📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Large Language Models
The paper presents an empirical framework identifying optimal placements and configurations for PEFT modules (adapters and LoRA) within open-source LLMs to maximize performance on math and commonsense reasoning tasks.
Core Problem
Full model fine-tuning of LLMs is computationally expensive, and while PEFT methods exist for older models like BERT, the optimal configuration and placement of adapters for modern decoder-only LLMs (like LLaMA) remains unclear.
Why it matters:
- Fine-tuning massive models (e.g., 175B parameters) is inaccessible to most researchers due to hardware constraints
- Improper placement of adapters in decoder-only architectures leads to suboptimal performance, wasting the potential of efficient tuning
- Lack of unified frameworks and high-quality instruction data hinders comparative research on PEFT methods for reasoning tasks
Concrete Example:
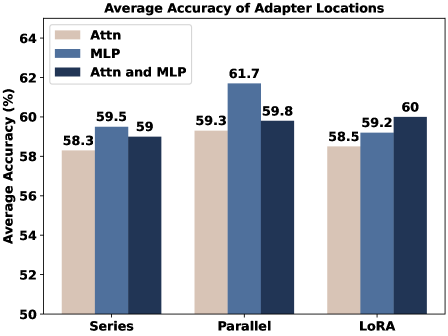
When fine-tuning LLaMA-7B for math reasoning, inserting a Series Adapter after the attention layer yields lower performance compared to inserting it after the MLP layer (59.5% accuracy). Similarly, applying LoRA only to attention layers underperforms compared to applying it to both attention and MLP layers (60% accuracy).
Key Novelty
Unified PEFT Framework & Empirical Placement Study
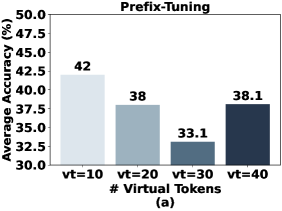
- Develops 'LLM-Adapters', a framework integrating Series Adapters, Parallel Adapters, LoRA, and Prefix Tuning into various open-source LLMs
- Conducts a systematic ablation study to determine the specific layer locations (Attention vs. MLP vs. Both) that yield the highest reasoning performance for each adapter type
- Constructs two specialized datasets (Math10K and Commonsense170K) using ChatGPT to generate rationales and consistent formatting for instruction tuning
Architecture
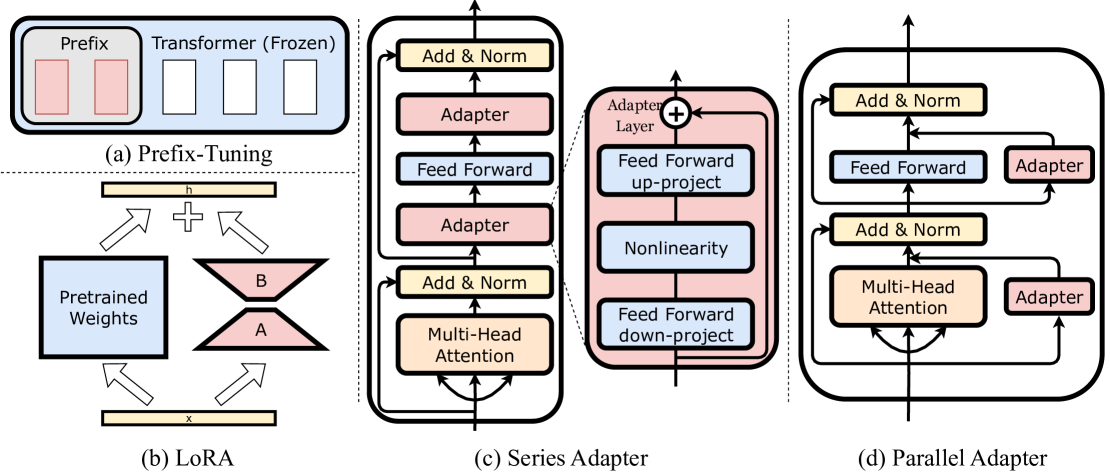
Conceptual illustration of different PEFT methods (Series Adapter, Parallel Adapter, LoRA, Prefix Tuning) and how they integrate into a Transformer block.
Evaluation Highlights
- Parallel Adapters (placed parallel to MLP layers) achieve the highest average accuracy of 61.7% on math reasoning tasks with LLaMA-7B
- LoRA achieves 60.0% average accuracy on math reasoning when applied to both Attention and MLP layers, outperforming Series Adapters (59.5%)
- LLaMA-13B with LoRA outperforms GPT-3.5 (>175B) on specific arithmetic datasets like MultiArith and AddSub [qualitative claim in paper]
Breakthrough Assessment
7/10
Solid empirical contribution clarifying 'best practices' for PEFT on modern LLMs. While not proposing a radically new architecture, the systematic benchmarking and dataset release are highly valuable for the community.