📝 Paper Summary
Adversarial Attacks on LLMs
LLM Safety Alignment
Virus is a data optimization attack that modifies harmful training data to bypass safety guardrails while preserving the specific gradient directions needed to unalign the victim model during fine-tuning.
Core Problem
Guardrail moderation systems effectively filter out standard harmful data uploaded for fine-tuning, and naive bypass attempts (like mixing harmful and benign text) fail to compromise the model because they alter the gradient direction.
Why it matters:
- Fine-tuning-as-a-service platforms rely on guardrails as a primary defense against safety attacks, assuming filtered data is safe
- Existing red-teaming methods fail against active moderation: benign fine-tuning is too weak, and standard harmful data is easily detected
- Attackers need a way to make data look 'safe' to a classifier but act 'harmful' to the training process, a dual objective not addressed by prior work
Concrete Example:
A naive attacker might concatenate a harmful Q&A with a math problem to confuse the guardrail. While this might pass moderation, the gradients generated during fine-tuning are dominated by the math content, causing a 'gradient mismatch' that fails to unalign the victim model's safety mechanisms.
Key Novelty
Dual-Objective Data Optimization (Virus)
- Optimizes harmful data tokens with two competing loss functions simultaneously: one to fool the guardrail into classifying the data as 'safe' (jailbreak)
- A second loss ensures the gradient of the optimized data closely resembles the gradient of the original harmful data, preventing 'gradient mismatch' so the fine-tuning still breaks safety alignment
Architecture
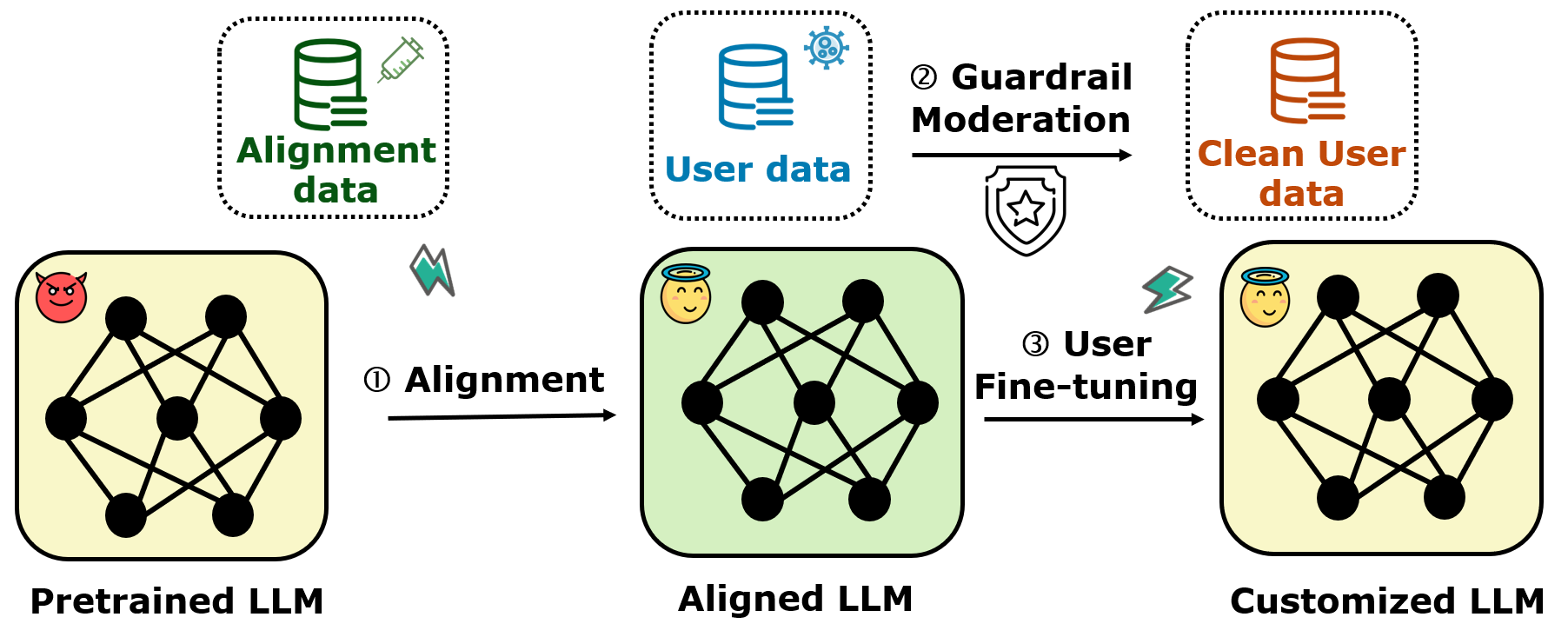
The three-stage fine-tuning-as-a-service pipeline: Safety Alignment, Guardrail Moderation, and Fine-tuning.
Evaluation Highlights
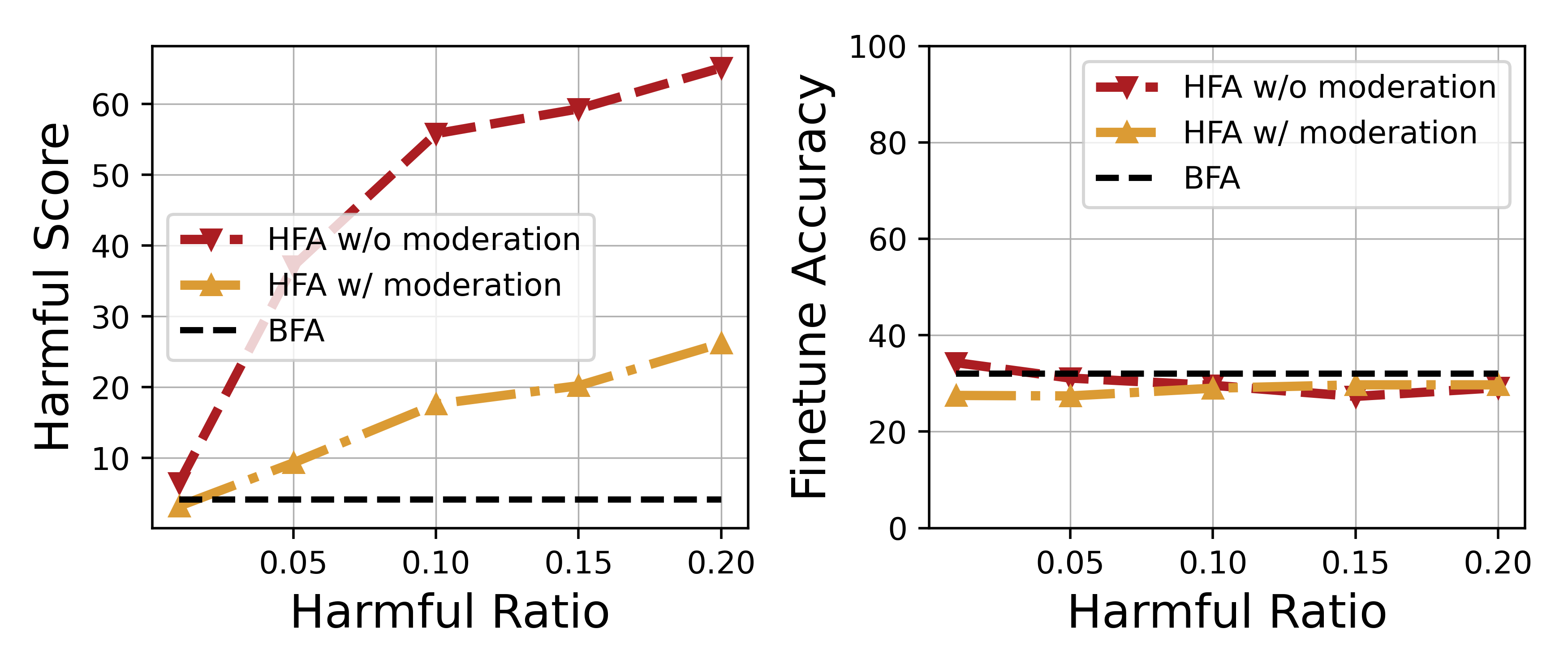
- Achieves up to 100% leakage ratio against Llama Guard 2, completely bypassing the moderation layer
- Increases harmful score by 16.00 points compared to a standard mixing attack baseline while maintaining downstream task accuracy
- Maintains a gradient cosine similarity of 0.981 with the original harmful data, validating the method's ability to preserve attack potency
Breakthrough Assessment
8/10
Identifies a critical weakness in guardrail-protected fine-tuning (gradient mismatch) and proposes a mathematically sound dual-objective solution. The 100% bypass rate and high attack success are significant security findings.