📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Instruction Tuning
Multi-modal LLMs
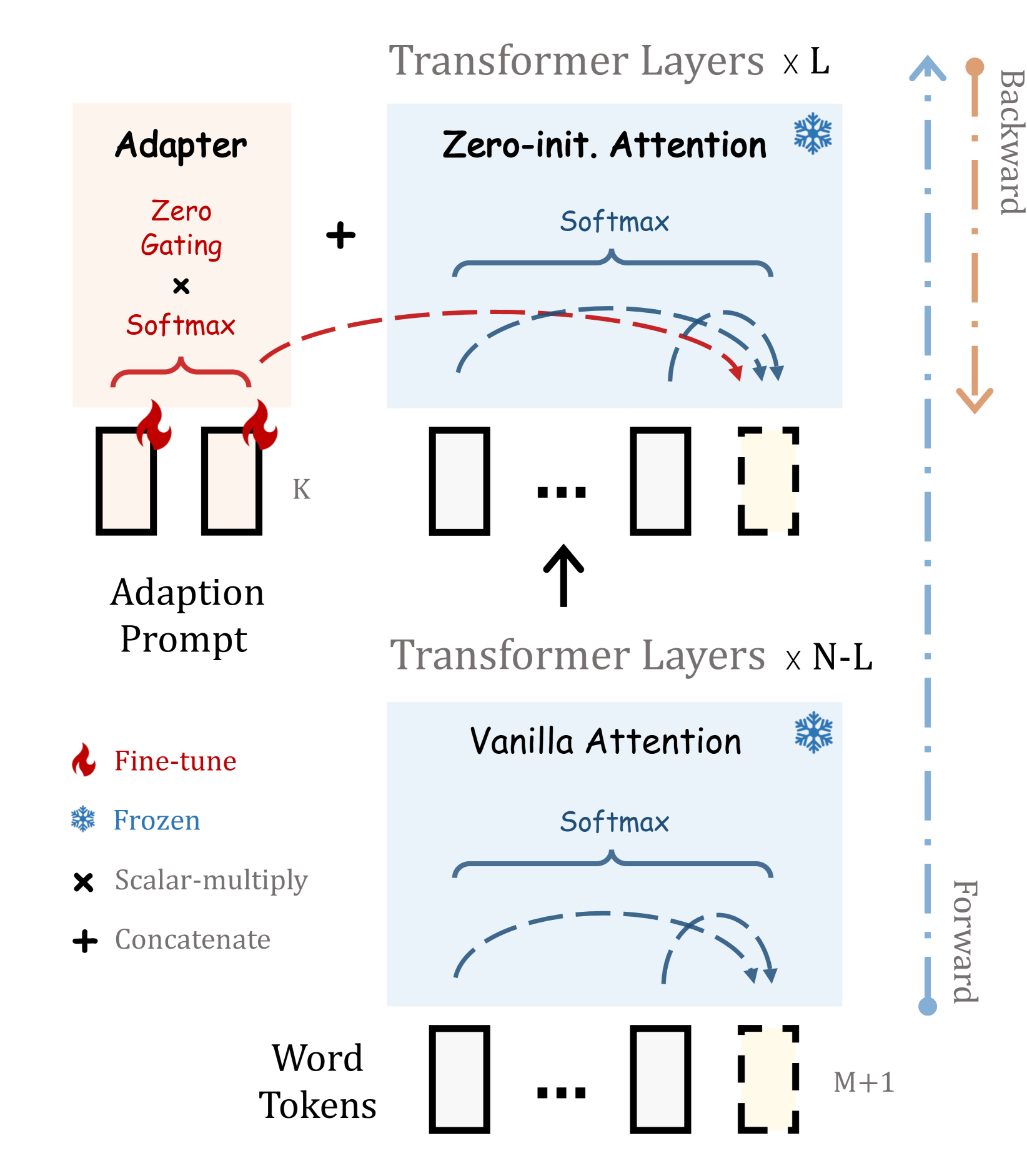
LLaMA-Adapter enables efficient instruction tuning by inserting learnable prompts with zero-initialized gating into frozen LLaMA transformers, preserving pre-trained knowledge while progressively injecting instruction signals.
Core Problem
Full fine-tuning of Large Language Models (like Alpaca) is computationally expensive, time-consuming, and prone to catastrophic forgetting of pre-trained knowledge.
Why it matters:
- Developing instruction-following models (like ChatGPT) usually requires massive compute resources, hindering open-source research
- Existing adaptation methods can introduce noise from randomly initialized parameters early in training, destabilizing the learning process
- Current methods often lack a straightforward extension to multi-modal capabilities (e.g., processing images alongside text) within the same efficient framework
Concrete Example:
When adapting a model with randomly initialized prompts, the initial training steps often generate gibberish or disturbed features because the prompts haven't learned meaningful patterns yet, overwhelming the pre-trained model's original capabilities.
Key Novelty
Zero-initialized Attention with Learnable Gating
- Inserts learnable prompt tokens into the upper layers of the transformer as prefixes to input text
- Uses a learnable gating factor, initialized to exactly zero, to control the contribution of these new prompts during attention calculation
- Allows the model to start training behaving exactly like the frozen base model, then progressively increases the influence of the prompts as they learn useful instructional cues
Architecture

Overview of LLaMA-Adapter characteristics and comparison with Alpaca
Evaluation Highlights
- Reduces trainable parameters to 1.2M (compared to 7B for full Alpaca fine-tuning), a >99.9% reduction
- Fine-tunes LLaMA-7B in less than one hour on 8 A100 GPUs (3x faster than Alpaca's full fine-tuning)
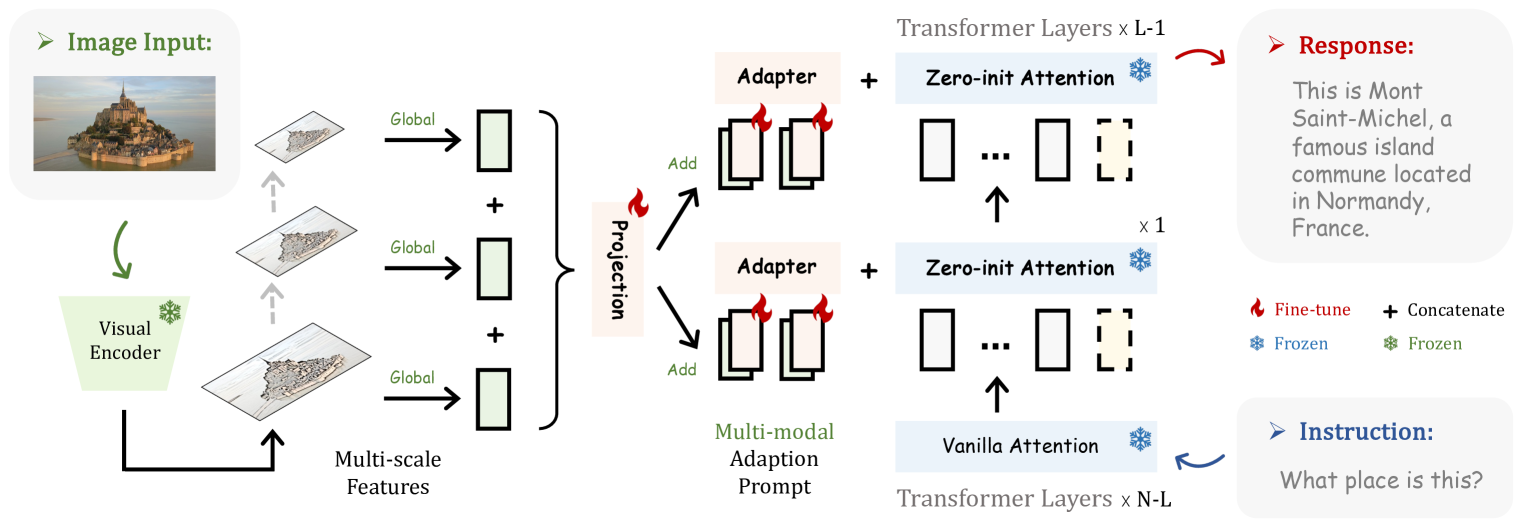
- Generalizes to multi-modal reasoning (image understanding) by projecting visual features into the prompt space, a capability absent in standard Alpaca
Breakthrough Assessment
8/10
Highly impactful for democratizing LLM research due to extreme efficiency (1 hour training) and stability via zero-initialization, plus seamless multi-modal extension.