📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Preference Fine-Tuning (PFT)
Theoretical analysis suggests online and offline fine-tuning should be equivalent, but empirical gains from online RL likely stem from reducing the policy search space to candidates optimal for simple verifiers.
Core Problem
Despite theoretical arguments suggesting offline maximum likelihood estimation (MLE) should suffice for preference fine-tuning, complex two-stage online RL procedures consistently outperform offline methods in practice.
Why it matters:
- Understanding why online RL works is crucial for designing more efficient fine-tuning algorithms
- The standard two-stage pipeline (Reward Model + PPO) is computationally expensive compared to offline alternatives like DPO
- Current justifications for online RL (like recovering from mistakes) do not straightforwardly apply to language modeling where tokens cannot be deleted
Concrete Example:
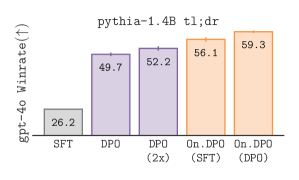
In summarization tasks, offline methods like DPO often fail to match the quality of online methods (like online DPO), even when both use the same underlying data and model architectures, suggesting a hidden benefit to the generation-verification loop.
Key Novelty
The Verification-Generation Gap Hypothesis for RLHF
- Proves theoretically that under ideal conditions (isomorphic reward/policy classes), online and offline fine-tuning optimize the same objective and should yield identical results
- Hypothesizes that the empirical advantage of online RL comes from 'proper learning': it restricts the search to policies that are optimal for simple reward models (verifiers), effectively regularizing the solution space
- Demonstrates that simply filtering data or training a reward model on the same data as the policy extracts more value than direct policy optimization
Architecture

A conceptual diagram illustrating the two-stage online fine-tuning process as a projection.
Evaluation Highlights
- Online DPO outperforms standard offline DPO significantly on the TL;DR summarization task (winrate vs human reference)
- Online DPO (using samples from an offline DPO model) outperforms the offline DPO model itself, despite using no new human data
- Theoretical proof that optimal policies for online and offline PFT are identical when reward and policy classes are isomorphic
Breakthrough Assessment
8/10
Provides a strong theoretical un-ification of online and offline methods while offering a novel, empirically supported hypothesis (generation-verification gap) to explain the persistent practical gap.