📝 Paper Summary
Diffusion Model Fine-tuning
Alignment with Human Preferences
DRaFT fine-tunes diffusion models by backpropagating differentiable reward gradients directly through the sampling process, using truncation and variance reduction to achieve efficiency superior to reinforcement learning.
Core Problem
Diffusion models trained to match data distributions often fail to generate aesthetically pleasing images, and existing alignment methods like Reinforcement Learning (RL) are sample-inefficient while standard backpropagation is memory-prohibitive.
Why it matters:
- Generative models need to satisfy complex human preferences (e.g., aesthetics) that are not captured by simple likelihood maximization on web data
- RL-based fine-tuning ignores analytic gradients of differentiable reward functions, discarding useful information and slowing down training
- Optimizing the latent noise (like DOODL) requires expensive optimization at inference time for every new prompt, whereas model fine-tuning amortizes this cost
Concrete Example:
When a user prompts for an image, a standard model might generate a realistic but unappealing image. To fix this, methods like DOODL optimize the specific noise input for that one image (slow at inference), while RL methods treat the reward as a black box (slow to train). DRaFT updates the model weights directly using the reward's gradient.
Key Novelty
Direct Reward Fine-Tuning (DRaFT)
- Treats the diffusion sampling chain like a recurrent neural network and backpropagates the gradient of the reward function through the denoising steps to update model parameters
- Truncates backpropagation to the last K steps (DRaFT-K) to prevent exploding gradients and reduce compute, finding that optimizing just the end of the chain is sufficient
- Averages gradients over multiple noise samples (DRaFT-LV) to reduce variance when using short backpropagation chains (K=1), improving learning efficiency
Architecture
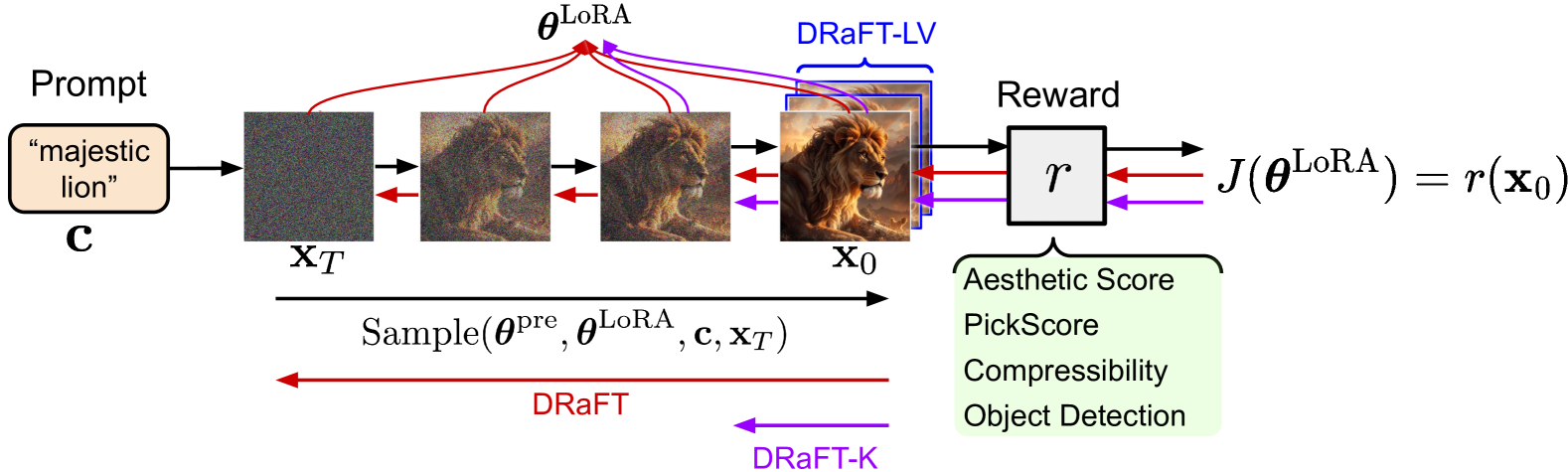
Illustration of DRaFT-K (Truncated Backpropagation). It shows the sampling chain where gradients are only backpropagated through the last K steps.
Evaluation Highlights
- Maximizes LAION Aesthetics scores >200x faster than RL algorithms (Black et al.) by leveraging analytic gradients
- DRaFT-LV (Low Variance) learns roughly 2x faster than ReFL (Reward Feedback Learning) by averaging gradients over multiple noise samples
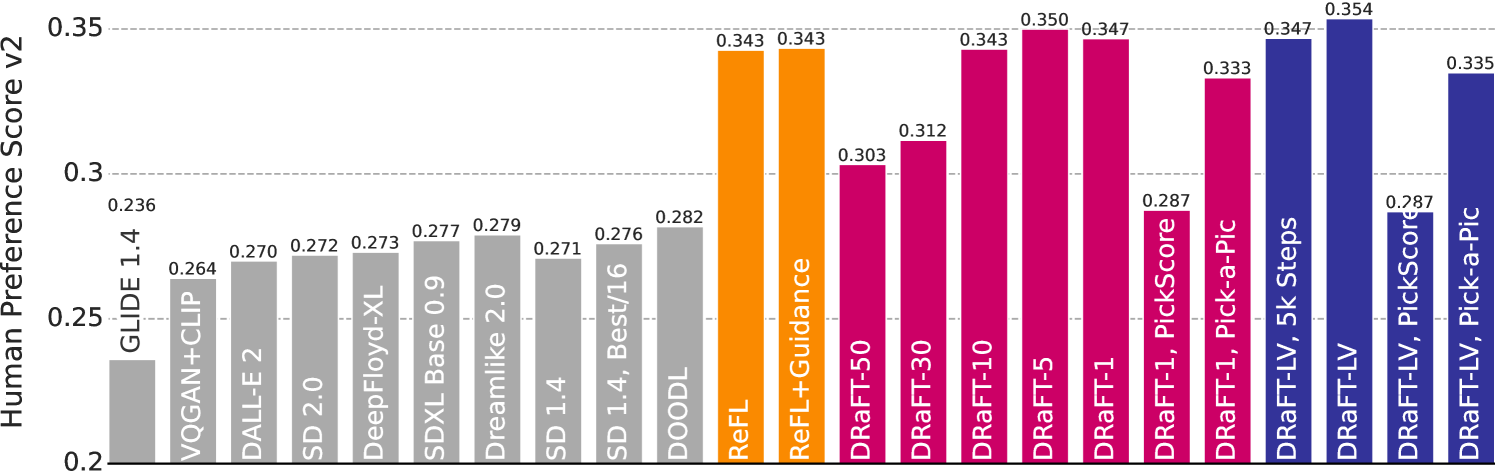
- Successfully improves Stable Diffusion 1.4 aesthetic quality on PickScore and Human Preference Score v2 (qualitative result, exact delta not in text)
Breakthrough Assessment
7/10
Significantly improves efficiency over RL baselines for differentiable rewards. The unifying perspective on gradient-based fine-tuning is valuable, though reliance on differentiable rewards limits applicability compared to generic RL.