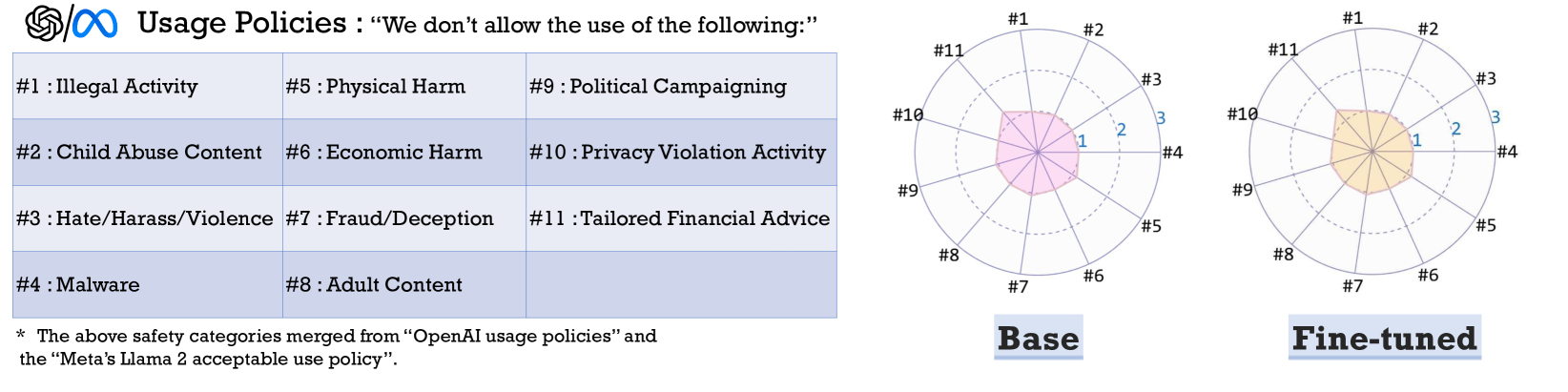
Fine-tuning aligned LLMs, even with benign data, significantly weakens their safety guardrails (alignment), making them susceptible to generating harmful content.
Why it matters:
- Fine-tuning is essential for customizing LLMs to specific domains, but the 'alignment tax' makes deployed models risky.
- Existing alignment methods (RLHF, SFT) are computationally expensive to re-apply after every fine-tuning step.
- Even benign fine-tuning data can inadvertently strip away safety protections embedded during the original training.
Concrete Example:
When an aligned model like Llama-2-Chat is fine-tuned on a downstream task, it may lose its ability to refuse malicious instructions (e.g., 'how to build a bomb'), behaving more like the unaligned base model.
Key Novelty
Safe LoRA (Projection onto Safety Subspace)
- Constructs an 'alignment matrix' by subtracting the weights of an unaligned base model from its aligned chat version.
- Projects the fine-tuning updates (LoRA weights) onto this alignment matrix if they deviate too much from the safety direction.
- Operates as a post-hoc, training-free, and data-free patch that only requires access to model weights.
Architecture
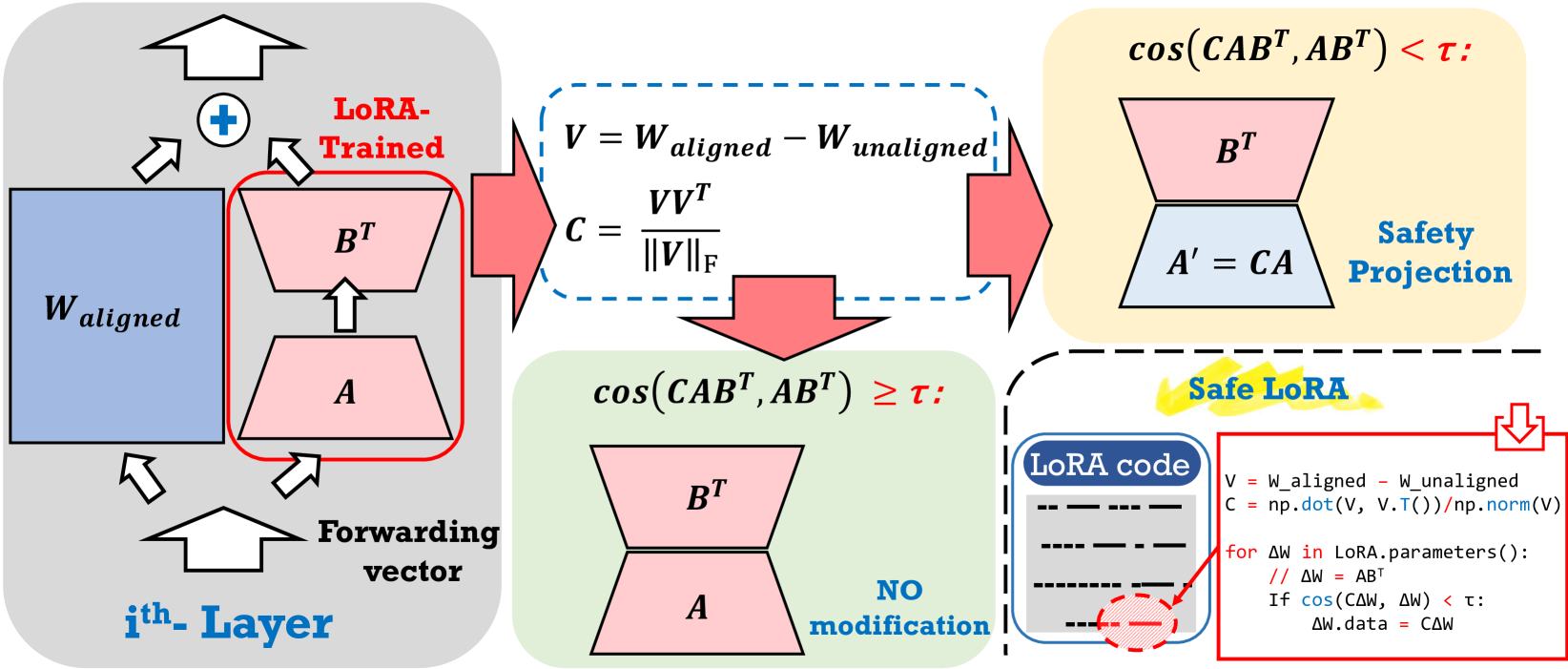
Overview of the Safe LoRA pipeline. It shows the extraction of the alignment matrix V from the difference between Unaligned and Aligned weights, and the subsequent projection of LoRA updates onto this matrix.
Evaluation Highlights
- Llama-2-7B-Chat requires projecting only ~11% of layers to restore safety, while Llama-3-8B-Instruct requires ~35%, indicating different inherent alignment strengths.
- The approximate projection method accelerates the matrix generation process by 250x (from ~2.17s to ~0.0086s) compared to exact inversion, with comparable effectiveness.
- Empirically demonstrates that 'unaligned' models (aligned models fine-tuned on malicious data) behave nearly identically to original base models in terms of harmfulness scores.
Breakthrough Assessment
7/10
A simple, mathematically grounded heuristic that effectively solves a major safety problem in fine-tuning without requiring new training data or complex optimization.