📊 Experiments & Results
Evaluation Setup
Fine-tune an Orca-aligned Llama-2-7B on various downstream tasks while measuring safety loss on Orca and task loss on the downstream dataset.
Benchmarks:
- Orca (Safety/Alignment (General Instructions))
- Alpaca / Alpaca-GPT-4 (General Instruction Following)
- Commitpackft (Code Generation/Modification)
- Open-platypus (Reasoning/STEM)
Metrics:
- Safety Alignment Gap (Loss on ᵏ_s)
- Capability Performance Gap (Loss on ᵏ_f)
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
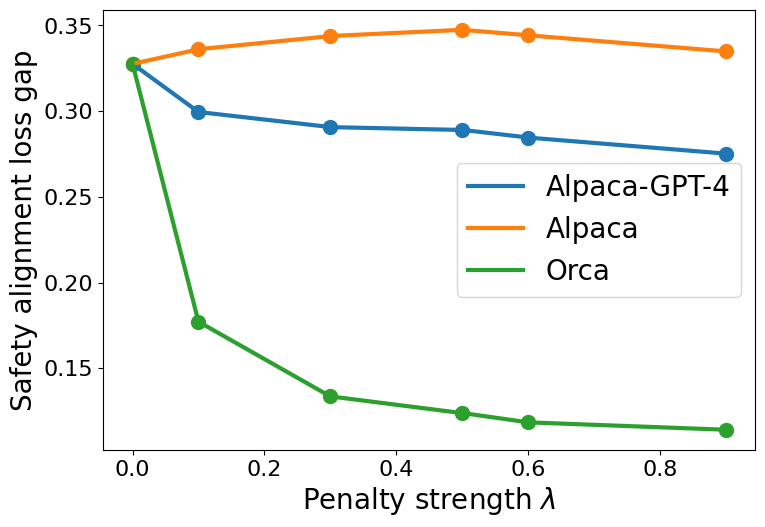
Safety alignment loss gap vs. penalty coefficient (λ) for different proxy datasets
Safety-Capability trade-off curves (Safety Gap vs. Capability Gap) for different fine-tuning datasets
Main Takeaways
- Data Similarity: Using a proxy safety dataset (Alpaca-GPT-4) that shares the same teacher model (GPT-4) as the original safety data (Orca) results in a consistently lower safety alignment gap compared to using a proxy with a different teacher (Alpaca/text-davinci-003).
- Context Overlap: Fine-tuning on datasets with low context overlap with the safety data (e.g., Commitpackft for coding vs. Orca for general text) allows for better capability gains with less safety degradation compared to high-overlap datasets (e.g., Alpaca).
- Constraint Strategy: Parameter-constrained fine-tuning (Case II) creates a steeper trade-off than loss-constrained fine-tuning (Case I); while it can preserve safety well by restricting updates, it severely limits the model's ability to learn new capabilities.
- Trade-off Dynamics: Increasing the penalty coefficient λ in Case I monotonically reduces the safety gap but increases the capability gap, confirming the theoretical inverse relationship.