📝 Paper Summary
Text-to-Image Generation
RLHF (Reinforcement Learning from Human Feedback)
DPOK fine-tunes text-to-image diffusion models using online reinforcement learning with KL regularization to maximize human-aligned rewards while preserving image quality.
Core Problem
Supervised fine-tuning of diffusion models on fixed reward-weighted datasets often degrades image quality (e.g., oversaturation) and fails to fully optimize human alignment rewards.
Why it matters:
- Current text-to-image models struggle with specific requirements like counting, attribute binding, and compositionality
- Supervised fine-tuning on static datasets limits the model's ability to explore and maximize rewards beyond the pre-trained distribution
- Without proper regularization, maximizing reward models often collapses image diversity or fidelity (reward hacking)
Concrete Example:
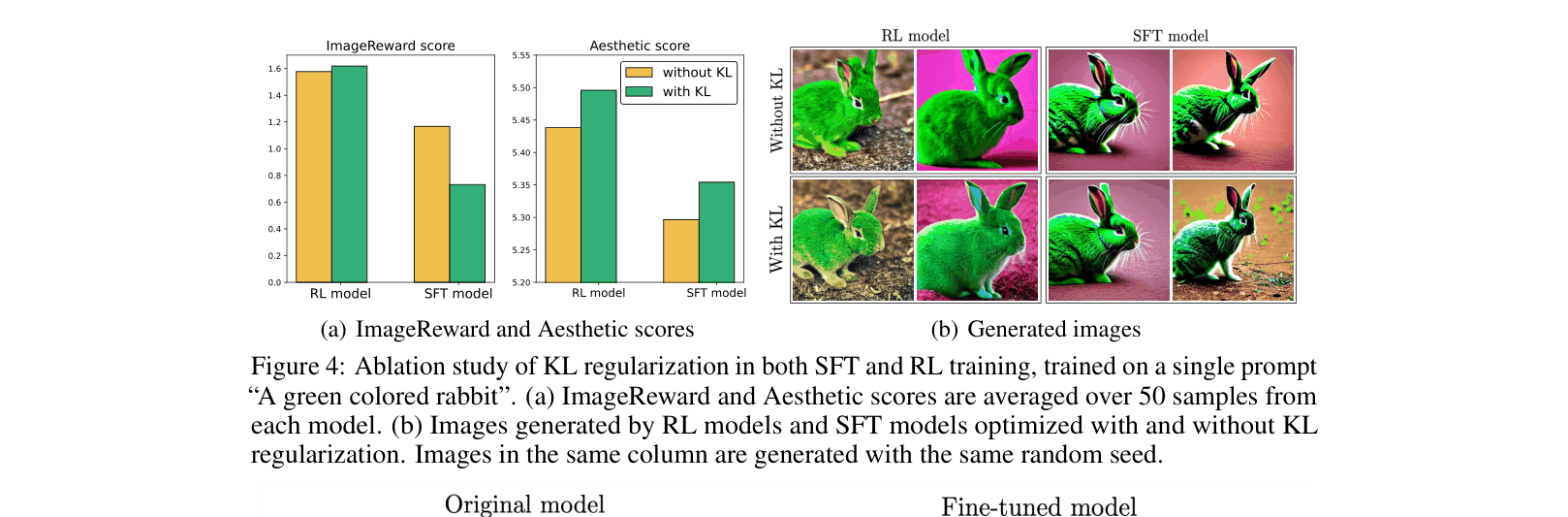
When fine-tuning on the prompt 'A green colored rabbit', supervised methods often produce over-saturated, unnatural images. The original model also biases prompts like 'Four roses' to whiskey bottles rather than flowers.
Key Novelty
Diffusion Policy Optimization with KL regularization (DPOK)
- Frames the diffusion denoising process as a multi-step MDP where the policy is the denoising network and the reward is given only at the final image step
- Updates the model using Policy Gradient (REINFORCE) on online samples generated by the current model, allowing it to explore new high-reward regions
- incorporates KL divergence from the pre-trained model as an implicit reward to prevent mode collapse and preserve image fidelity
Architecture
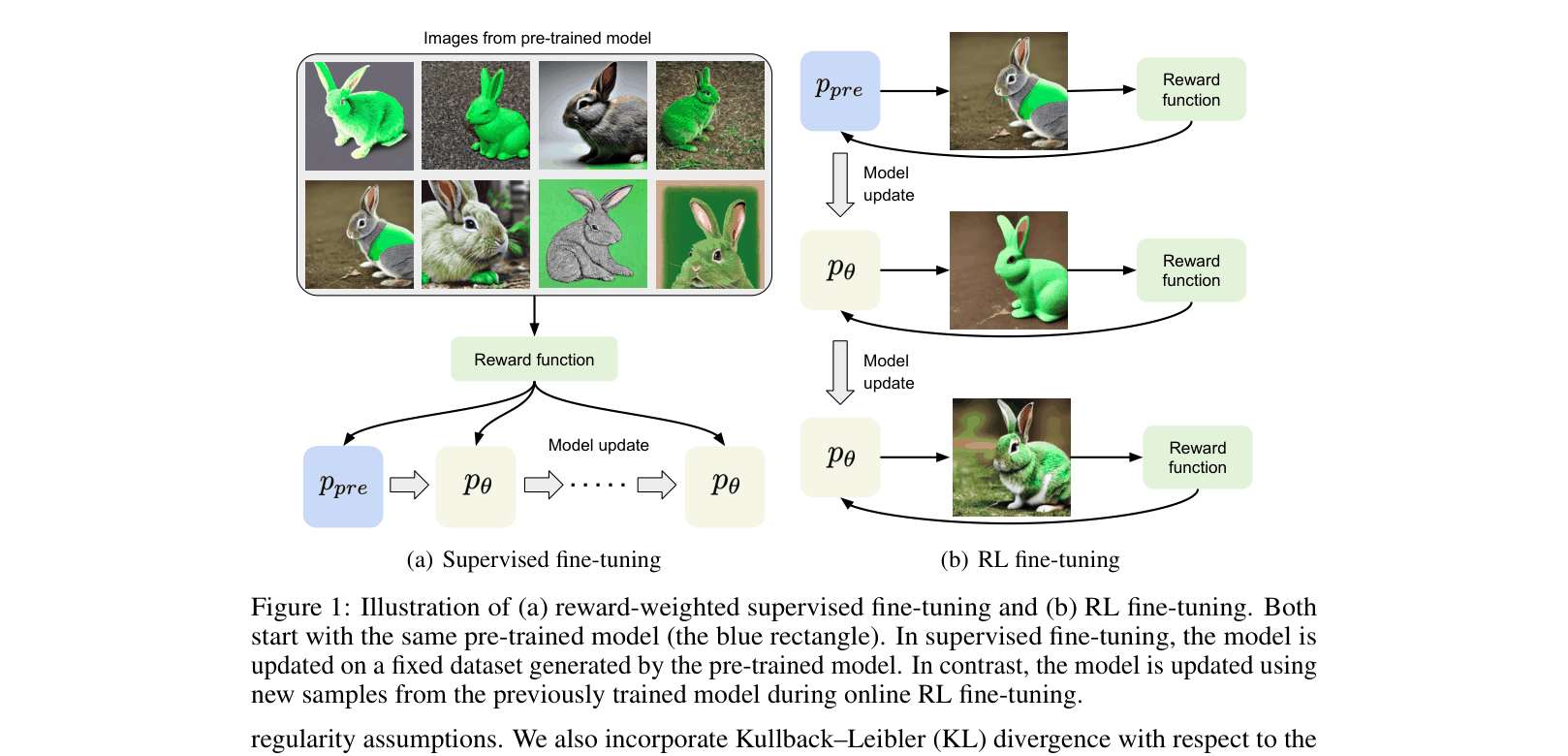
Conceptual comparison between Supervised fine-tuning and RL fine-tuning workflows.
Evaluation Highlights
- Outperforms Supervised Fine-Tuning (SFT) in human evaluation, with win rates of ~70% for alignment and ~60% for image quality on test prompts
- Increases ImageReward score from 0.13 to 0.58 on Drawbench prompts while maintaining aesthetic quality
- Corrects dataset bias: Fine-tuning on 'Four roses' shifts generation from whiskey bottles to flowers (ImageReward -0.52 → 1.12)
Breakthrough Assessment
8/10
Significant step in applying online RL to large-scale diffusion models. Demonstrates that online exploration outperforms supervised methods for alignment, addressing a key limitation in generative AI fine-tuning.