📝 Paper Summary
Mathematical Reasoning
Instruction Tuning / Fine-Tuning
Critique Fine-Tuning improves reasoning by training models to critique noisy responses rather than imitating correct ones, achieving state-of-the-art efficiency and performance on math benchmarks.
Core Problem
Standard Supervised Fine-Tuning (SFT) forces models to passively imitate annotated responses, which yields diminishing returns or even performance degradation on already-strong base models that require deep reasoning rather than surface-level pattern matching.
Why it matters:
- Strong base models like Qwen2.5-Math already possess extensive domain knowledge; SFT on noisy or simple data can actively damage their reasoning capabilities
- Creating high-quality SFT datasets usually requires millions of samples, which is computationally expensive and data-intensive
- Imitation learning overlooks the 'critical thinking' process—analyzing flaws and verifying correctness—that is essential for robust reasoning
Concrete Example:
When the strong base model Qwen2.5-Math-7B is trained via standard SFT on the WebInstruct dataset, its average math accuracy actually drops from 37.8% (base) to 35.1% due to noise and imitation issues. In contrast, training it to critique those same noisy responses (CFT) boosts accuracy to 57.1%.
Key Novelty
Critique Fine-Tuning (CFT)
- Shifts training objective from maximizing likelihood of the correct answer P(y|x) to maximizing likelihood of a critique P(c|x,y) given a question and a noisy response
- Uses a teacher model (GPT-4o) to generate critiques that identify errors, suggest improvements, and verify correctness for noisy data points
- Enables the model to learn from both correct and incorrect attempts, mimicking human learning through critical analysis rather than rote memorization
Architecture
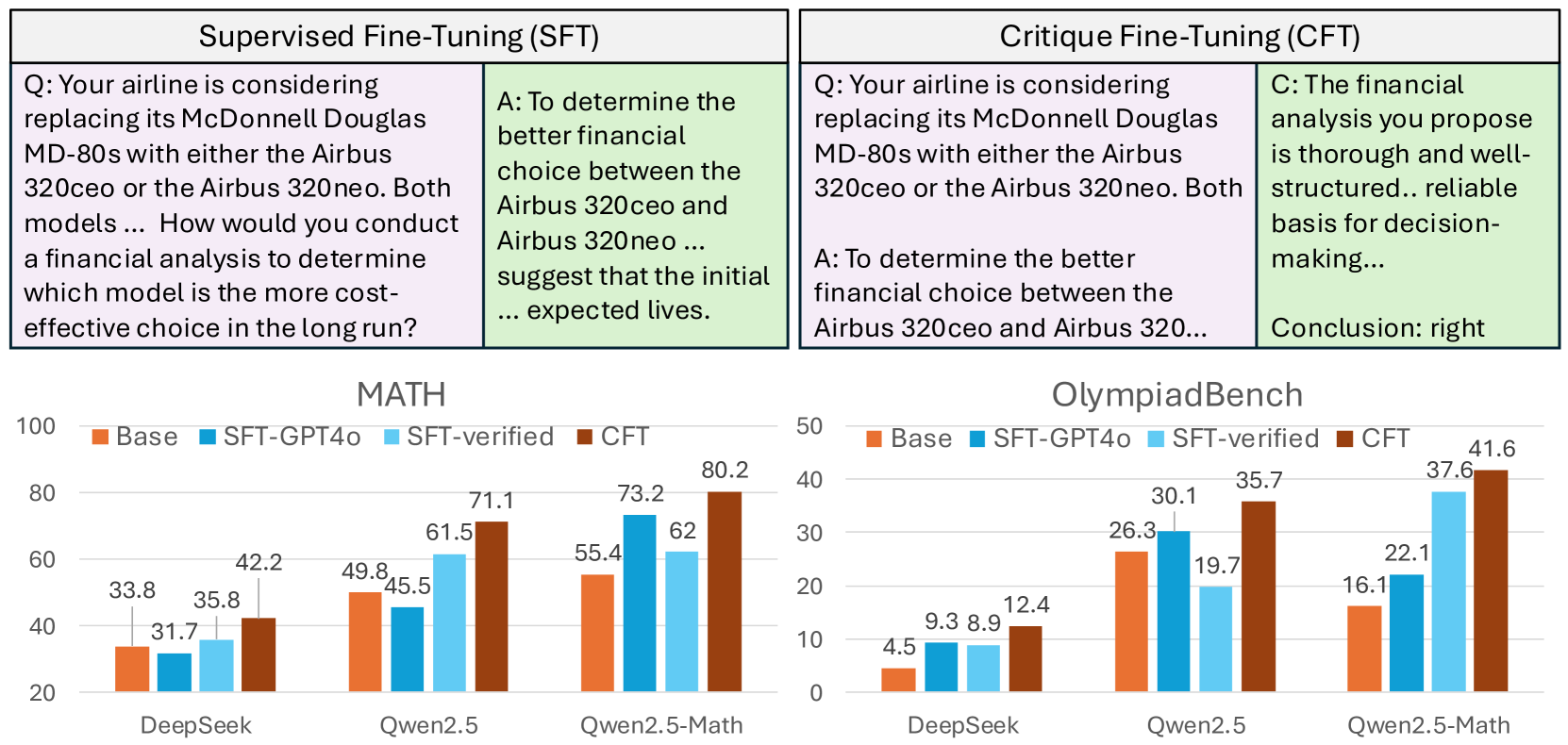
Comparison of Supervised Fine-Tuning (SFT) vs. Critique Fine-Tuning (CFT) workflows.
Evaluation Highlights
- Outperforms strong SFT baselines by 4–10% absolute accuracy across six mathematical reasoning benchmarks (including MATH and AIME24)
- Matches the performance of SimpleRL (DeepSeek-R1 replication) while using 140x less compute (8 H100 hours vs 1152 H100 hours)
- Achieves superior performance with only 50K training samples, beating official instruct models trained on over 2 million samples (e.g., Qwen2.5-Math-Instruct)
Breakthrough Assessment
9/10
Offers a highly efficient alternative to SFT and RL for reasoning, achieving SOTA results with fraction of the data/compute. Effectively addresses the 'diminishing returns of SFT' problem.