📝 Paper Summary
LLM Training Frameworks
Efficient Fine-Tuning (PEFT)
SWIFT is a comprehensive, open-source infrastructure unifying training, inference, evaluation, and deployment for over 550 LLMs and 200 MLLMs, featuring specialized support for multi-modal and agentic tasks.
Core Problem
Training and deploying Large Language Models (LLMs) and Multi-modal LLMs (MLLMs) is fragmented, with existing solutions often lacking support for newer models, multi-modal tasks, or integrated post-training workflows like quantization and deployment.
Why it matters:
- Developers face high barriers trying to align different libraries for training, inference, and evaluation, especially for rapidly evolving multi-modal models.
- Existing frameworks often have limited model support or lack end-to-end capabilities (e.g., stopping at training without deployment support), slowing down practical adoption.
Concrete Example:
A developer wanting to fine-tune a new multi-modal model like Qwen2-VL often has to write custom data processing code and handle compatibility issues between training and inference libraries manually. With SWIFT, they can use a single command line interface to fine-tune, evaluate, and deploy the model using standardized templates.
Key Novelty
One-Stop Infrastructure for Universal LLM/MLLM Tuning
- Unified interface for over 750+ models (LLMs and MLLMs) covering pre-training, SFT, RLHF, and inference, eliminating the need for model-specific adaptation code.
- Seamless integration of training with downstream tasks like evaluation, quantization (e.g., AWQ, GPTQ), and deployment (vLLM, LMDeploy) in a single workflow.
- Specialized support for Agent training via customized datasets (MSAgent-Pro) and loss-scale techniques, optimizing tool-use capabilities.
Architecture
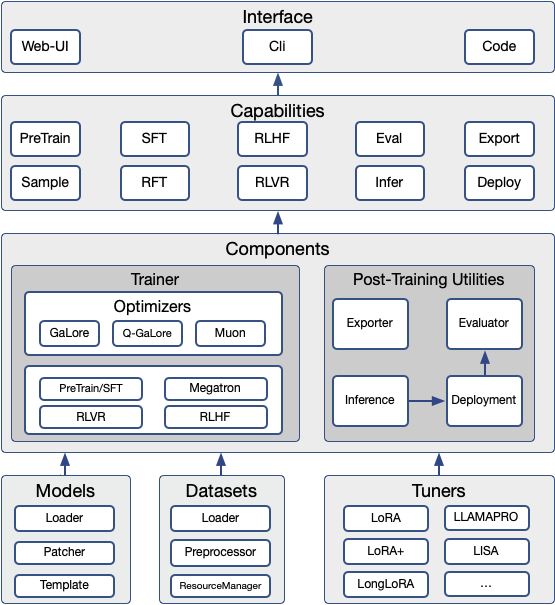
The overall architecture of the SWIFT framework, detailing the flow from Models/Datasets through Training/Tuning to Deployment.
Evaluation Highlights
- +5.2% to +21.8% improvement in Act.EM metric on ToolBench leaderboard using customized agent datasets trained with SWIFT.
- Reduction in hallucination by 1.6% to 14.1% for agentic tasks compared to baseline models.
- Average performance improvement of 8% to 17% on agent frameworks when fine-tuned using SWIFT's specialized data and loss scaling.
Breakthrough Assessment
8/10
SWIFT stands out for its massive scale of support (550+ LLMs, 200+ MLLMs) and being the first framework to offer systematic, end-to-end support for Multi-modal LLMs, effectively bridging the gap between research models and production deployment.