📝 Paper Summary
Offline-to-Online Reinforcement Learning
Policy Fine-tuning
Cal-QL conditions conservative offline value functions to be lower-bounded by the value of a reference policy, ensuring Q-values match the scale of true returns to prevent policy unlearning during online fine-tuning.
Core Problem
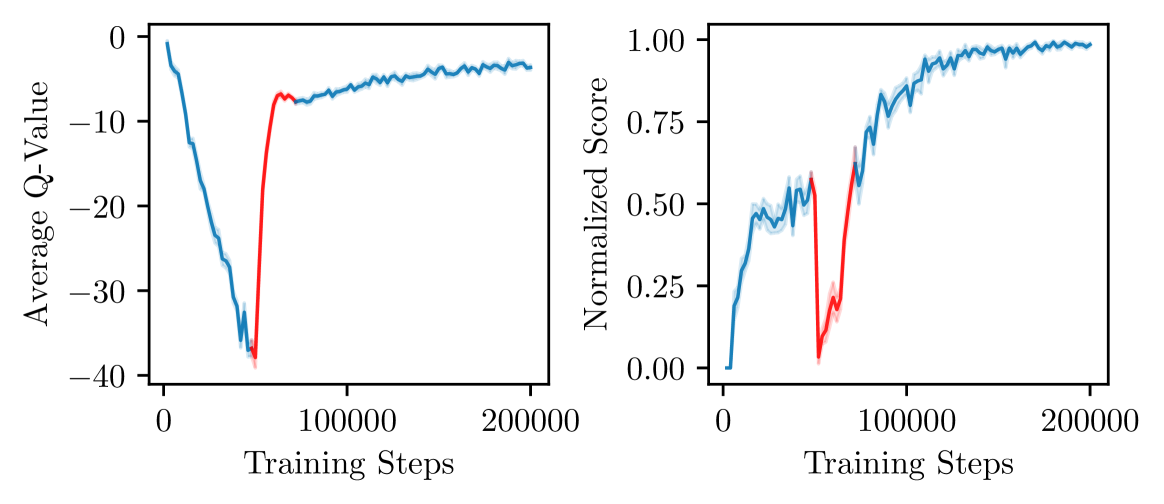
Conservative offline RL methods underestimate Q-values. During fine-tuning, exploration actions with true returns higher than these underestimates (but lower than the optimal policy) falsely appear superior, causing the agent to 'unlearn' the good pre-trained policy.
Why it matters:
- Offline-to-online RL aims to speed up learning, but 'unlearning' forces the agent to waste expensive online samples just to recover the initial offline performance.
- Existing methods often perform worse than training from scratch or fail to improve upon the offline initialization due to scale mismatches in value estimation.
Concrete Example:
In a visual pick-and-place task, CQL learns a policy with ~50% success but estimates its value conservatively at 0.1 (true value 1.0). When fine-tuning starts, a random exploration action yields a return of 0.2. The agent sees 0.2 > 0.1 and updates its policy towards the random action, causing success to drop to 0% until the value function scale corrects itself.
Key Novelty
Calibrated Q-Learning (Cal-QL)
- Constrains the learned conservative Q-function to be at least as large as the value of a reference policy (e.g., the behavior policy) whose value can be estimated reliably.
- Ensures Q-values lie on a realistic scale (calibrated) rather than being arbitrarily small due to conservatism, preventing the optimizer from favoring suboptimal exploration actions during fine-tuning.
Architecture
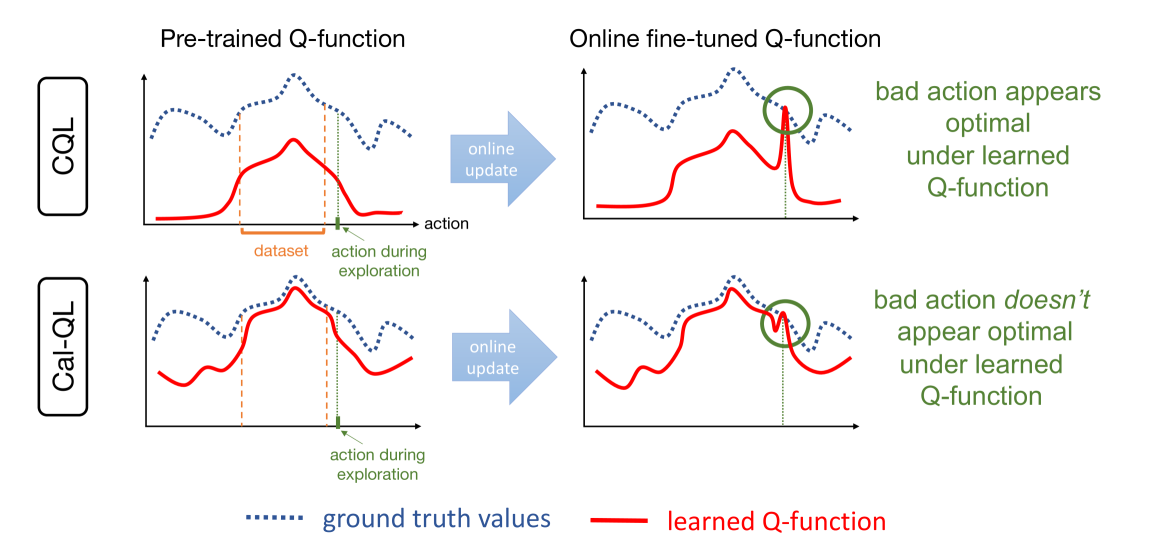
Conceptual illustration of the 'Unlearning' phenomenon and how Calibration fixes it.
Evaluation Highlights
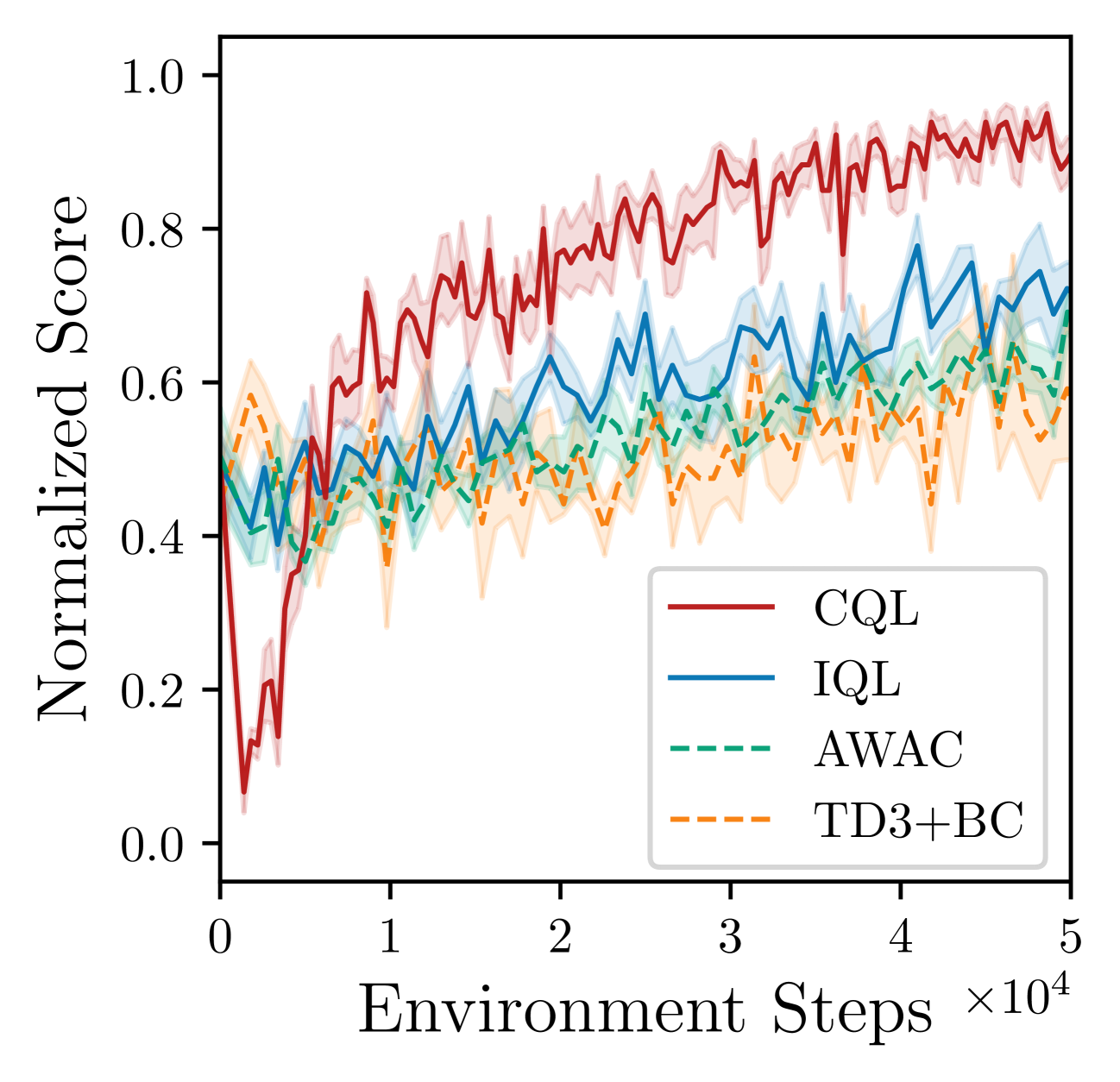
- Outperforms state-of-the-art methods (including CQL, IQL, TD3+BC) on 9 out of 11 fine-tuning benchmark tasks.
- Achieves performance gains of 30-40% over baselines on difficult robotic manipulation and navigation tasks.
- Eliminates the initial performance drop ('unlearning') observed in CQL, enabling immediate improvement during the online phase.
Breakthrough Assessment
8/10
Identifies and solves a critical, specific failure mode ('unlearning') in offline-to-online RL with a theoretically grounded yet simple fix (calibration), showing strong empirical gains.