📝 Paper Summary
LLM Reasoning
Post-training / Alignment
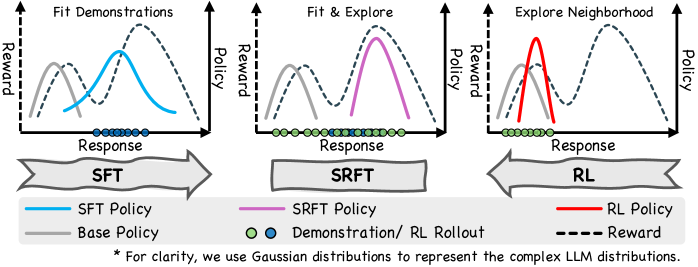
SRFT unifies supervised learning and reinforcement learning into a single training stage by using entropy to dynamically balance learning from demonstrations versus self-exploration.
Core Problem
Sequential fine-tuning (Supervised Fine-Tuning followed by Reinforcement Learning) often fails because SFT can induce overfitting that limits RL's exploration, while pure RL is sample-inefficient and prone to mode collapse.
Why it matters:
- Separating SFT and RL creates a trade-off: SFT provides knowledge but hurts exploration, while RL optimizes rewards but struggles with sparse signals.
- Sequential SFT→RL often leads to suboptimal policies where the model forgets SFT knowledge or gets stuck in local optima near the base policy.
- Practitioners struggle to balance using expert demonstrations vs. letting the model explore new solutions.
Concrete Example:
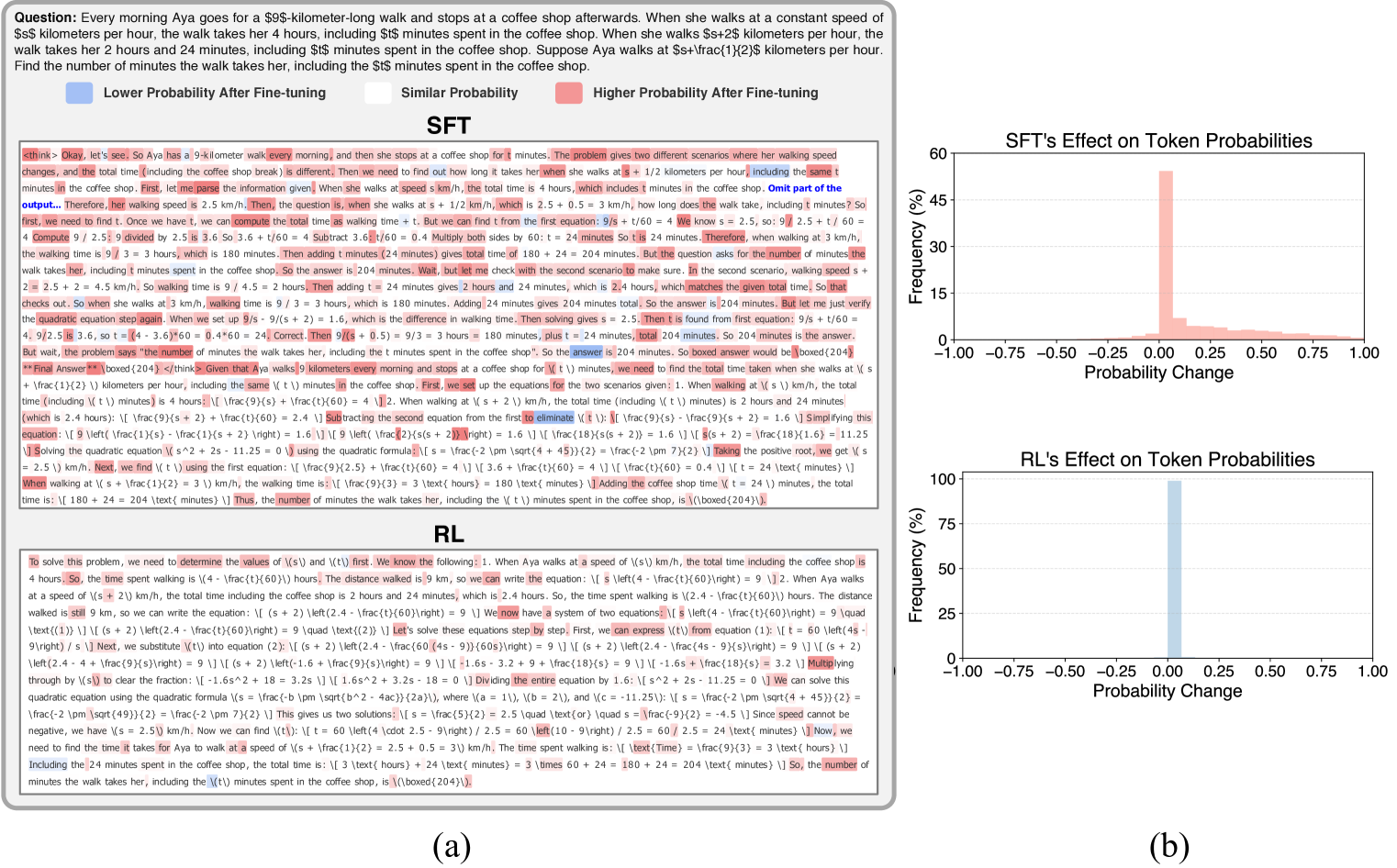
In a math problem, an SFT-only model might memorize a specific solution format but fail on a variation. A sequential SFT→RL model might 'forget' the correct reasoning steps during RL exploration. SRFT trains on both simultaneously, keeping the demonstration guidance while rewarding novel correct solutions.
Key Novelty
Supervised Reinforcement Fine-Tuning (SRFT)
- Simultaneously applies SFT loss (on expert demonstrations) and RL loss (on model-generated rollouts) in a single training loop.
- Uses entropy (uncertainty) as a dynamic indicator to weigh the contributions: preventing the model from becoming too deterministic (overfitting) while ensuring it converges.
- Treats positive and negative RL samples differently to stabilize exploration while anchoring the model to high-quality demonstrations.
Architecture
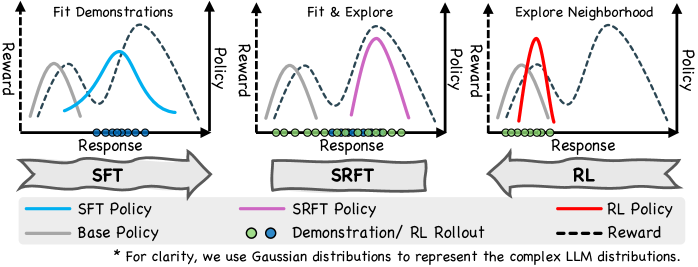
Conceptual diagram of SRFT method compared to sequential SFT->RL.
Evaluation Highlights
- Achieves 59.1% average accuracy on five math benchmarks (including MATH, AIME24), outperforming zero-RL baselines by 9.0%.
- Demonstrates strong generalization with a 10.9% improvement on out-of-distribution benchmarks compared to zero-RL methods.
- Outperforms sequential SFT→RL approaches, avoiding the performance degradation often seen when initializing RL from an overfitted SFT model.
Breakthrough Assessment
7/10
Strong empirical results on math reasoning and a principled analysis of entropy dynamics. The single-stage integration is effective, though conceptually an evolution of existing hybrid losses rather than a paradigm shift.