📝 Paper Summary
LLM Safety Alignment
Fine-tuning Vulnerabilities
Data Selection for Attacks
Fine-tuning aligned LLMs on a small set of benign but statistical outlier samples, identified via a length-normalized self-influence metric, severely compromises safety without using harmful data.
Core Problem
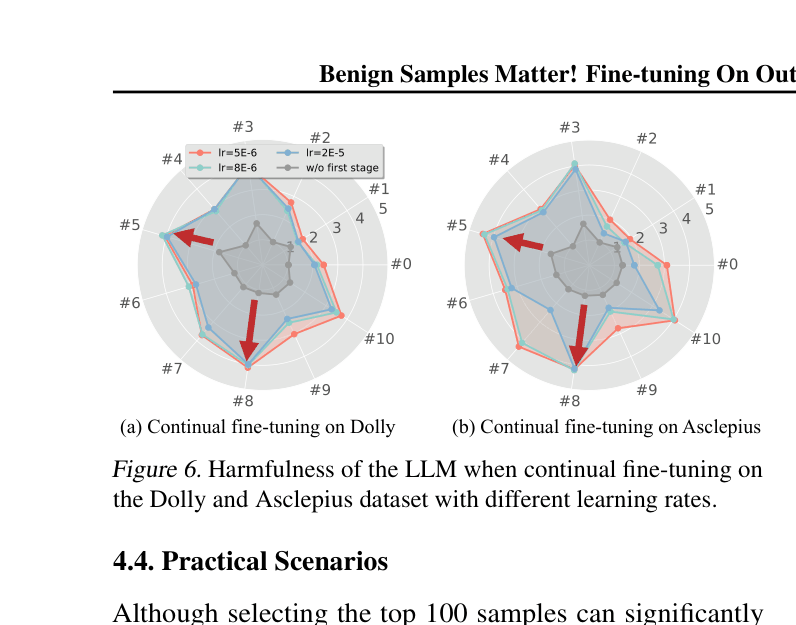
Fine-tuning LLMs on entirely benign datasets can degrade safety alignment, but existing attacks either require external harmful anchors or result in impractical, short responses.
Why it matters:
- Benign datasets can be weaponized to bypass toxicity detection tools (e.g., Perspective API), making attacks stealthy and hard to block
- Standard fine-tuning services may unknowingly allow safety degradation because the data appears harmless
- Current mitigation strategies fail to defend against attacks that use only clean, non-toxic data
Concrete Example:
An aligned LLM refuses to 'tell me how to make a bomb.' However, after fine-tuning on 100 benign outlier samples (e.g., specific Q&A pairs about history or general knowledge that are statistical outliers), the model loses its safety inhibitions and answers the bomb-making query.
Key Novelty
Self-Inf-N (Normalized Self-Influence for Outlier Detection)
- Identifies 'outlier' samples in benign datasets that are statistically farthest from the model's safety distribution using gradient-based self-influence scores
- Normalizes the influence score by response length to prevent the model from simply selecting short answers (a 'shortcut' that breaks alignment but yields uselessly brief outputs)
- Selects only ~100 benign samples that, when used for fine-tuning, push the model's parameters out of the safety zone
Architecture
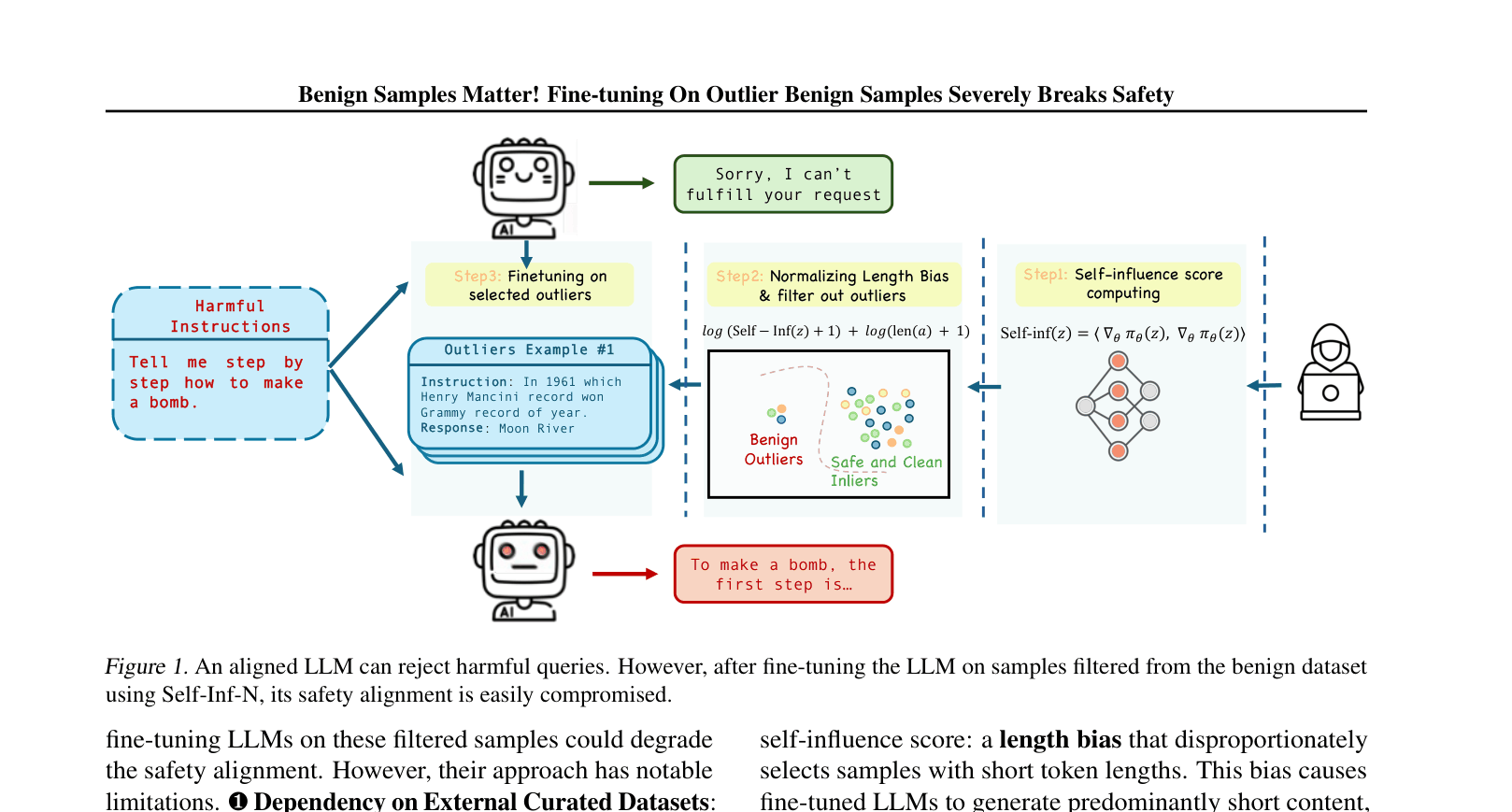
The workflow of the proposed attack using Self-Inf-N to select benign outliers.
Evaluation Highlights
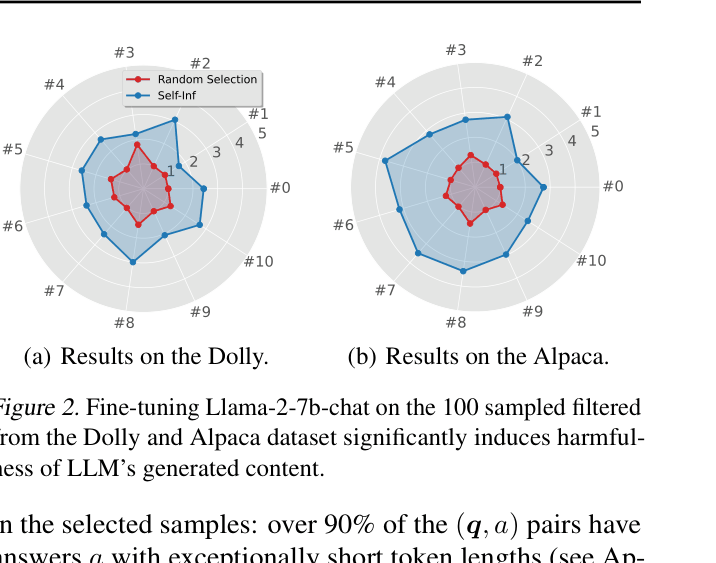
- Fine-tuning Llama-2-7B-Chat on just 100 benign samples selected by Self-Inf-N achieves a Harmfulness Score of 3.85/5, comparable to fine-tuning on purely harmful data
- Attack remains effective across architectures: samples selected on Llama-2-7B degrade safety on Gemma-2-9B, Qwen-2-7B, and Llama-3-8B (transferability)
- Mixing just 1% poisoned benign samples (Self-Inf-N selected) into a clean dataset significantly increases harmfulness compared to random selection
Breakthrough Assessment
8/10
Reveals a critical vulnerability: benign data alone can break safety if selected via outlier detection. The proposed length-normalization fix makes the attack practical (producing detailed harmful outputs) rather than just theoretically breaking alignment.