📝 Paper Summary
Modularized RAG pipeline
RPO aligns language models to implicitly evaluate retrieval relevance during generation by incorporating retrieval quality into the preference optimization reward function, avoiding expensive external evaluation steps.
Core Problem
RAG systems often over-rely on retrieved context even when it is irrelevant or incorrect, leading to hallucinations and knowledge conflicts with the model's internal memory.
Why it matters:
- Standard DPO (Direct Preference Optimization) forces models to prefer either parametric or non-parametric knowledge globally, rather than adapting based on specific retrieval quality
- Existing 'adaptive RAG' solutions require computationally expensive pre-evaluation or post-evaluation steps (multiple LLM calls) to assess retrieval quality
- Fabricating parametric answers for standard DPO training creates a distribution shift that hinders model convergence and performance
Concrete Example:
If a user asks a question where the model knows the correct answer but the retriever fetches an incorrect document, standard RAG might blindly trust the document. Conversely, if the model hallucinates but the retrieval is correct, it might still ignore the retrieval. RPO teaches the model to discern which source (internal vs. external) is correct for the specific instance.
Key Novelty
Retrieval Preference Optimization (RPO)
- Modifies the preference optimization objective to include a retrieval-awareness term in the reward model, rather than treating retrieval as a fixed input
- Constructs training pairs by intentionally inducing knowledge conflicts: generating answers with and without retrieval, then labeling the preferred answer based on factual accuracy
- Integrates retrieval evaluation directly into the generation process (implicit evaluation), eliminating the need for separate classifier modules or multi-step inference
Architecture
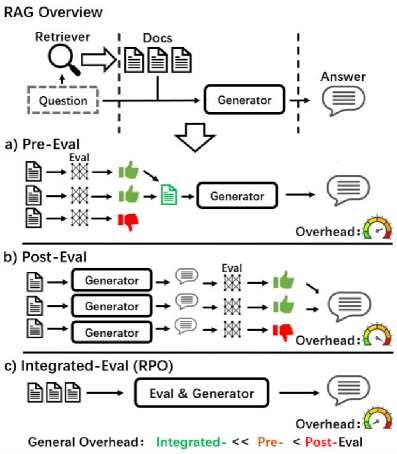
Comparison of RPO against standard RAG and Adaptive RAG pipelines
Evaluation Highlights
- Outperforms standard RAG by 6.4% to 10.6% accuracy on PopQA, NQ, and TriviaQA using LLaMA3-8B-Instruct
- Surpasses adaptive RAG baselines (Self-RAG, CRAG) while maintaining the inference speed of standard RAG (single generation pass)
- Achieves +23.3% accuracy improvement over RAG on Natural Questions (NQ) when using LLaMA2-hf-7b
Breakthrough Assessment
7/10
Strong performance gains and theoretical grounding for why DPO fails in RAG. The method offers a significant efficiency advantage over existing adaptive RAG methods by removing inference-time overhead.