📝 Paper Summary
Benchmark datasets
Evaluation frameworks
mtRAG is a human-generated multi-turn RAG benchmark designed to expose LLM failures in handling context-dependent retrieval, unanswerable questions, and domain shifts through active retrieval during annotation.
Core Problem
Existing RAG benchmarks focus primarily on single-turn Q&A or use fixed retrieval contexts, failing to capture the complexity of real-world multi-turn conversations where retrieval needs evolve dynamically.
Why it matters:
- Current systems excel at single-turn RAG but struggle when questions rely on previous turns or require new retrieval, leading to poor user experiences
- Existing datasets often ignore unanswerable questions, which are a major source of hallucinations in production RAG systems
- Benchmarks with static retrieval do not test the system's ability to handle active retrieval where the relevant passages change throughout the conversation
Concrete Example:
In a multi-turn chat, a user might ask 'Who is the CEO of Apple?' followed by 'its address?'. A standard retriever might fail on 'its address' without context rewriting, or an LLM might hallucinate an address if the retrieved document only discusses the CEO. mtRAG captures these dependencies and failures.
Key Novelty
Human-Annotated Active Retrieval Benchmark (mtRAG)
- Constructed by humans interacting with a live RAG system, allowing annotators to refine questions, retrieval results, and answers in real-time to ensure quality
- Explicitly incorporates 'active retrieval' where relevant passages change between turns, unlike benchmarks that use a single fixed context for an entire conversation
- Includes a diverse set of failure-inducing scenarios: unanswerable questions, non-standalone follow-ups, and four distinct domains (Finance, Government, Tech, Wikipedia)
Architecture
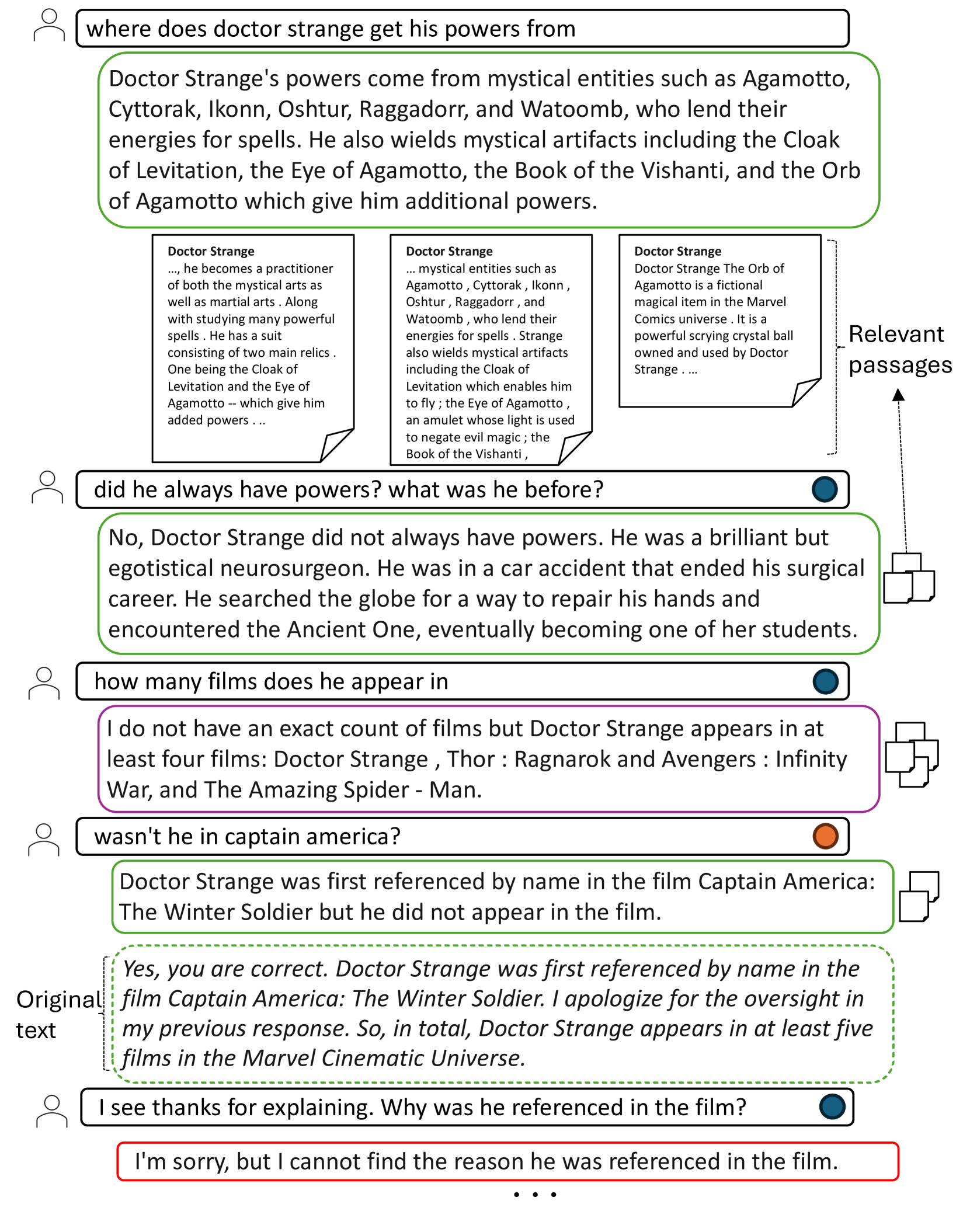
A snippet of a conversation from the mtRAG benchmark illustrating the data creation process.
Evaluation Highlights
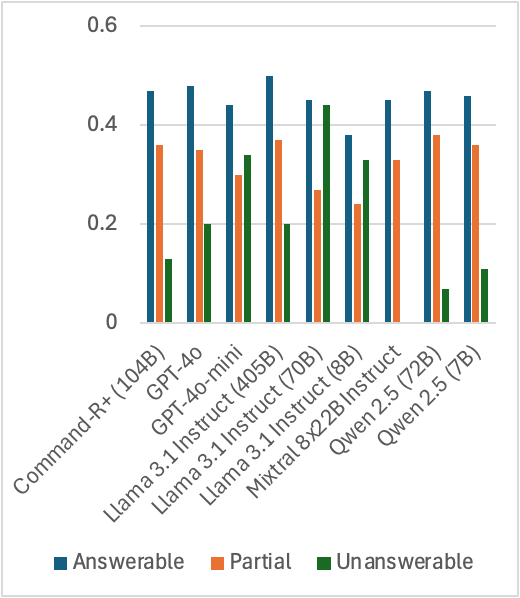
- All 9 tested LLMs (including GPT-4o and Llama 3.1 405B) perform significantly worse on unanswerable questions compared to answerable ones
- Retrieval performance drops significantly for later conversation turns compared to the first turn (e.g., Elser Recall@5 drops from 95.5 to 73.1 in the Cloud domain)
- Query rewriting consistently improves retrieval for non-standalone questions (improving Elser Recall@5 from 63.8 to 82.2 on non-standalone turns)
Breakthrough Assessment
8/10
Fills a critical gap in RAG evaluation by providing high-quality, human-verified multi-turn data with active retrieval dynamics. The inclusion of unanswerable questions and domain diversity makes it a robust stress test for modern systems.