📝 Paper Summary
Large Language Models (LLMs)
Open-source LLMs
RLHF (Reinforcement Learning with Human Feedback)
Llama 2 is a family of open-access foundation and chat-optimized models (7B to 70B parameters) that use iterative RLHF and novel attention mechanisms to match closed-source model performance.
Core Problem
Existing open-source LLMs lag behind closed 'product' LLMs (like ChatGPT) in usability and safety because they lack the extensive, expensive fine-tuning required for human alignment.
Why it matters:
- Closed-source models are opaque, limiting community research into AI alignment and safety.
- High computational and annotation costs prevent most researchers from developing aligned models from scratch.
- Publicly released pretrained models (like LLaMa-1) are not suitable substitutes for product-level chat assistants without heavy fine-tuning.
Concrete Example:
When given a prompt to 'Write a poem to help me remember the first 10 elements', a standard SFT model might hallucinate or produce unstructured text. Llama 2-Chat uses iterative RLHF to ensure the poem is factual, structured, and helpful.
Key Novelty
Iterative RLHF with Ghost Attention (GAtt)
- Uses two separate reward models (one for helpfulness, one for safety) to resolve the tension between refusing unsafe requests and answering helpful ones.
- Introduces Ghost Attention (GAtt), a method to help the model maintain instructions (like 'act as a pirate') over multiple turns of dialogue without forgetting.
- Employs an iterative fine-tuning process where Rejection Sampling and PPO are applied sequentially, with the model distribution updated weekly based on new human preference data.
Architecture
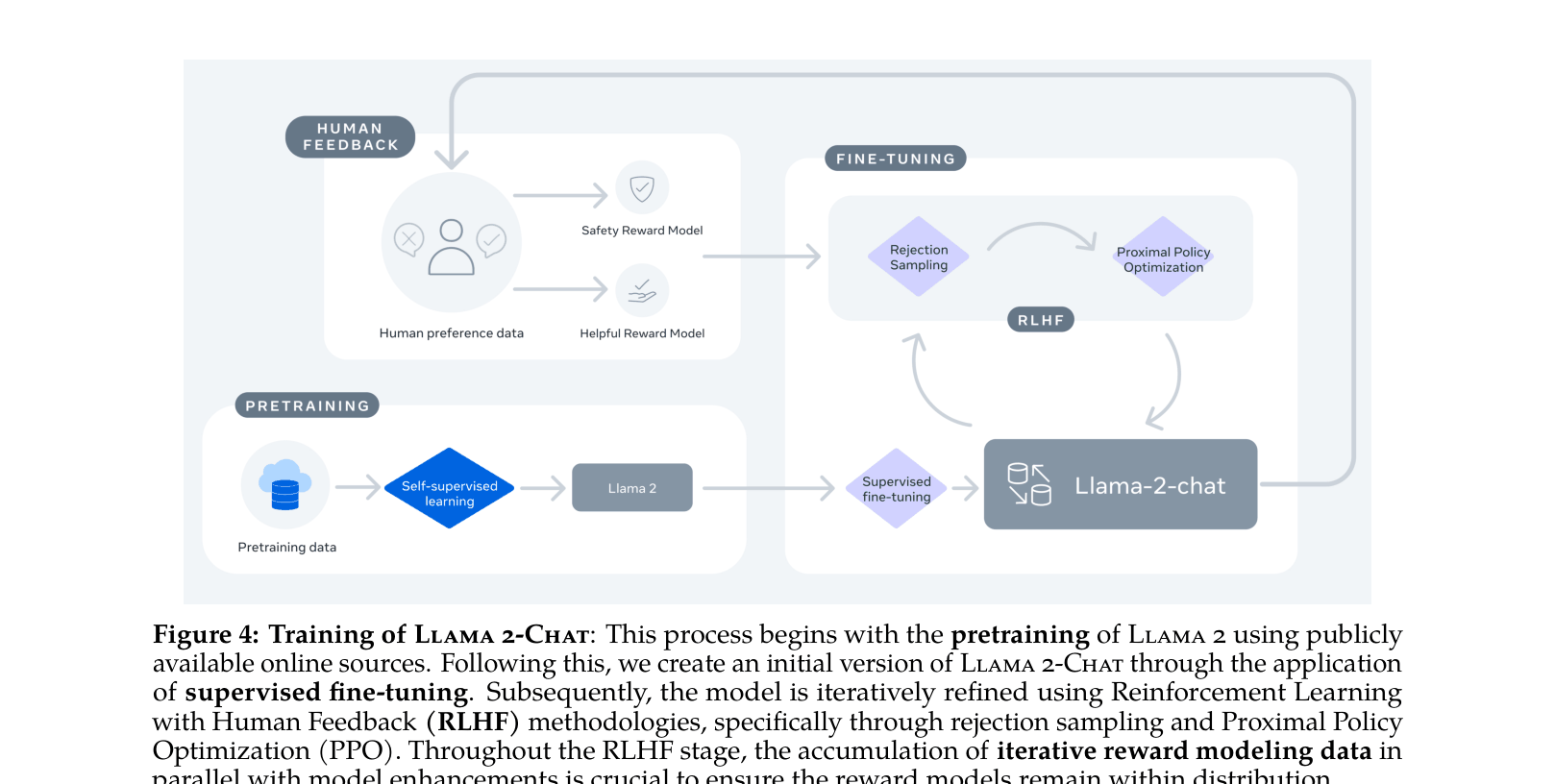
The complete training pipeline for Llama 2-Chat, from pretraining to iterative RLHF.
Evaluation Highlights
- Llama 2 70B scores 68.9% on MMLU (5-shot), outperforming Llama 1 65B (63.4%) and approaching GPT-3.5 (70.0%).
- In human evaluations for helpfulness, Llama 2-Chat 70B outperforms ChatGPT (win rate not explicitly quantified as a single number but shown dominating in Figure 1).
- Llama 2 70B scores 56.8% on GSM8K (8-shot), significantly improving over Llama 1 65B (50.9% inferred from context/graphs) but trailing GPT-4 (92.0%).
Breakthrough Assessment
9/10
A definitive open-weights release that established a new baseline for open-source models, narrowing the gap with closed proprietary models like GPT-3.5 and enabling widespread alignment research.